



Complete Guide to Massive Multitask Language Understanding (MMLU)



What does MMLU stand for?
If you've been tracking the progress of large language models (LLMs) like GPT-4o, Claude 3.5, or Llama 3.1, you've undoubtedly encountered the MMLU score.
It's the four-letter acronym that defines the state of the art in AI, and an increasingly critical metric for developers, researchers, and anyone looking to evaluate the true depth of an AI's general intelligence.
What is MMLU at it's core?
MMLU is a challenging, broad-ranging benchmark designed to assess the multitasking capabilities and general knowledge of a language model.
Introduced by researchers led by Dan Hendrycks in 2020, MMLU was created because earlier benchmarks were becoming too easy for rapidly improving LLMs, leading to "saturation" where models achieved near-perfect scores without demonstrating true, broad intelligence.
Think of MMLU as the AI equivalent of a comprehensive, multi-subject final exam covering everything from high school basics to professional-level expertise.
The MMLU dataset comprises over 15,000 multiple-choice questions across 57 academic and professional subjects.
This vast breadth is what makes the benchmark so effective and difficult to ace.
The subjects are generally grouped into four major categories:
STEM (Science, Technology, Engineering, and Mathematics)
- Includes subjects like Abstract Algebra, High School Chemistry, and Computer Science.
Humanities
- Covers areas such as US History, European History, and Literature.
Social sciences
- Features topics like Psychology, Sociology, and Economics.
Other professional subjects
- Encompasses highly specialised fields such as professional law, professional medicine, and business ethics
The multiple-choice format, typically with four options per question, allows for standardised, objective evaluation of factual recall and deep, applied reasoning across domains.

Zero-shot and few-shot evaluation
A core feature of MMLU is its evaluation methodology, which focuses on generalisation rather than simple task-specific fine-tuning.
Models are primarily tested in two settings:
1. Zero-shot
- The model is given no examples of the task (e.g., history questions) before being asked to answer the test question.
- It must rely entirely on the knowledge acquired during its massive pre-training phase.
2. Few-shot (often 5-Shot)
- The model is given a tiny handful (e.g., five) of correct question-and-answer pairs within the prompt as contextual examples before being asked the final test question.
- This tests the model's ability to adapt and learn from minimal in-context guidance quickly.
Decoding the MMLU score
The MMLU score is reported as a single percentage accuracy across all 57 subjects.
This number represents the fraction of questions the model answered correctly.
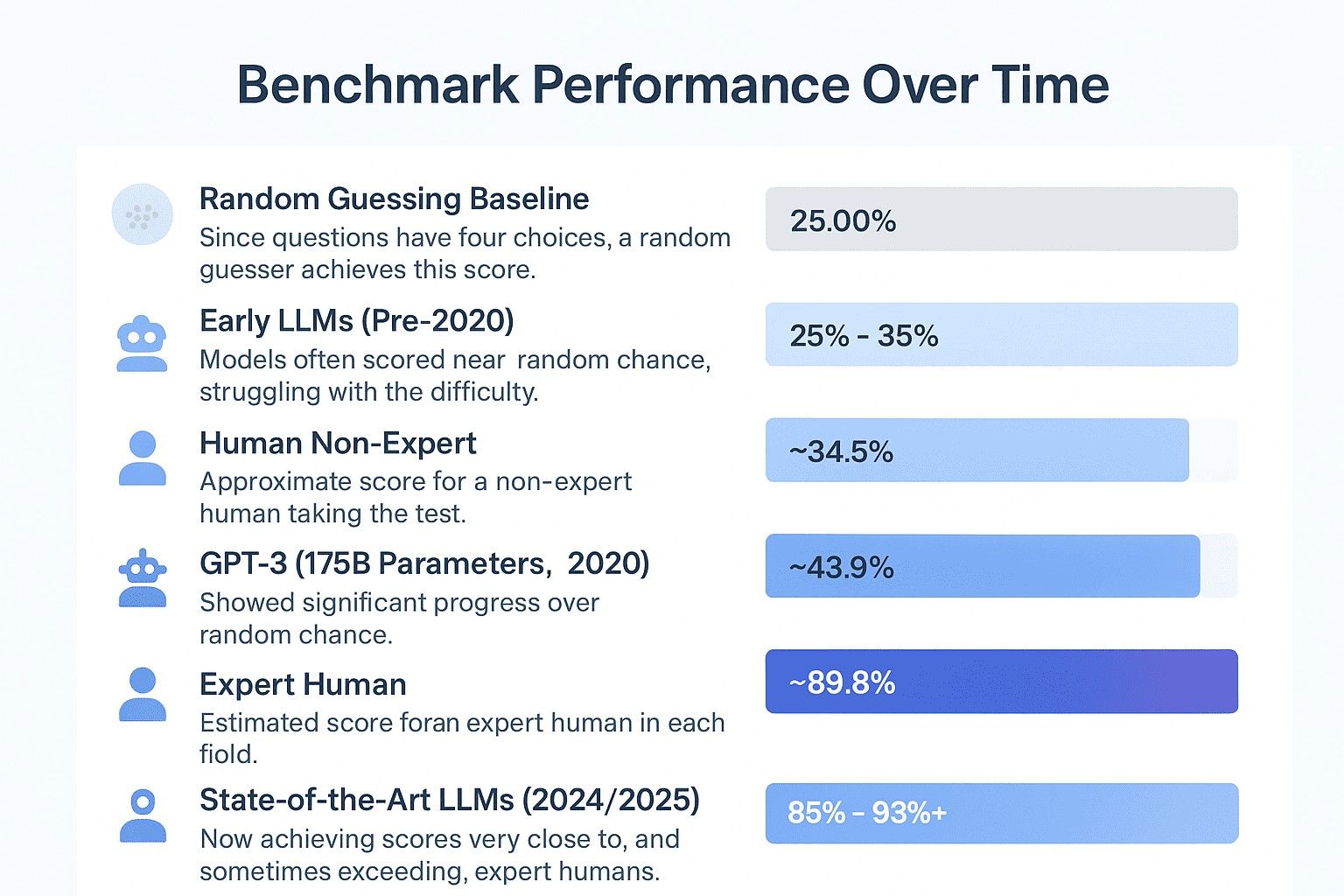
Significance of a high score
A model with a high MMLU score demonstrates capabilities that go beyond simple text generation:
Broad general intelligence
- It suggests the model possesses a wide, cohesive knowledge base, not just specialised skill in one or two domains.
Deep reasoning and comprehension
- It can correctly interpret complex questions, recall relevant information, and perform the necessary multi-step reasoning to select the correct answer.
Adaptability to novel tasks
- Since the evaluation is zero-shot or few-shot, the score confirms the model's ability to generalise its pre-training knowledge to unfamiliar problems.
The impact and importance of MMLU
MMLU has been pivotal in advancing AI research.
It provides a standardized, challenging metric that has become the de facto competitive field for LLM development.
Driving model improvement
The benchmark set a high, clear target for researchers.
Its introduction immediately exposed the shortcomings of even the largest models at the time, demonstrating that a simple increase in model size wasn't enough to solve the problem of broad knowledge and reasoning.
To improve MMLU scores, developers have been forced to:
1. Refine Pre-training data quality
- Ensuring models ingest diverse, high-quality, and factually correct knowledge across all domains.
2) Enhance architectural design
- Developing better mechanisms for knowledge retrieval and logical inference within the model.
3) Implement advanced reasoning techniques
- Utilising methods like Chain-of-Thought (CoT) prompting during evaluation to explicitly walk through reasoning steps, which often yields superior performance on complex problems.
The quest for a perfect MMLU score continues to push the boundaries of what LLMs can achieve in areas requiring deep, general intelligence.
Applications for end-users and businesses
For anyone looking to deploy or utilise an LLM, the MMLU score acts as a vital quality indicator:
Enterprise AI
- A high-MMLU model is better suited for corporate tasks that require domain switching, such as analyzing a legal document, then summarising a financial report, and finally drafting technical specifications.
Education
- An AI assistant with a strong MMLU score can function as a more reliable, multi-subject tutor capable of handling complex academic queries across science, history, and literature.
Content and research
- High scores correlate with reduced factual errors (hallucinations), providing more trustworthy and accurate factual summaries for researchers and content creators.

Challenges with the original MMLU
While MMLU is a cornerstone of LLM evaluation, it's not without its limitations, prompting the community to develop next-generation tests.
Data Contamination
- MMLU dataset has been publicly available for years, there is a risk that some models' pre-training data might have inadvertently included some of the test questions, leading to inflated scores through memorisation rather than true generalisation.
Question Quality
- Subsequent analyses have found a small percentage of questions in the original dataset contain errors, are ambiguous, or have incorrect ground-truth answers, which can slightly compromise the reliability of results.
Focus on Knowledge Recall
- Critics argue that MMLU primarily tests academic knowledge recall, not necessarily skills essential for human-AI interaction, such as creativity, instruction following, common sense, or advanced long-context reasoning.
MMLU-Pro and beyond
To address these shortcomings and keep pace with rapidly improving AI, new, harder benchmarks have emerged:
MMLU-pro
- This enhanced version integrates more challenging, reasoning-focused questions, often drawn from difficult standardised tests.
- It also expands the number of multiple-choice options, significantly lowering the random guessing baseline and increasing the difficulty.
Other multi-task benchmarks
- Datasets like BigBench Hard (BBH) and others focus on even more abstract, synthetic reasoning problems that are highly unlikely to have been seen during pre-training, providing a purer measure of a model's inference capabilities.
These new benchmarks serve to maintain the high bar for AI progress, ensuring that LLMs are continually pushed toward achieving human-level or super-human performance on increasingly challenging, real-world tasks.
Leveraging the MMLU Score
Whether you're an AI enthusiast, a developer, or a business leader, here's how to apply your understanding of the MMLU benchmark:
To choose an LLM:
- Always check a model's MMLU score on public leaderboards (e.g., Hugging Face Leaderboard).
- A higher score is a strong proxy for general reliability, factual accuracy, and broad applicability.
Fine-tuning models:
- If you are customising an existing LLM for a wide-ranging application (like an internal knowledge base or a multi-subject educational tool), use MMLU and its sub-sections (e.g., Professional Law) to measure the success of your fine-tuning.
- A successful intervention should show an uptick in the corresponding MMLU subject score.
For interpreting AI news:
- When a new state-of-the-art model is announced, its MMLU score is the single most important, standardised number to look for.
- Use it to compare new models directly against established systems to gauge genuine progress.
The MMLU benchmark remains the clearest measure of a language model's breadth of knowledge and reasoning capacity.
As AI continues its rapid evolution, MMLU will continue to be the essential metric guiding the path toward building truly intelligent and versatile machines.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us