



Vision Language Models Explained: How They Work in Practice


There is a recurring problem teams run into when working with AI systems that handle visual data. One model detects objects in an image. Another generates text.
The output then needs to be stitched together manually, and even then, important context is often lost. A chart gets interpreted without its caption. A document gets summarized without understanding its tables.
Vision Language Models solve this by removing the separation entirely. Instead of passing information between systems, they process images and text together, within a single model that reasons across both at once.
This guide breaks down how these models work, what they can handle in practice, how they are being used across industries, which models are leading today, and what to consider before deploying one.
What Are Vision Language Models (VLMs)?
Most real-world data is not purely text or purely visual. Reports include charts. Forms include handwritten fields. Product listings depend on images as much as descriptions.
Traditional AI systems forced these inputs to be handled separately, introducing friction and reducing accuracy. Vision Language Models address this by treating visual and textual data as a single input, making it possible to answer questions that depend on both what is written and what is shown.
A Vision Language Model is an AI system that processes both visual inputs, images, documents, video frames, and natural language together, in a single unified pass. It does not handle vision first and language second. It reasons across both simultaneously, which is what makes it fundamentally different from the AI systems that came before it.
How Vision Language Models Differ from LLMs and Computer Vision
The difference becomes clearer when compared to earlier AI systems.
A Large Language Model (LLM) like GPT-4 or an early version of Claude operates entirely in text. It can write, reason, summarize, and generate code, but it is blind to anything visual. Show it an image, and it has nothing to work with.
An object detection model like YOLO operates entirely in vision. It can tell you that there is a car at coordinates (342, 218) with 94% confidence. But it cannot tell you what the car is doing, whether it is parked illegally, or how that scene relates to a sentence in a document beside it. It classifies, it does not comprehend.
A Vision Language Model does both. It takes an image of a radiology scan and answers the question “Are there signs of pneumonia in the lower left lobe?” in natural language. It reads a financial report that mixes prose, tables, and charts, and produces a summary that treats all three as a single coherent document.
The critical distinction is not that it handles two modalities; it is that it reasons across them jointly.
What Makes VLMs Different from Multimodal AI
Multimodal AI is the broader umbrella term. All Vision Language Models are multimodal, but not all multimodal models are Vision Language Models.
A system that combines audio and text, such as a speech assistant, is multimodal but does not qualify as a VLM. Vision Language Models specifically bridge the vision and language pair, focusing on understanding and reasoning across visual and textual inputs together.
Where Vision Language Models Fit in the AI Stack
How Vision Language Models Work
To understand what these models can do in practice, it helps to look at how they process visual and textual information internally. Knowing how a VLM handles inputs makes it easier to choose the right model, fine-tune it effectively, and anticipate where it may fail.
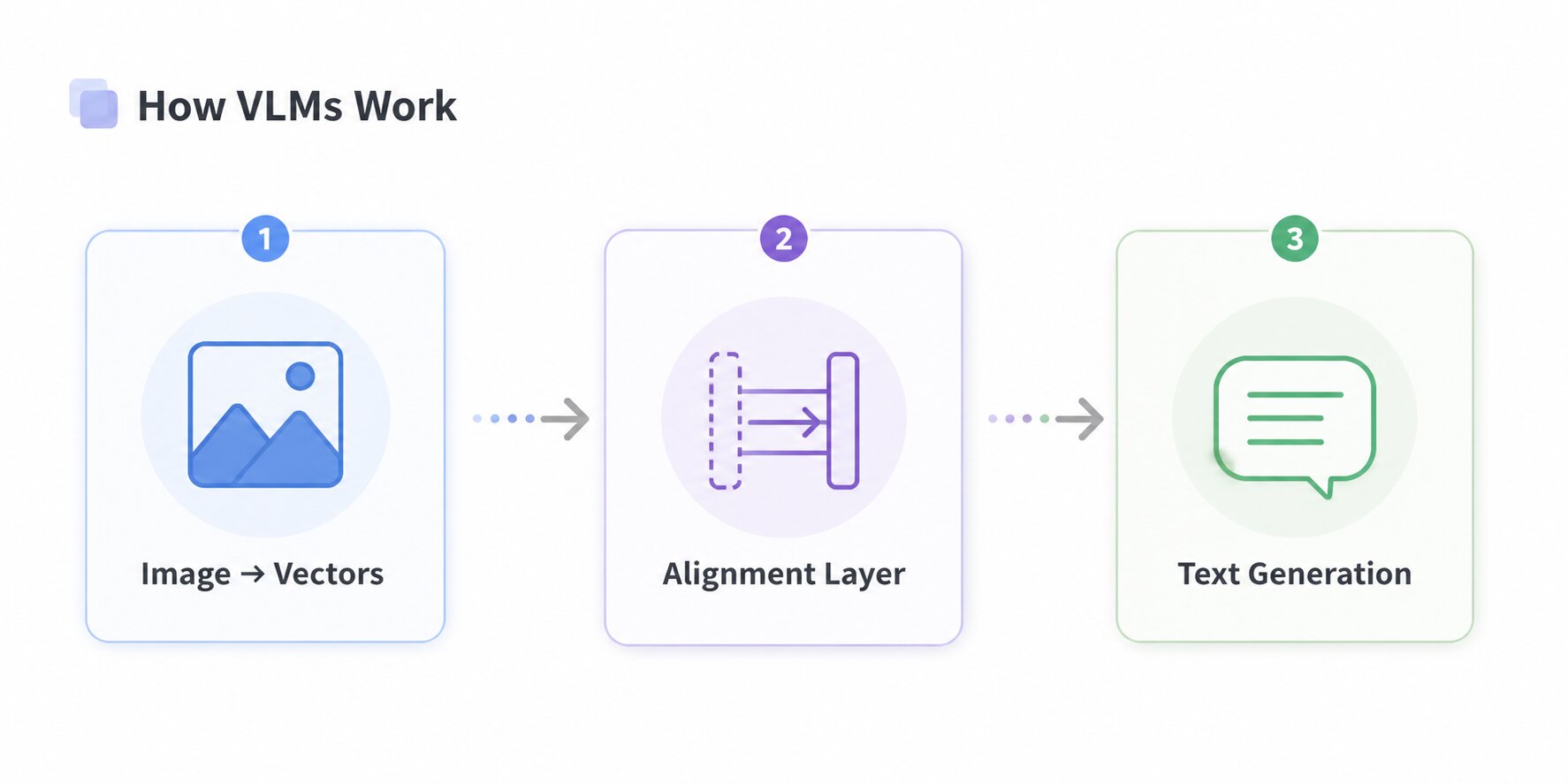
The Core Architecture (Three-Component Stack)
Almost every Vision Language Model in production today is built from three distinct components working in sequence.
Vision encoder
This component takes an image as input and converts it into a mathematical representation, a set of numbers that captures what is in the image, where things are, and how they relate spatially. The vision encoder does not produce words. It produces vectors: dense numerical summaries of visual content that the rest of the model can work with.
Projection layer
This is the bridge. The vision encoder and the language model operate in different representational spaces, and the projection layer translates the visual vectors into a format the language model can interpret. It is often a relatively simple component, sometimes just a small neural network, but it plays a critical role. The quality of this translation directly affects how well the model reasons across visual and textual inputs.
Language model backbone
This is a standard large language model, Llama, Qwen, Mistral, or a proprietary equivalent that receives the translated visual information alongside text tokens and generates a response. From this point forward, the model behaves like a language model, predicting the next token based on everything it has seen.
These three components are trained together (or with selective freezing), so that the model does not experience vision and language as separate streams. Instead, both arrive as a unified sequence.
How Images Are Converted into Tokens
Before an image can be processed alongside text, it needs to be converted into tokens, the same type of discrete units used in language models.
The dominant approach comes from the Vision Transformer (ViT) architecture. A ViT divides an image into a grid of fixed-size patches, typically 16×16 pixels each. A 1024×1024 image becomes thousands of such patches, each treated as a token and processed through transformer layers.
This process is heavily influenced by the broader role of encoder architectures in AI models, where raw inputs are transformed into structured representations that neural networks can understand and process efficiently.
This has a practical implication. A single high-resolution image can consume as many tokens as a long text input. This is why context window size matters when working with VLMs; visual content alone can take up a meaningful portion of the available capacity before any text is added.
More recent approaches address this by using tiling strategies, in which large images are split into overlapping regions, processed separately, and then combined. Others use dynamic resolution, adjusting the number of tokens based on image complexity rather than applying a fixed grid.
How Vision and Language Are Combined
Once the image has been converted into a representation and aligned with the language model, the next step is to integrate it with text.
There are two primary approaches.
In cross-attention fusion, the visual tokens are not inserted directly into the main sequence. Instead, the language model accesses them through cross-attention layers at different stages. This allows visual information to influence the model’s reasoning without dominating the token sequence.
In early fusion, the translated visual tokens are added directly to the text tokens, forming a single combined sequence. The model then processes both together as one input. This approach is simpler, easier to scale, and widely used in modern systems.
The difference between these approaches becomes noticeable in long or complex inputs. Cross-attention methods tend to handle extended visual context more effectively, while early fusion is easier to train and adapt.
Contrastive vs Generative Pretraining
Training a Vision Language Model involves teaching it to connect visual and textual information in a meaningful way. Two primary approaches are used.
Contrastive pretraining trains a model on large datasets of image-caption pairs. The objective is to match the correct caption to the correct image. Over time, the model learns to align visual and textual representations in a shared space. This approach is widely used to build strong vision encoders.
Generative training builds on this by teaching the model to produce open-ended responses. The process follows the same sequential prediction principles used in autoregressive AI models, where outputs are generated token by token based on prior context.
The model is given an image along with a question or instruction and learns to generate an answer grounded in what it sees. This enables tasks such as visual question answering and document understanding.
Most production systems use a combination of both. Contrastive training builds strong visual understanding, while generative training makes the model useful for real-world applications.
What Vision Language Models Can Do
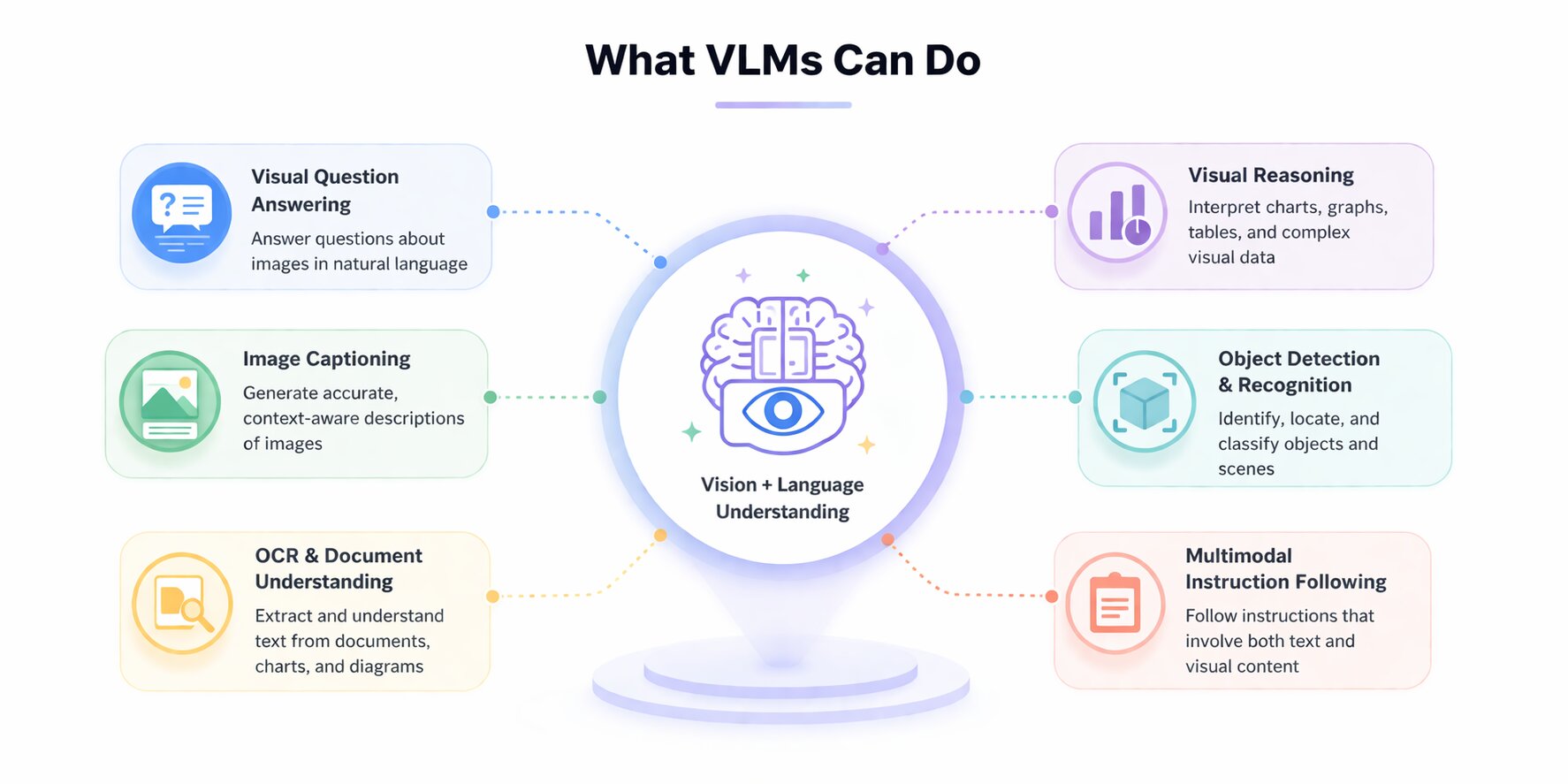
Architecture explains how a VLM processes information. This section focuses on what enables the specific tasks these models are designed to handle and where they provide value over single-modality systems.
These tasks are not isolated features. They represent the core ways VLMs translate visual and textual inputs into usable outputs.
Visual Question Answering
Visual question answering (VQA) is the most direct demonstration of what a VLM can do. You provide an image and a natural language question; the model returns a natural language answer grounded in what it sees.
The questions can range from simple ("What color is the car?") to complex multi-step reasoning ("Based on this chart, which region showed the steepest decline between Q2 and Q3, and what might explain it?").
Modern VLMs handle both ends of this spectrum, though performance degrades as questions require precise spatial localization or fine-grained counting.
A radiologist using a VLM to query a scan, a field technician asking a model to diagnose equipment from a photo, a customer service system answering questions about product images, all of these are VQA applications in production today.
Image Captioning
Image captioning, generating a natural language description of a visual input, was one of the first tasks VLMs were applied to, and it remains one of the most commercially significant.
The challenge is not producing any description, but producing one that is accurate, appropriately detailed, and contextually aware.
A VLM captioning a product image for an e-commerce catalog needs to describe the item accurately across its relevant attributes: material, color, dimensions, and notable features.
The same model captioning a scene for a visually impaired user needs to prioritize what is most navigationally relevant. Captioning is not a single fixed task; it is a class of tasks whose quality depends heavily on how well the prompt is constructed and how well the model has been fine-tuned for the specific domain.
Document and Chart Understanding
This capability is where VLMs create the most immediate value for enterprise use cases. Real-world documents are not clean text files; they are PDFs with embedded tables, presentations with charts, forms with handwritten fields, and reports where the numbers in a chart contradict or extend the numbers in the accompanying paragraph.
A VLM processing a mixed-media document treats the entire thing as one input. This is particularly valuable in systems built around generative AI pipelines, where visual and textual understanding need to work together rather than through isolated processing stages.
A model can cross-reference a figure caption against the chart it describes, extract line items from a scanned invoice that has never been through an OCR pipeline, or summarize a financial report while accurately reflecting both the written narrative and the data in the embedded visualizations.
This is a task category where the gap between a VLM and a traditional document processing pipeline, which typically requires separate OCR, extraction, and summarization steps, is particularly large.
Video and Temporal Reasoning
Video understanding extends VLMs from static images into time. A model that can reason temporally can answer questions like "at what point in this recording does the technician perform the safety check?" or "how does the crowd size change between the opening and closing of this event?" or "flag any frames in this security feed where the defined exclusion zone is entered."
This capability demands more than applying image understanding to individual frames.
True temporal reasoning requires tracking objects and events across frames, understanding sequence and causality, and maintaining context over extended time spans.
Models like Gemini 2.5 Pro, with its million-token context window, are pushing the frontier here, processing hours of video as a single coherent input rather than as a series of disconnected image snapshots
Zero-Shot Generalization
One of the most practically significant properties of VLMs is their ability to handle visual inputs they were never explicitly trained on.
A model trained on general internet data can be asked to analyze a satellite image, a microscopy slide, or a thermal imaging output, and produce a reasonable response, even without any domain-specific training.
This zero-shot capability reduces the barrier to deployment significantly.
Teams that previously needed to collect hundreds of labeled examples to train a specialized classifier can instead prompt a VLM with a clear task description and test it against their data.
Performance will not always match a purpose-built model, but it is often good enough to validate a use case before committing to a fine-tuning effort, which changes the economics of AI development meaningfully.
Vision Language Model Use Cases Across Industries
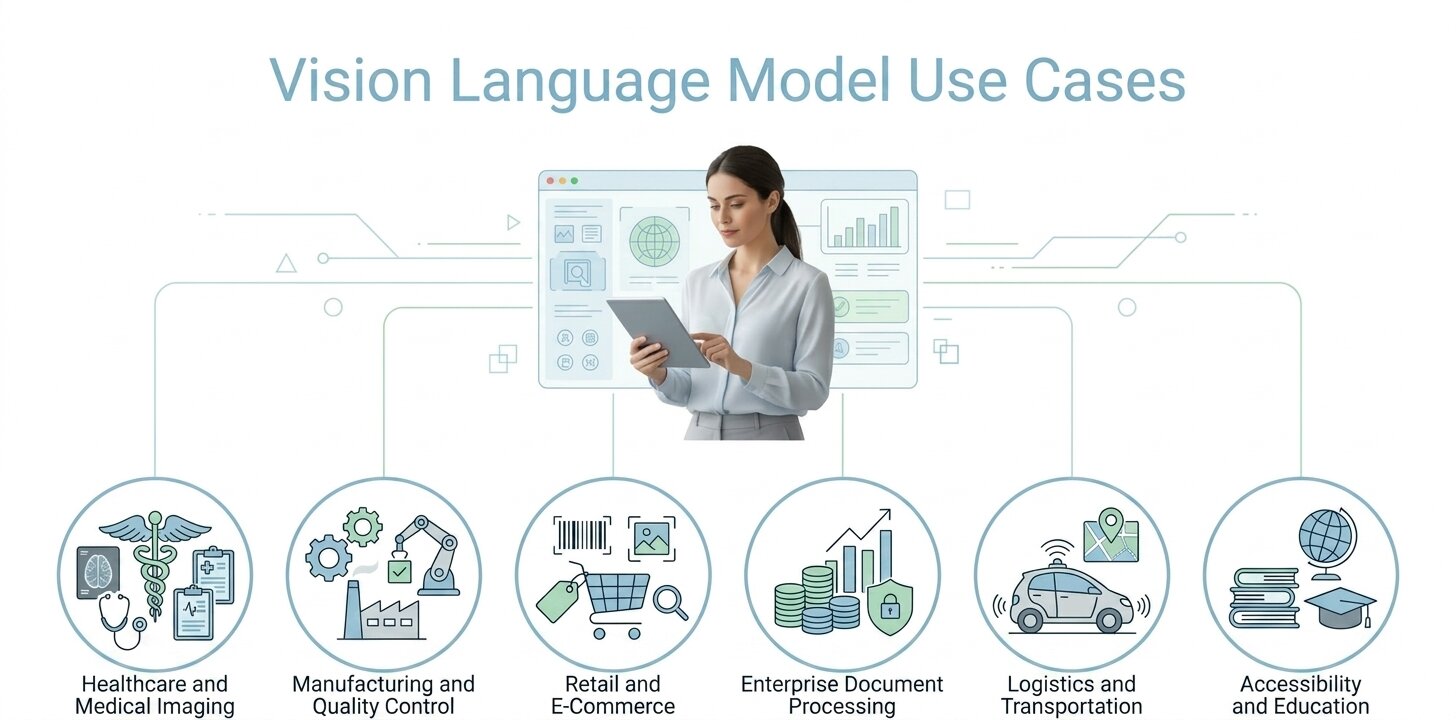
The capabilities described above are already being applied in production systems. Across industries, Vision Language Models are replacing workflows that previously required multiple tools or manual intervention.
Healthcare and Medical Imaging
Healthcare is one of the highest-stakes environments for Vision Language Models, and also one of the most active areas of deployment.
Medical professionals generate large volumes of visual data, scans, slides, endoscopic footage, and dermatology images that require expert interpretation and often create bottlenecks in clinical workflows.
Vision Language Models are used in radiology report generation, where a model analyzes a chest X-ray or CT scan and drafts an initial report for review.
These capabilities are increasingly being integrated into clinical software built for high-stakes environments, where accuracy and reliability are critical.
In surgical assistance, real-time video from endoscopic cameras is analyzed to highlight anatomical structures. In pathology, models help identify anomalies in histology slides faster than manual review allows.
The constraint in healthcare is trust. A model that produces an incorrect interpretation carries consequences far beyond typical software errors. Deployment in clinical settings requires validation, human oversight, and careful handling of model limitations.
Manufacturing and Quality Control
Manufacturing quality control has traditionally relied on rule-based computer vision systems trained for specific defect types under controlled conditions.
These systems are sensitive to changes in lighting, product variation, or new defect patterns.
Vision Language Models allow a different approach. A model deployed on a production line can be prompted in natural language to identify defects, classify severity, or verify assembly conditions.
The same system can adapt to different products without retraining for each variation, which is one of the reasons AI in manufacturing is increasingly shifting toward more flexible multimodal systems instead of narrowly trained inspection models.
This flexibility is particularly useful in environments where product variation is high and traditional computer vision systems become difficult to maintain.
Retail and E-Commerce
Retail generates visual data at a scale where manual processing is not practical. Managing large catalogs requires consistent product descriptions, tagging, and validation of image-to-listing accuracy.
Vision Language Models automate these workflows. A product image can be converted into structured descriptions including material, color, dimensions, and attributes.
Visual search systems allow users to upload an image and retrieve similar products. Returns processing can be supported by comparing returned items with original listings to assess condition.
These use cases reduce manual effort while improving consistency across large product catalogs.
Enterprise Document Processing
Organizations rely on documents that combine text, tables, charts, and images, while most existing systems handle only structured text effectively.
Vision Language Models process these documents as a single input. They can extract data from invoices, interpret charts alongside written explanations, and summarize reports that include mixed formats.
This removes the need for separate OCR, extraction, and analysis pipelines, particularly in workflows where meaning depends on both visual and textual content.
Accessibility and Education
Accessibility applications highlight the direct impact of Vision Language Models. Scene description tools for visually impaired users can describe environments, identify objects, and respond to follow-up questions based on visual input.
In education, models can interpret handwritten problems, explain visual diagrams, and adapt explanations based on the specific content a learner is interacting with.
These applications depend on the ability to understand visual context and connect it with language in a meaningful way.
These examples show how Vision Language Models are being used in practice, especially in workflows where separate systems previously struggled to handle visual and textual data together. What matters next is how different models approach these tasks and how that affects real-world performance.
Leading Vision Language Models in 2026
The VLM landscape in 2026 is no longer a small field of research models. It has evolved into a competitive ecosystem of proprietary APIs, open-source weights, and domain-specialized variants, each with a distinct profile of strengths, trade-offs, and ideal use cases.
Proprietary Vision Language Models
GPT-4o (OpenAI) is currently one of the most widely deployed proprietary VLMs. It scores 59.9% on the MMMU-Pro benchmark and handles text, images, and video with strong general reasoning. Its advantages include consistent performance across a wide range of tasks, mature API tooling, and reliability in production environments. Its limitations include API cost at scale, restrictions around data privacy, and the inability to fine-tune on domain-specific data.
Gemini 2.5 Pro (Google DeepMind) is differentiated by its ability to handle long-context inputs and multi-step reasoning. Its architecture supports processing large volumes of multimodal data, such as extended video or long-form documents, within a single context. It integrates naturally into productivity workflows, particularly in environments built around Google’s ecosystem.
Claude Sonnet (Anthropic) is positioned around reliability in high-stakes domains. It produces fewer confident errors in regulated environments such as legal, financial, and clinical settings. Its outputs tend to reflect uncertainty more appropriately when evidence is ambiguous, which makes it a practical choice where incorrect conclusions carry risk.
Open-Source Vision Language Models
Qwen 2.5 VL (Alibaba Cloud) is one of the strongest open-source options available. It supports multilingual inputs, handles video, and is available in a range of model sizes. Its performance on benchmarks such as MMMU-Pro places it alongside leading proprietary models, while retaining the ability to be fine-tuned for domain-specific use cases.
LLaMA 3.2 Vision (Meta) benefits from a broad ecosystem and strong community support. Its architecture preserves spatial detail effectively, making it suitable for tasks that require localization, such as document parsing and structured extraction. Larger variants approach proprietary model performance in document-heavy scenarios.
InternVL3-78B delivers strong performance on complex reasoning tasks involving images and leads open-source benchmarks such as MMMU. Its architecture combines a dedicated vision model with a large language backbone, producing strong results on multi-step visual reasoning problems.
Gemma 3 (Google DeepMind) is designed for efficiency and domain specialization. Its smaller model sizes make it suitable for constrained environments, while derivatives such as MedGemma demonstrate how domain-specific adaptation can improve performance in targeted use cases like healthcare.
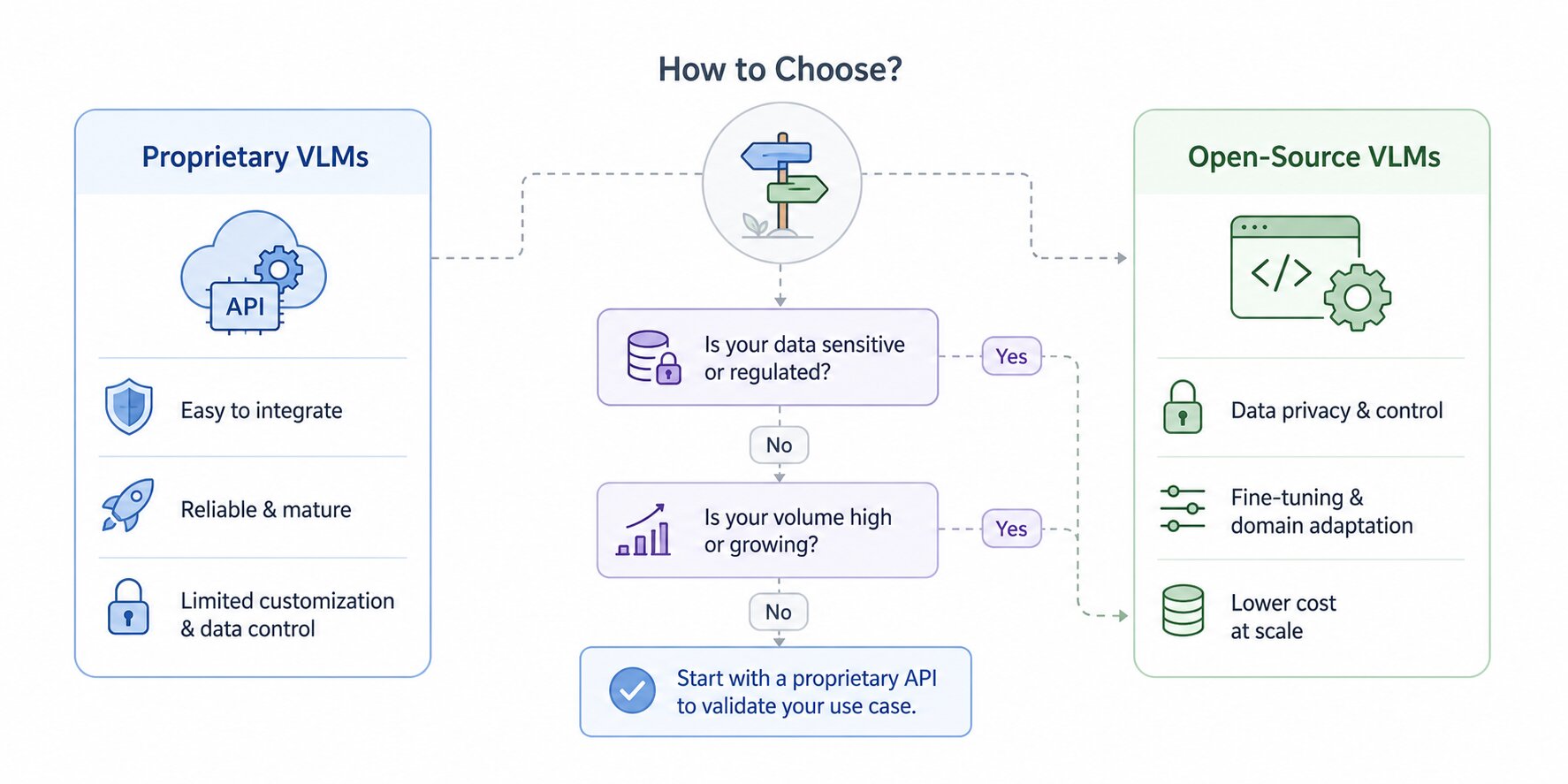
Open-Source vs Proprietary Vision Language Models
The performance gap between open-source and proprietary Vision Language Models has narrowed significantly. In some cases, open-source models now match or exceed proprietary alternatives — for example, Qwen 2.5 VL outperforms GPT-4o on the MMMU-Pro benchmark. At the same time, open-source inference costs have decreased compared to commercial API usage.
The decision is no longer primarily about performance. It comes down to four practical factors: data privacy, fine-tuning requirements, cost at scale, and compliance constraints. Open-source models can run locally and be adapted to domain-specific needs, while proprietary APIs offer ease of integration but limit control over data and customization.
A practical way to approach this is to start with a proprietary API to validate whether a Vision Language Model can solve your problem. If the use case works and the data is non-sensitive with low volume, continuing with an API is often sufficient. If volume increases, data becomes sensitive, or domain adaptation is required, moving to an open-source model with fine-tuning becomes the more viable option.
Model Comparison Overview
Choosing and Deploying a Vision Language Model
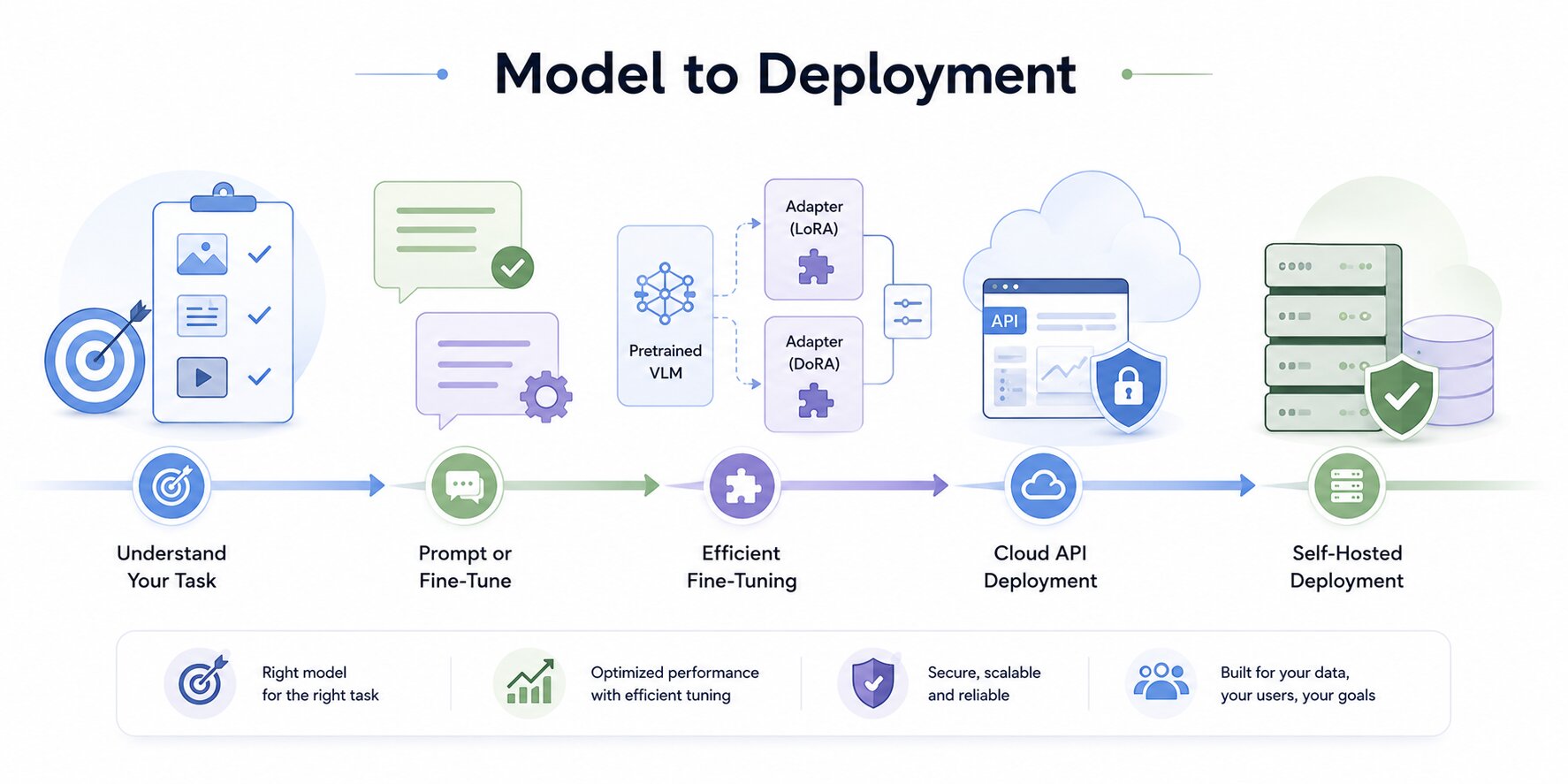
At this stage, the focus shifts from understanding Vision Language Models to making practical decisions about how to use them. Model comparisons provide context, but real-world performance depends on how well a model is matched to the task and deployed within system constraints.
Matching the Model to Your Task
Before selecting a model, get precise about the task. A common mistake is choosing based on benchmark scores rather than testing on representative data.
The key questions are straightforward: what is the primary input type (images, documents, video), what output format is required (free-form text, structured data, classifications), and how domain-specific the task is. Latency requirements and data sensitivity also matter, whether inputs can leave your infrastructure or need to remain local.
A practical approach used by AI development teams is to take a small set of representative examples, including expected failure cases, and test them across two or three models. Benchmark scores measure general capability; your data reflects real-world fit.
Prompting vs Fine-Tuning
The next decision is whether fine-tuning is needed. For many tasks, careful prompting is sufficient to reach acceptable performance without modifying model weights.
Prompting works well when the task is general, instructions can be clearly defined, and outputs are consistent across inputs. It is the lowest-effort starting point and should be explored before considering further adaptation.
Fine-tuning becomes necessary when the model consistently fails on domain-specific inputs, struggles to produce outputs in a required format, or requires reduced latency that cannot be achieved through longer prompts alone.
Efficient Fine-Tuning Approaches
Full fine-tuning of large models is rarely practical. Parameter-efficient methods such as LoRA (Low-Rank Adaptation) make domain adaptation feasible with significantly lower compute requirements.
Instead of updating all model parameters, LoRA introduces small trainable components into selected layers while keeping the base model frozen. This preserves general knowledge while adapting behavior to a specific task.
In practice, teams often freeze the vision encoder and most of the language model, training only the projection layer and a small number of adapter layers. This reduces training cost while maintaining strong performance.
More recent variations, such as DoRA, follow a similar principle while improving adaptation quality in some scenarios, but the overall approach remains the same: adjust only what is necessary.
Deployment Options
Where a VLM runs shapes every other decision, including latency, cost, privacy, and the model size you can afford.
Cloud API deployment is the lowest friction path. You call an endpoint, you receive a response. No infrastructure to manage, no model to host. The trade-offs are data egress (your images leave your infrastructure), per-token cost that compounds at scale, and dependence on a third party's uptime and rate limits. Suitable for: low-to-medium volume, non-sensitive data, teams without ML infrastructure.
Self-hosted cloud deployment (running an open-source model on your own cloud instances) gives you data control and fine-tuning capability while keeping infrastructure in the cloud. The operational overhead is higher; you manage model serving, scaling, and updates, but the economics are more predictable at scale, and sensitive data stays within your virtual private cloud.
On-device and edge deployment is the most constrained environment and the fastest-growing one. Models in the 1B–10B parameter range, Phi-4-Multimodal, Gemma 3 1B–7B, small Qwen variants, can run on NVIDIA Jetson Orin hardware with sub-100ms inference latency and no cloud dependency. The trade-off is accuracy: smaller models sacrifice 10–15% on typical benchmarks compared to their 70B counterparts. The use cases that justify this trade-off are ones where latency or privacy cannot be compromised, such as retail point-of-sale, robotics, mobile applications, and on-device accessibility tools.
Limitations of Vision Language Models
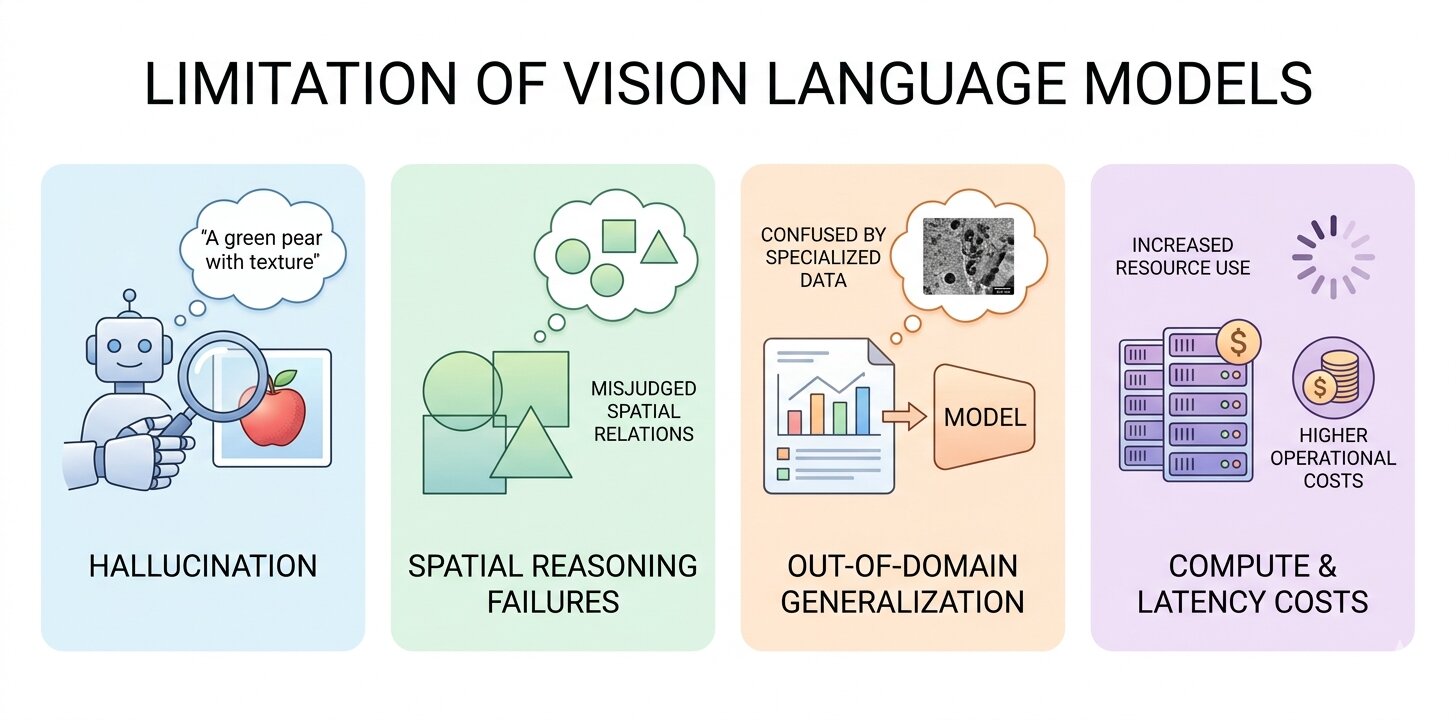
Production deployments of VLMs come with failure modes that are well documented in research but often underappreciated until they appear in real data. These are not reasons to avoid VLMs, but constraints that need to be accounted for when designing systems around them.
Hallucination
Hallucination in VLMs refers to the model generating confident, fluent, plausible-sounding output that is simply not supported by the visual input. A VLM analyzing an X-ray might describe a nodule that is not there.
A model processing a financial chart might report a trend that runs in the opposite direction from the actual data. A system reviewing a product image might confidently describe color or text that does not appear in the image.
Hallucination rates for complex scenes currently range from 10–30%, depending on the model and task, according to benchmarking data from LabelYourData's 2025 evaluation.
The cause is structural: VLMs learn to predict plausible outputs from statistical patterns in training data, and when visual evidence is ambiguous, the language model component tends to fill gaps with what seems statistically likely rather than flagging uncertainty.
Mitigation strategies that work in practice: grounding outputs to specific image regions using bounding box references, requiring the model to cite the visual evidence for each claim it makes, running a second validation pass (either a separate model or a structured consistency check), and maintaining human review for any output that will drive a consequential decision in deployed machine learning models.
Spatial Reasoning Failures
VLMs consistently underperform on tasks that require precise spatial understanding, counting objects accurately, identifying exact positions of items relative to each other, or reasoning about geometric relationships when shapes overlap or are in proximity.
Research published in 2024 showed that state-of-the-art VLMs, including GPT-4o and Gemini, perform near-chance on tasks requiring precise spatial reasoning with overlapping geometric primitives, even though the same models achieve near-perfect accuracy when shapes are well-separated.
The vision encoder contains sufficient information to solve these tasks; the failure occurs in translating the visual representation into language reliably.
Current VLMs score 50–60% accuracy on standardized spatial reasoning benchmarks. For use cases where spatial precision is critical, such as floor plan analysis, surgical navigation, and component assembly verification, this is a meaningful constraint that requires task-specific validation before deployment.
Out-of-Domain Generalization
A VLM that achieves strong benchmark scores on standard datasets may fail substantially when deployed on domain-specific visual data. The gap between benchmark performance and real-world task performance is one of the most consistent findings in applied VLM research.
This happens because benchmark datasets reflect the distribution of general data, common photography, standard document types, and typical chart styles.
When a model encounters domain-specific inputs such as industrial microscopy images, proprietary document formats, or thermal imaging outputs, it faces a distribution it has rarely seen. The model does not recognize this shift and produces a response with the same apparent confidence.
The practical approach is to test on your own data before relying on benchmark results, and fine-tune on domain-specific examples when performance is consistently insufficient.
Compute and Latency Costs
Processing an image through a VLM is meaningfully more expensive in compute time, memory, and cost than processing text alone. A 1024×1024 image generates thousands of visual tokens before any text is added, consuming a measurable portion of the model’s context window and compute budget.
At low volumes, this overhead is manageable. At scale, such as processing large product catalogs or high volumes of documents, cost becomes a significant factor.
Teams moving from prototype to production often find that per-image inference costs are several times higher than text-only systems, which affects model selection and deployment decisions.
Practical mitigation includes reducing image resolution where acceptable, batching requests, caching repeated inputs, and evaluating whether smaller or quantized models meet accuracy requirements at lower cost.
These limitations do not reduce the value of Vision Language Models, but they define the boundaries within which they operate. Understanding these constraints is what allows teams to move from successful prototypes to systems that behave predictably in production.
How Vision Language Models Are Evolving
The current limitations of Vision Language Models are shaping how the next generation of systems is being built. Models that see images and respond in text are already useful in production, but the direction of the field is toward systems that extend beyond interpretation into action across physical and digital environments.
Vision-Language-Action (VLA) Models
The next architectural step beyond VLMs is the Vision-Language-Action model, extending perception and reasoning with an action output, generating not just text, but physical control signals for robotics or sequences of interactions for software systems.
Google DeepMind’s RT-2 was an early demonstration of this approach. Figure AI’s Helix, introduced in early 2025, represents a more mature system that controls a humanoid robot’s upper body in response to visual input and natural language instructions.
The broader AI robotics market is expected to grow significantly through the decade, with VLA models forming a core enabling layer.
Current success rates, around 60–80% on structured tasks in controlled environments, are sufficient for supervised automation but not yet reliable for fully autonomous operation in unstructured settings. Wider deployment depends on improvements in reliability.
Agentic Vision Systems
VLMs are also becoming the perceptual layer for software-based AI agents that interpret visual interfaces, browser windows, desktop applications, or video feeds, and act based on what they observe.
An agentic system can navigate websites, complete forms, extract data, and verify outcomes by reading interface states. This enables automation in environments without APIs or structured access, extending AI systems into legacy software and visually driven workflows using modern LLM application frameworks.
The shift is from API-driven automation to interface-driven automation, where the model interacts with systems the same way a human user would.
Domain-Specialized Vision Language Models
The move toward domain-specific models is becoming more pronounced. Instead of relying on a single general-purpose system, organizations are working with models adapted to specific domains.
MedGemma, a healthcare-focused variant of Gemma 3, reflects this direction, combining a general architecture with domain-specific training and evaluation aligned to clinical use cases. Similar patterns are emerging across legal, industrial, and geospatial domains, where general models leave measurable accuracy gaps.
This creates a practical decision point: adopt a provider’s domain-specific model or adapt a general open-source base using proprietary data. The answer depends on data availability, integration complexity, and control requirements.
On-Device and Edge Deployment
Another clear trend is the move toward smaller models that run locally without cloud dependency. While larger models still lead in accuracy, the gap with smaller edge models is narrowing.
Models such as Phi-4-Multimodal on NVIDIA Jetson Orin hardware achieve low-latency inference, enabling use cases where response time is critical, wearable accessibility tools, in-vehicle systems, and real-time robotics. These scenarios prioritize latency and data control over maximum accuracy.
As quantization improves and hardware advances, more tasks will shift toward local execution, expanding VLM use in environments where cloud-based processing is not practical.
Vision Language Models are moving from systems that interpret visual input to systems that operate within it. The shift is not only in capability, but in how these models are used, from passive analysis toward active participation in both digital and physical workflows.
Conclusion
Vision Language Models have moved from research demonstrations to production infrastructure faster than most AI technologies. The architecture is mature, the open-source ecosystem provides real alternatives, and the range of tasks they handle is broad enough to justify evaluation across most industries working with visual data.
The picture includes real limitations, hallucination, spatial reasoning gaps, out-of-domain failure, and computational costs that require careful management at scale. None of these is disqualifying. They are engineering constraints, and like most engineering constraints, they are manageable with the right architectural decisions and validation approach.
If your team is working on a product or workflow where visual and textual data need to be understood together, the question is no longer whether a VLM can help. It is the question of which model to use, how to deploy it, and what safeguards to put in place.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us