



What are Vision Language Models: A Complete Guide



What Are Vision Language Models?
Vision Language Models (VLMs) are AI architectures that combine the strengths of computer vision and natural language processing. They learn to connect visual content (images, videos) with text, allowing them to generate descriptions, answer questions about images, search visual databases using captions, and perform much more. Unlike standard models that only handle either text or images, VLMs are “multimodal,” meaning they align and process both types simultaneously.
How Vision Language Models Work: Under the Hood
Vision Language Models (VLMs) are special AI systems that can understand both pictures and words together. They work by first turning an image into patterns that a computer can read, and turning text into word meanings.
Then, these two pieces of information are connected so the AI can link what it sees with what it reads. For example, if a model sees a picture of a dog and the word “dog,” it learns to match them. Over time, with lots of practice on huge sets of images and captions, the model becomes good at describing pictures, answering questions about them, or even reasoning about what is happening in an image.
Inside, the model pays attention to the right parts of an image and the right words, so it can understand them together in context. This makes VLMs powerful tools for tasks like image search, captioning, and smart assistants that can “see and talk” like humans.
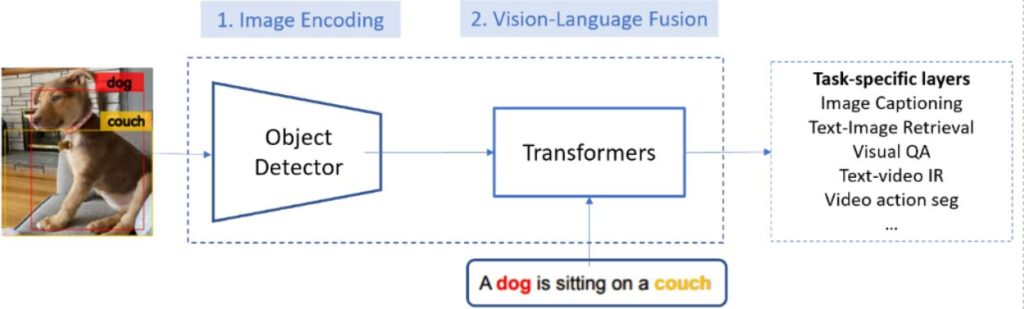
Core Components
Vision Encoder Typically a Convolutional Neural Network (CNN) or Vision Transformer (ViT), extracts features such as objects, colors, and shapes from visual data.
Language Encoder Often a large language model, like BERT or GPT, encodes sentences, phrases, and their meaning as vectors.
Fusion Mechanism Combines and aligns visual and textual representations using attention, co-attention, or joint embedding techniques.
Training Techniques in Vision Language Models
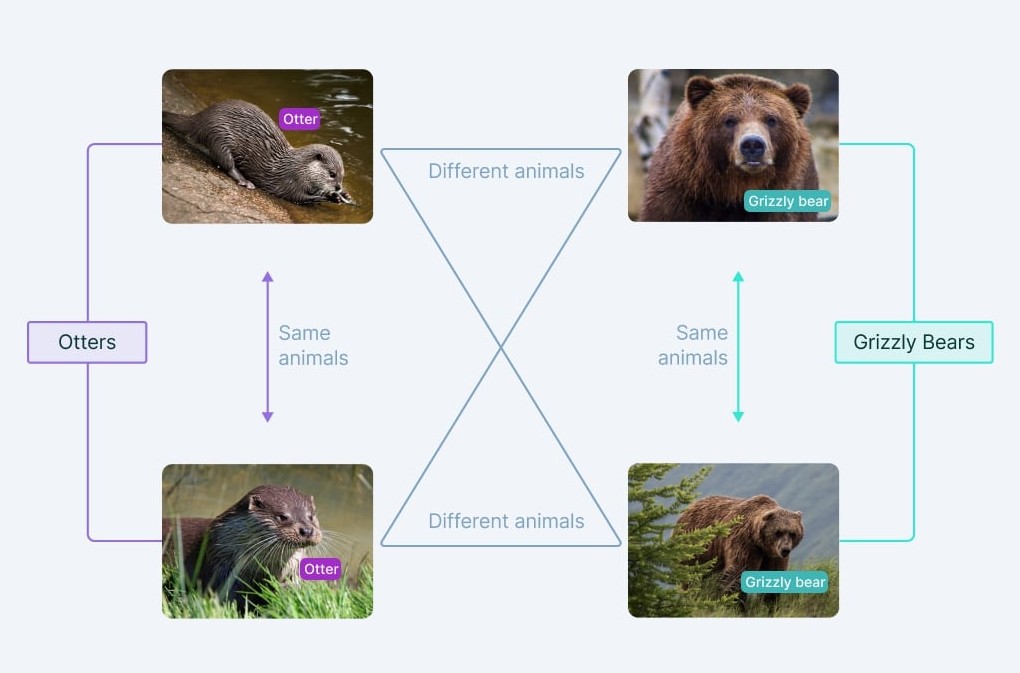
1. Contrastive learning
Contrastive learning is a technique that helps a Vision Language Model understand which images and texts relate to each other. The idea is to make the representations of a matching image-text pair more similar, while ensuring non-matching pairs are far apart in the learned feature space. For instance:
Example: In models like CLIP or ALIGN, thousands or millions of images and their captions are used to train the network. If a photo of a golden retriever with the caption "A golden retriever playing in the grass" is shown, the model’s goal is to pull the image and the correct caption together, while pushing away unrelated captions or images.
Benefits: This approach allows the model to generalize to new combinations, like answering questions about previously unseen objects or recognizing objects based solely on textual description.
How it works: During training, for each image-text pair, the model computes similarity scores for all possible matches in the batch. The loss function (often InfoNCE loss) penalizes the model unless the correct pair ranks highest.
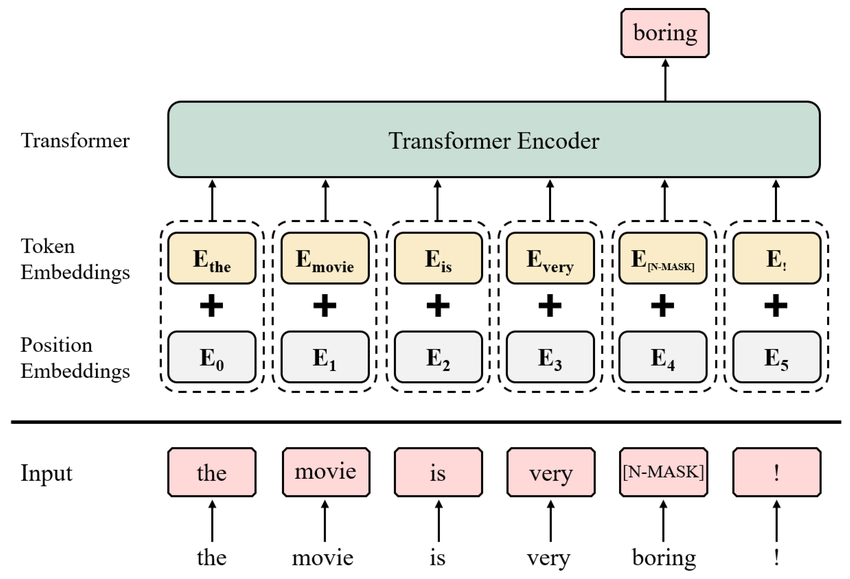
2. Masked Modeling
Masked modeling builds on the idea of learning by hiding parts of the data and asking the model to predict what’s missing:
For Text: Language models like BERT randomly hide (mask) some words in a sentence and the model is trained to predict what the masked words are.
For Images: The equivalent for vision is to mask out regions or patches in an image. The model then has to infer what’s in the missing part, using context from the visible regions.
For Vision-Language Models: Both the image regions and text tokens may be masked, and the model must learn to infer masked parts across modalities. For example, in VisualBERT or ViLBERT, the model might need to guess a masked noun by analyzing both the image and the rest of the caption.
Advantage: This leads to better feature learning, teaches context, and improves the model’s ability to “fill in the blanks” for both images and language.
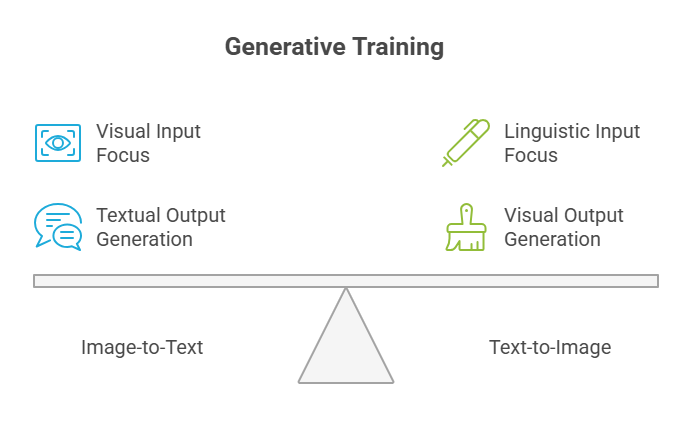
3. Generative Training
Generative training enables models to produce content in one modality based on another:
Image-to-Text: The model views an image and generates a descriptive caption, as in image captioning (e.g., BLIP, OSCAR).
Text-to-Image: The model receives a written instruction (prompt) and generates an image that matches the description (e.g., DALL-E, Stable Diffusion).
How it works: Architectures like encoder-decoder models first encode the input (image or text), then use a decoder to generate the output in the other modality. Training involves large paired datasets, with loss functions measuring the difference between generated content and ground truth.
Impact: This approach underpins many creative and assistive AI applications.
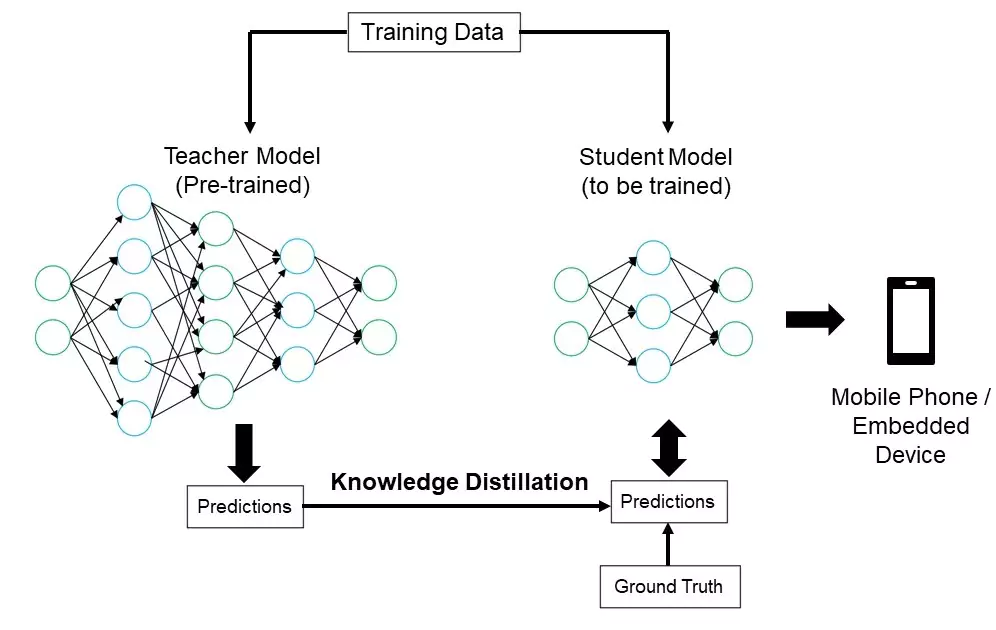
4. Knowledge Distillation
Knowledge distillation involves transferring the capabilities of a large, complex “teacher” model to a smaller “student” model:
Why: Large models achieve high performance but can be computationally expensive.
How: The student model is trained to mimic the outputs (logits, probabilities, features) of the teacher across many examples.
Applications in VLMs: The process is used to compress VLMs, making them faster and more suitable for deployment in environments with limited resources (such as mobile devices or web browsers).
Result: Student models retain much of the accuracy of larger variants but require less memory and computation to run.
Examples of Popular Architectures
CLIP (OpenAI): Trains on pairs of images and captions, achieving high accuracy in zero-shot tasks.
ViLBERT: Uses two parallel encoders for text and image, connected by co-attention layers.
FLAVA, VisualBERT, LLaVA, Gemini 2.0, GPT-4o: Each explores different fusion or pretraining strategies.
Key Challenges and Limitations
Model Complexity Handling both images and text increases training difficulty and resource needs, making deployment on devices with less compute power challenging.
Dataset Bias VLMs trained on web data can inherit social, cultural, or visual biases.
Evaluation Difficulties Different descriptions or interpretations of the same image can cause inconsistencies in scoring. Example: “A man walking a dog in the park” could be described in many valid ways.
Generalization Struggles with unfamiliar, rare, or out-of-distribution object/concept combinations ("yellow elephant").
AI Hallucination Sometimes VLMs produce confident but inaccurate captions, answers, or generations.
Vision Language Model Architectures Comparison
Conclusion
Vision Language Models are empowering machines to perform complex tasks that require both visual perception and fluent natural language understanding. From accessible technology and content moderation to AI-generated art and smarter robotics, the impact of VLMs will grow with better datasets, improved architectures, and rigorous real-world evaluation.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us