



What is Retrieval-Augmented Generation (RAG)?


Large language models (LLMs) like GPT and Gemini have captured our imagination with their incredible ability to generate human-like text, answer questions, and even write code. But if you've ever used them, you've probably encountered their biggest weaknesses: they can invent information, or "hallucinate," and their knowledge is limited to the data they were trained on, which is often out-of-date.
For businesses and professionals, these limitations can be a deal-breaker. You can't rely on a chatbot for customer support if it might give a customer incorrect information about their order history. You can't use an AI assistant for legal research if it invents legal precedents. This is a common pain point for anyone trying to apply this powerful technology to real-world, knowledge-intensive tasks.
The solution is a framework called Retrieval-Augmented Generation, or RAG. Think of RAG as giving an LLM a personal librarian. When you ask a question, the LLM's "librarian" first goes out and finds the most relevant, up-to-date information from a trusted knowledge base. The LLM then uses that retrieved information to create a final, well-informed answer. It's a method that combines the creative power of a generative model with the factual grounding of a search system.
What is Retrieval-Augmented Generation (RAG)?
At its core, RAG is a method for enhancing the performance of large language models by giving them access to external knowledge sources. Instead of relying solely on the information encoded in their training data, RAG enables LLMs to look up specific, relevant information from a separate, trusted data repository and use that information to formulate a response.
This process consists of two main components:
Retrieval: The system searches for and retrieves relevant information from a knowledge base. This knowledge base can be a collection of internal company documents, a database of product specifications, a private library of research papers, or even a specific set of web pages.
Generation: The retrieved information is then given to the LLM along with the user's original query. The LLM uses this combined input to generate a comprehensive and accurate answer, citing or referencing the retrieved sources as needed.
This simple yet powerful approach provides a pathway for LLMs to go beyond their static training data. It allows them to access new, domain-specific, or proprietary information, making them far more useful and reliable for practical applications.
How RAG Works: A Step-by-Step Breakdown
To truly understand RAG, let’s break down the process into its three key stages: data preparation, retrieval, and generation.
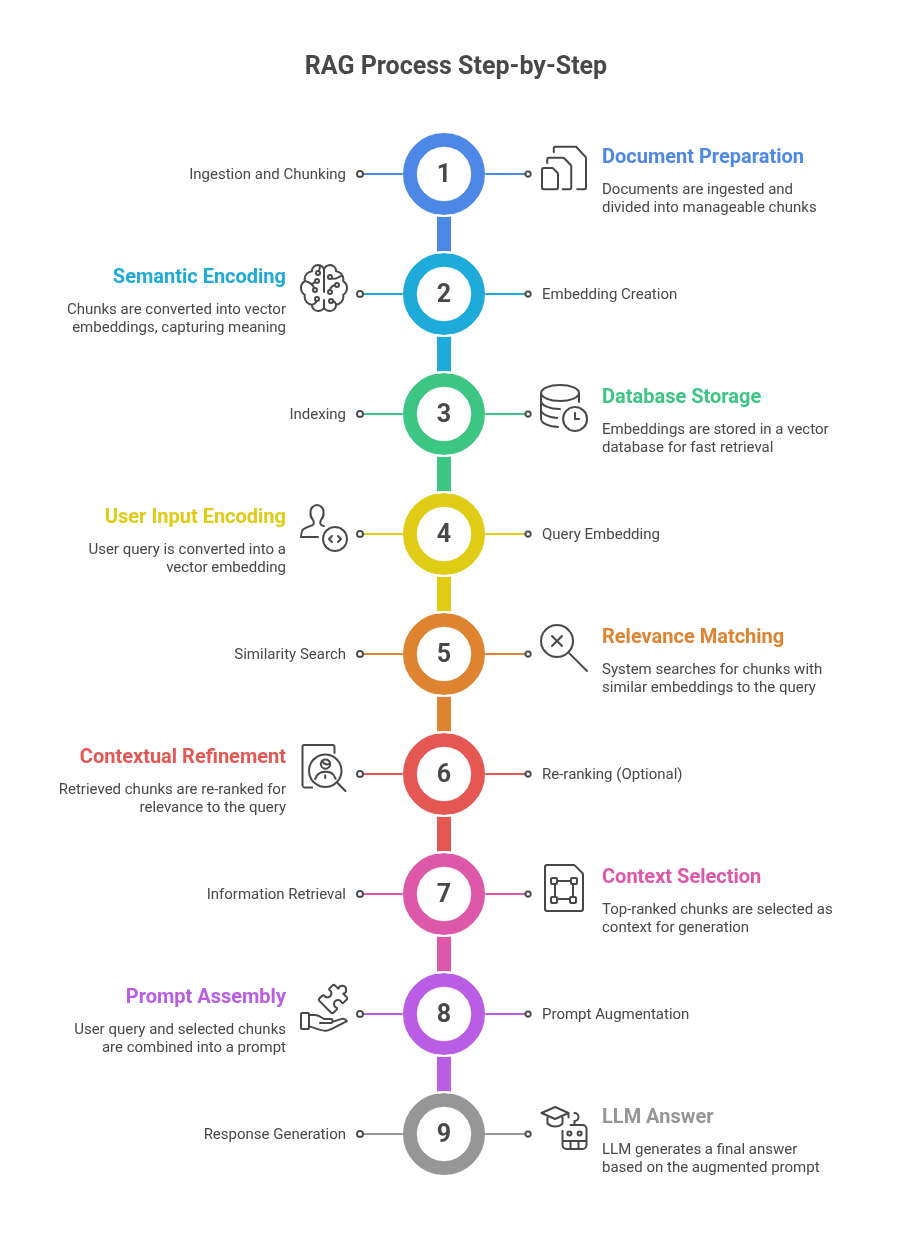
1. Data Preparation (The "Librarian's Catalog")
Before the system can retrieve anything, the knowledge base must be organized in a way that allows for fast and accurate searching. This is where the magic of vector databases comes in.
Ingestion and Chunking: First, your documents (PDFs, text files, web pages) are ingested into the system. They are then broken down into smaller, manageable pieces, or "chunks." A chunk could be a paragraph, a sentence, or a section, depending on the strategy. This is important because it ensures that the retrieval system only finds the most specific, relevant pieces of information, rather than sending a massive, unhelpful document to the LLM.
Embedding Creation: Each chunk is then converted into a numerical representation called a vector embedding. This is done using a specialized model known as an embedding model. These embeddings capture the semantic meaning of the text. Think of them as coordinates on a map of concepts, where similar ideas are placed closer together. For example, the embedding for "dogs" would be very close to the embedding for "canines."
Indexing: All these vector embeddings are stored in a vector database. This database is specifically designed for performing lightning-fast similarity searches.
2. Retrieval (Finding the Right Books)
When a user submits a query, this stage kicks into action.
Query Embedding: The user's query is also converted into a vector embedding using the same embedding model.
Similarity Search: The system performs a search in the vector database to find the chunks whose embeddings are most similar to the query's embedding. This means it finds the pieces of information that are semantically most relevant to what the user is asking.
Re-ranking (Optional but Recommended): For more advanced systems, the retrieved chunks can be sent to a re-ranker model. This model analyzes the context of the user's query and the content of the retrieved chunks to score them based on relevance, ensuring that the most helpful results are at the very top.
Information Retrieval: The top-ranked chunks are selected as the "context" for the next step.
3. Generation (Writing the Answer)
This is the final step, where the LLM does its job.
Prompt Augmentation: The user's original query and the retrieved, contextually relevant chunks are combined into a new, augmented prompt. The prompt essentially tells the LLM: "Here is a user's question, and here is some information that might help you answer it. Please use only this information to give a clear and accurate response."
Response Generation: The LLM processes this augmented prompt and generates a final answer that is grounded in the provided context. Because the LLM is guided by the retrieved information, it is far less likely to hallucinate or invent facts.
Key Benefits of Using RAG
RAG isn't just a technical trick; it addresses fundamental problems with using LLMs for real-world tasks. Here are its most significant advantages:
1. Reduces Hallucinations and Improves Accuracy:
- By grounding the LLM's responses in verifiable data, RAG significantly lowers the risk of the model inventing information.
- This makes RAG-powered applications far more reliable for use cases where accuracy is non-negotiable, such as legal, medical, or financial domains.
2. Incorporates Up-to-Date Information:
- LLMs are only as current as their last training cycle. RAG circumvents this limitation by connecting the model to information that can be updated continuously without retraining the entire model.
- You can add new documents to your knowledge base, and the RAG system will use them immediately. This is a game-changer for industries that rely on the latest information, like news, market data, or research.
3. Enhances Transparency and Trust:
- RAG systems can be designed to provide source citations for the information they use.
- This transparency builds user trust and allows them to verify the information for themselves, moving away from the "black box" nature of some AI systems.
4. Maintains Data Privacy and Control:
- For organizations with sensitive or proprietary information, RAG is a great solution. The private data stays within the organization's control, separate from the public-facing LLM.
- The LLM never sees or stores the private information, it only processes it for the duration of the query. This is a major advantage over methods that require you to upload and train on private data.
5. Cost and Time Efficiency:
- The cost and time required to train or fine-tune an LLM on a new, large dataset are considerable. RAG allows you to achieve many of the same benefits—like using domain-specific knowledge—without the need for expensive and lengthy model retraining. You simply add the new data to your vector database.
RAG vs. Fine-Tuning: Which is Right for You?
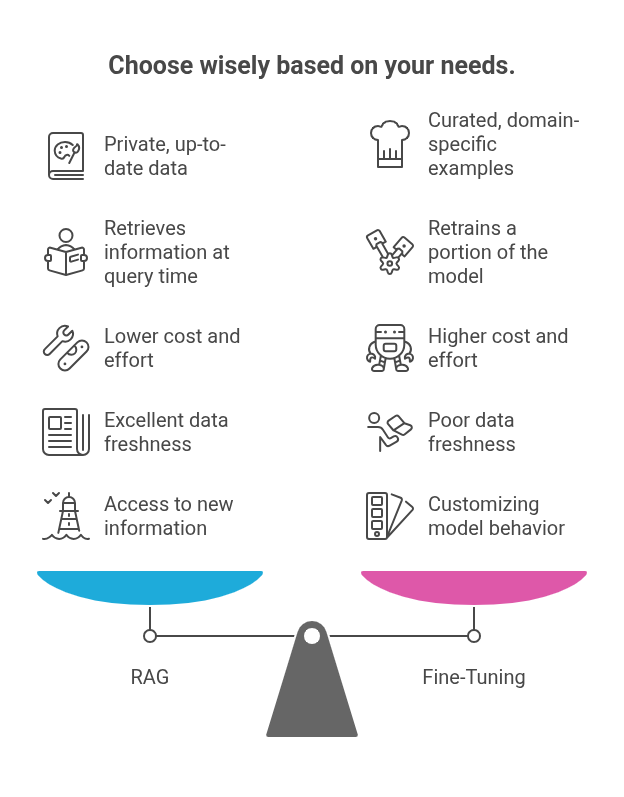
When you want to customize an LLM with your own data, the two most common approaches are RAG and fine-tuning. While they can be used together, they serve different purposes.
The choice between RAG and fine-tuning depends on your specific needs. If your goal is to provide a chatbot with access to your company's latest product manuals, RAG is the clear choice. If you want to train an LLM to write marketing copy in your brand's unique voice, fine-tuning is likely better. In many cases, a combination of both is the most effective approach.
Practical Applications and Real-World Examples
RAG is not just a theoretical concept; it's being used to create sophisticated AI applications across many industries.
1.Enterprise Search and Knowledge Management:
- Imagine an internal chatbot for a large company. Employees can ask it questions about HR policies, IT guidelines, or project documentation.
- The RAG system retrieves the answers from a database of company documents, providing accurate and quick responses without a person having to manually search through a dozen different portals.
2. Customer Support and Service:
- Chatbots powered by RAG can access a company's entire knowledge base, including product manuals, user forums, and technical support tickets.
- This enables the bot to give specific, helpful answers to customer inquiries, from troubleshooting a technical issue to explaining a billing discrepancy.
3. Medical and Legal Research:
- For professionals in fields with vast amounts of information, RAG can be a powerful assistant. A lawyer can use a RAG system to query thousands of legal cases and statutes, getting a summary of relevant precedents.
- A doctor can retrieve the latest information on a specific condition from a database of medical journals, helping them stay current with new research and treatment options.
4. Education and Learning:
- RAG can create more engaging and effective educational tools.
- A student can ask questions about a textbook, and the system can provide answers grounded in the textbook's content, complete with citations to the relevant page numbers.
5. Content Creation:
- A writer can use a RAG system to research a topic.
- The system can pull relevant facts, statistics, and sources from a curated knowledge base, providing the writer with the factual grounding they need to craft a well-informed article.
Common Challenges with RAG Implementation
While RAG is a powerful technique, it's not without its challenges. Implementing a RAG system requires careful consideration and planning to get the best results.
Data Quality is Paramount: The old adage "garbage in, garbage out" holds true. If your source documents are poorly organized, incorrect, or incomplete, the RAG system will struggle to provide accurate answers.
Choosing the Right "Chunking" Strategy: Deciding how to break down your documents is an art. Too large, and the retrieved information might contain irrelevant details that distract the LLM. Too small, and you might lose important context, leading to incomplete answers.
Handling Ambiguous Queries: Users don't always ask perfectly clear questions. A query might be vague, contain multiple sub-questions, or use a different vocabulary than your documents. This can lead to the retrieval system finding irrelevant or unhelpful information.
Managing Performance and Cost: While RAG avoids the heavy cost of retraining, it adds computational overhead to every query. The system must perform a search in the vector database and then pass a larger prompt to the LLM. For applications with high query volume, optimizing this process is crucial.
The Future of RAG and AI Search
RAG is a foundational technology for a new generation of AI applications. As search engines and AI assistants become more intertwined, RAG techniques will continue to evolve. We'll see improvements in hybrid search (combining keyword and vector search), more intelligent ways to structure data, and multi-modal RAG systems that can retrieve and generate information using text, images, and audio.
By combining the retrieval of specific facts with the generative power of LLMs, RAG bridges the gap between a simple search engine and a knowledgeable assistant. It's not about replacing human intelligence but about augmenting it with accurate, contextual, and up-to-date information, making it an indispensable tool for anyone who needs to find and use information with confidence.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us