



LlamaIndex for LLM Applications Using Private Data


Large language models are powerful, but they fall short in real business settings where answers must come from private documents, internal databases, and constantly changing knowledge. Without a structured retrieval layer, models rely only on pre-training, which leads to gaps, outdated responses, and avoidable errors in production systems.
According to a Databricks industry report, 70% of companies using generative AI rely on retrieval-augmented generation (RAG) and vector database systems to ground model outputs in real data.
This guide explains how LlamaIndex supports these workflows, how it fits into RAG-based architectures, how it works in practice, common use cases, production trade-offs, and how to evaluate it against similar frameworks.
How LlamaIndex works in practice
Before getting into architecture choices or system constraints, it’s useful to understand how LlamaIndex behaves during a typical request. At runtime, it sits quietly between your data and the model, shaping what context is retrieved and how that context reaches the LLM when a question is asked.
Where LlamaIndex sits in the system
At a high level, LlamaIndex sits between your private data sources and a language model. It does not replace the model or the database. Instead, it manages how information is prepared and delivered to the model at query time.
Rather than sending entire documents or datasets to the LLM, LlamaIndex acts as a control layer that decides what information should be retrieved and how it should be presented.
What happens before a question is asked
Before users interact with the system, private data is ingested from sources such as documents, databases, or internal tools. This data is broken into smaller units and organized into indexes designed for efficient retrieval.
This preprocessing step allows large and diverse datasets to be searched quickly later without exceeding model context limits.
What happens when a user asks a question
When a query is submitted, LlamaIndex searches the index to find the most relevant pieces of information. It assembles this context into a structured prompt and sends it to the language model.
The model then generates the final response using that retrieved context rather than relying only on what it learned during training.
Why this pattern matters
This retrieval-first approach allows language models to answer questions using private, current, and controlled information without retraining. It also makes system behavior more predictable, auditable, and easier to evolve as data changes.
Building LLM applications with private data
Most production AI systems are not built to answer general questions from the public internet. They are expected to work with internal documents, product knowledge, customer records, policies, and operational data. Understanding what “LLMs with private data” actually involves is critical before evaluating any framework or architecture.
Why LLMs can’t access private data by default
Large language models do not have live access to internal systems. After training, they operate in isolation unless explicitly connected to external data sources. That means:
They cannot see company documents, databases, or APIs unless those are provided at runtime.
They cannot reflect recent updates unless new data is retrieved dynamically.
They generate answers based on statistical patterns, not verified internal facts.
Without an integration layer, even a strong model will respond with incomplete or incorrect information when private context matters.
Typical business scenarios
This limitation shows up in common use cases such as:
Searching internal documentation or knowledge bases
Answering customer support questions from policy or product data
Assisting employees using internal procedures or technical manuals
Analyzing proprietary reports or research files
In practice, this data spans unstructured files (PDFs, emails, knowledge bases), structured systems (SQL databases, CRMs), and SaaS platforms, each with different access patterns and update cycles.
Why retrieval is required
To solve this, modern systems use retrieval: fetching relevant information from private sources at the time of a query and providing it to the model as context. This allows the model to reason over current, verified data instead of guessing.
Retrieval also enables systems to reflect new information immediately without retraining the model and to enforce access controls so users only receive information they are authorized to see. This shift moves applications from “generate from memory” to “generate from evidence,” which is essential for reliability in business environments.
Where LlamaIndex fits
LlamaIndex sits in this retrieval layer. It does not replace the language model or the data store. Instead, it structures how private data is ingested, indexed, retrieved, filtered, and prepared so the model can use it effectively during inference.
Conceptually, this turns LLM applications into pipeline-based systems where search and context preparation happen before generation. LlamaIndex provides the framework to manage this process consistently across different data sources and application types.
The technical problem LlamaIndex is designed to solve
LLM applications that rely on private or enterprise data face technical constraints that do not appear in public chatbot use cases. These constraints affect answer accuracy, system behavior, operating cost, and long-term reliability, which makes them important to understand before choosing any retrieval framework.
Context window limits
LLMs can process only a fixed amount of text in a single request. Even models with large context windows cannot accept full document repositories, long knowledge bases, or database snapshots at once.
In real systems, this forces teams to decide which information to include for every query. As datasets grow, this trade-off becomes harder to manage. Important details are left out, responses lose precision, and similar questions can produce different answers depending on how context is assembled.
Hallucinations under missing context
When required information is not present in the input, models do not respond conservatively. They generate answers based on probability rather than verified sources.
In business environments, this typically results in:
Incorrect policy or procedural guidance
Misleading operational recommendations
Reduced confidence in system outputs
The root cause is not model quality alone, but the absence of reliable, query-time access to internal knowledge.
Large documents and enterprise databases
Most enterprise knowledge is spread across long documents, internal portals, and structured systems such as SQL databases and CRMs. This information cannot be passed directly to a model without exceeding context limits or driving up token costs.
Without selective segmentation and retrieval, systems either overload the model with too much text or provide too little context for accurate reasoning.
Why prompt-only approaches fail
Early implementations attempted to address these issues by expanding prompts or relying heavily on prompt engineering. This approach does not scale.
As data volume increases:
Prompts become expensive to run
Maintenance becomes complex
Output quality becomes inconsistent
Filtering sensitive data becomes unreliable
At production scale, the core challenge is no longer generating language. It is controlling which verified information the model receives at the moment it produces an answer. This is the technical gap LlamaIndex is designed to address.
LlamaIndex as a solution for LLM and private data workflows
Using LLMs with private data requires more than selecting a strong model. Teams must design how internal information is ingested, organized, retrieved, filtered, and delivered to the model at runtime.
LlamaIndex addresses this layer of the system. It does not replace core infrastructure components, but it defines how private data is prepared and supplied to LLMs in a controlled and repeatable way.
In enterprise environments, this retrieval layer is often implemented as part of broader enterprise generative AI system development, where data pipelines, model orchestration, and access control are designed together.
What LlamaIndex does
LlamaIndex provides a framework for connecting enterprise data sources to language models during inference. It standardizes how data is collected from files, databases, and APIs, how it is indexed for search, and how relevant context is assembled for each query.
In practice, this allows applications to supply small, focused, and relevant information blocks to the model instead of large, unstructured text payloads. This improves answer consistency, reduces token usage, and makes system behavior easier to reason about as datasets grow.
What LlamaIndex does not replace
LlamaIndex is not a language model, a storage system, or an application backend. It does not generate responses, persist long-term records, or manage authentication and business logic.
Those responsibilities remain with:
LLM providers for text generation
Databases and vector stores for data persistence
Application services for access control and user management
LlamaIndex operates between these layers to coordinate how private data flows into model requests.
Where it sits in the LLM stack
Within a typical architecture, LlamaIndex is part of the application infrastructure layer. It sits between data sources and the language model and handles ingestion, indexing, retrieval, and context preparation before a prompt is sent to the model.
This positioning allows teams to modify retrieval strategies, indexing methods, or filtering rules without changing the model itself. As a result, system behavior can evolve as data grows or requirements change, without retraining or replacing the LLM.
When it is used
LlamaIndex is commonly applied in systems that must generate responses based on:
Internal documentation and knowledge bases
Business data that changes frequently
Large collections of structured and unstructured files
Information that requires filtering by user permissions or business rules
In these environments, it provides a structured alternative to embedding large datasets directly into prompts or maintaining custom retrieval logic in application code.
Getting started with LlamaIndex in real projects
In real projects, LlamaIndex is rarely adopted all at once. Teams usually start by connecting a small set of internal data, validating retrieval quality, and gradually expanding scope as confidence grows. The patterns that emerge during this phase often matter more than any individual configuration option.
Typical project starting point
Most teams introduce LlamaIndex after realizing that prompt-only approaches are no longer sufficient. This usually happens when applications need to work with internal documents, frequently updated knowledge, or data that cannot be embedded directly into prompts.
At this stage, LlamaIndex is added as a dependency within an existing backend or AI service rather than as a standalone system.
Initial setup focus areas
When teams move from architectural planning to an actual implementation, the first challenge is not tooling but scope. Early decisions tend to lock in how flexible, accurate, and maintainable the system will be later, which is why this stage deserves deliberate attention rather than quick defaults.
At this point, most teams are aligning technical constraints with real business usage. The goal is to define what information the model should be allowed to see and how that information should be prepared before it ever reaches an LLM.
Early implementation efforts typically focus on three practical decisions:
Which data sources should be accessible to the model
How that data should be segmented and indexed
Which language model will consume the retrieved context
Taken together, these choices influence how reliable responses feel in everyday use. Well-scoped data access and thoughtful indexing often have a greater impact on answer quality and system trust than swapping between similar language models later in the lifecycle.
What teams do not need to do upfront
Getting started with LlamaIndex does not require model training, fine-tuning, or changes to core application logic. The language model remains unchanged, and the retrieval layer evolves independently.
This makes initial adoption lower risk compared to approaches that tightly couple data, prompts, and model behavior.
How systems evolve over time
As usage grows, teams typically refine indexing strategies, add filtering rules, and introduce evaluation checks to improve answer quality. These changes happen within the retrieval layer without disrupting the rest of the system.
This incremental adoption path is one reason LlamaIndex fits well into production environments where requirements change over time.
How LlamaIndex fits into LLM application workflows
Understanding how LlamaIndex fits into the request lifecycle helps clarify what problems it actually solves and what it leaves to other parts of the system. At a high level, it manages how private data is prepared, organized, and delivered to the language model for each query.
Data ingestion
The workflow begins by collecting data from its original sources, such as internal documents, databases, or APIs. During ingestion, raw content is normalized into a consistent internal format so that different data types can be handled uniformly.
This step allows systems to work with a mix of unstructured files and structured records without requiring the model to interpret raw source formats directly.
Indexing
After ingestion, the data is organized into indexes designed for efficient lookup. Indexing defines how content is segmented and represented so it can be searched quickly later.
The choices made here influence:
How precise retrieval can be
How much data must be processed per query
How well the system scales as data volume grows
A poorly structured index increases latency and reduces answer quality, even when the underlying model is strong.
Retrieval
When a user submits a request, LlamaIndex searches the index to find the most relevant pieces of information. Instead of selecting full documents, it identifies small, targeted segments that are most likely to support the response.
This step limits the amount of data passed to the model, which helps control token usage and reduces the chance that irrelevant context will affect the output.
Response generation and the role of the LLM
Once relevant context is selected, it is packaged into a prompt and sent to the language model. The LLM then performs the actual reasoning and text generation.
LlamaIndex does not generate responses or modify the model’s behavior. Its responsibility is to ensure that:
The right information is supplied
The information is current and relevant
The prompt remains within practical size limits
Together, these steps form a pipeline where data handling and language generation are clearly separated, allowing systems to evolve their retrieval strategy without changing the model itself.
Core components inside LlamaIndex

Understanding LlamaIndex at a component level helps clarify what parts of the workflow it controls and where its responsibilities end.
Instead of functioning as a single opaque system, it is built from several focused layers that handle data intake, organization, selection, and preparation for the language model. Each layer addresses a specific technical concern in private-data LLM workflows.
Data connectors
Data connectors define how information enters the system.
They handle extraction from sources such as file systems, internal tools, databases, and APIs, and convert raw content into a consistent internal format. This normalization step ensures that downstream components do not need to account for differences in source structure or data type.
In practice, this reduces the amount of custom ingestion code teams must maintain and allows data sources to be added, replaced, or updated without redesigning the retrieval pipeline.
Index types
Index types determine how ingested data is structured for retrieval.
Different indexing strategies support different access patterns, including semantic similarity search, keyword matching, and hybrid approaches. The choice of index directly affects:
Retrieval accuracy
Query latency
Storage requirements
Ongoing operating cost
Because indexing shapes how data can be found and filtered later, it becomes an architectural decision rather than a simple configuration detail.
Retrievers
Retrievers decide which pieces of indexed data are relevant to a given query.
They apply ranking and filtering logic to narrow large datasets into a small, focused set of context segments that can be passed to the language model.
If this layer is poorly tuned, systems often return incomplete or off-topic context, which leads to lower answer quality even when the underlying data and model are sound.
Query engines
Query engines define how requests are executed across the system.
They coordinate retrieval steps, filtering rules, and context assembly into a repeatable processing flow, ensuring that similar questions are handled consistently over time.
This component also determines how easily teams can adjust retrieval strategies or introduce new logic without rewriting application code or changing the model layer.
Response synthesis
Response synthesis controls how retrieved information is prepared before being sent to the language model.
This includes ordering content, removing duplication, and formatting context so it fits within practical input limits and remains easy for the model to interpret.
While the model generates the final output, this step strongly influences quality by shaping what evidence the model receives and how clearly that information is presented.
LlamaIndex and Retrieval-Augmented Generation (RAG)
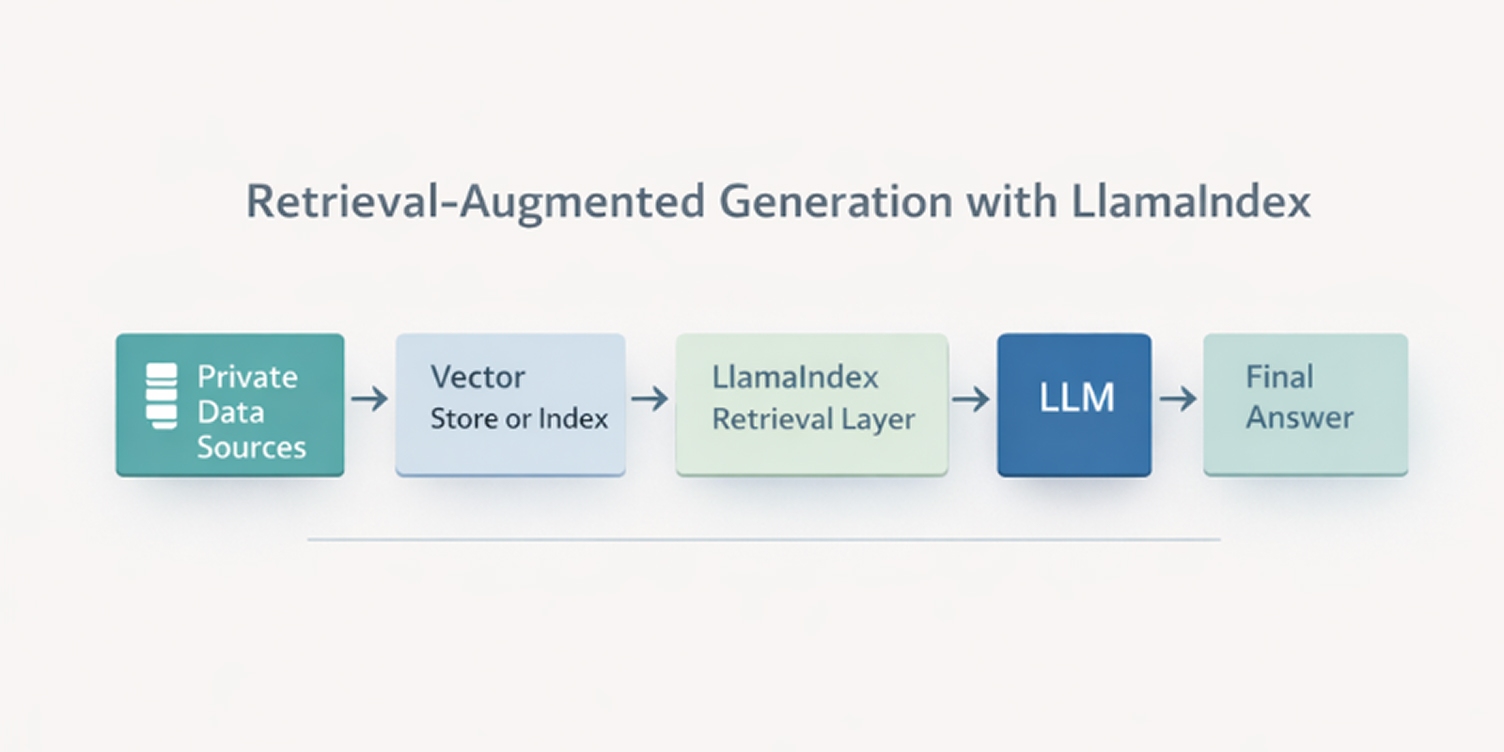
Most production LLM systems today rely on retrieval-augmented generation rather than standalone model prompts. Understanding how LlamaIndex fits into this pattern helps clarify both its design choices and its practical role in enterprise AI architectures.
In production environments, this pattern is usually implemented alongside orchestration layers, vector storage, and evaluation tooling commonly found in LLM application stacks used in enterprise systems.
What retrieval-augmented generation means in practice
Retrieval-augmented generation combines two steps: first retrieving relevant information from external data sources, then using a language model to generate a response based on that information.
Instead of relying solely on what the model learned during training, the system supplies current, domain-specific context at query time. This allows responses to reflect private knowledge, recent updates, and structured business data without changing the model itself.
Why retrieval is preferred over fine-tuning
Fine-tuning modifies a model’s parameters using additional training data. While useful in narrow scenarios, it is rarely practical for most business systems.
In production environments, retrieval is preferred because it:
Reflects new or updated data immediately
Avoids retraining cycles and model redeployment
Reduces the risk of embedding sensitive information into model weights
Allows access control to be enforced at query time
These properties make retrieval-based systems easier to maintain and safer to operate as data volumes and compliance requirements grow.
How LlamaIndex implements RAG
LlamaIndex provides the infrastructure layer that makes retrieval-augmented generation repeatable and manageable.
It handles data ingestion, indexing, query-time retrieval, and context assembly, then passes structured prompts to the language model. This separates data management from language generation and allows retrieval strategies to evolve without changing the model layer.
In practice, this means teams can adjust indexing methods, filtering rules, or ranking logic independently as their data or use cases change.
These retrieval layers are typically deployed alongside other components such as evaluation pipelines, prompt management, and orchestration services that appear in most toolchains used for building LLM-powered applications.
The role of vector databases
Vector databases are commonly used within RAG systems to support semantic search across large datasets.
They store numerical embeddings that represent the meaning of text segments, allowing retrieval to be based on similarity rather than exact keywords. LlamaIndex integrates with vector databases as one possible storage and search backend but does not require them for all deployments.
The choice to use a vector store depends on dataset size, query complexity, and performance requirements.
Related background on retrieval-augmented generation
Retrieval-augmented generation is a broader architectural pattern used across many production AI systems, with multiple design variations depending on data sources, indexing strategies, and system constraints.
This article focuses on how LlamaIndex fits into that pattern. A standalone guide covering RAG concepts, architecture options, and trade-offs in depth is not currently available in this blog.
Common real-world use cases
Understanding where LlamaIndex is typically applied helps determine whether it fits a given project. Most teams adopt it to support information-heavy workflows where answers must be derived from private, distributed, and frequently changing data rather than public knowledge.
Internal knowledge search
Organizations store critical information across multiple systems, including internal wikis, policy documents, shared drives, and collaboration tools. Traditional keyword search often fails when queries are incomplete or documents are inconsistently structured.
LlamaIndex is used to index content across these sources and retrieve relevant sections based on meaning rather than exact phrasing. In enterprise settings, this is commonly combined with permission checks so users only see information they are authorized to access.
Document question-and-answer systems
Many business processes rely on long documents such as contracts, technical manuals, regulatory filings, and operating procedures. Manually extracting specific details from these files is slow and error-prone.
Document Q&A systems built with LlamaIndex allow users to ask targeted questions and receive responses grounded in the relevant sections of source material, which reduces lookup time and lowers the risk of misinterpretation.
Customer and internal support assistants
Support teams depend on accurate, up-to-date information from product documentation, internal guidelines, and historical case data. Static chatbots often degrade in quality as content changes or new policies are introduced.
With retrieval-based context, assistants can respond using current knowledge without retraining the model, which is especially useful in environments where procedures and product details change frequently.
Developer documentation bots
Engineering teams maintain large volumes of API references, architecture notes, and internal design documentation. Finding specific implementation details can slow onboarding and troubleshooting.
Common scenarios include queries about:
API usage and configuration options
System architecture and service boundaries
Internal libraries and deployment procedures
LlamaIndex enables conversational access to this material across multiple repositories without requiring developers to manually search each source.
Research and analysis tools
Analysts and research teams often work with large collections of reports, datasets, academic papers, and internal studies.
LlamaIndex supports tools that retrieve and summarize relevant passages across thousands of documents, helping teams compare sources, identify patterns, and validate findings without scanning files individually.
LlamaIndex vs LangChain and similar frameworks
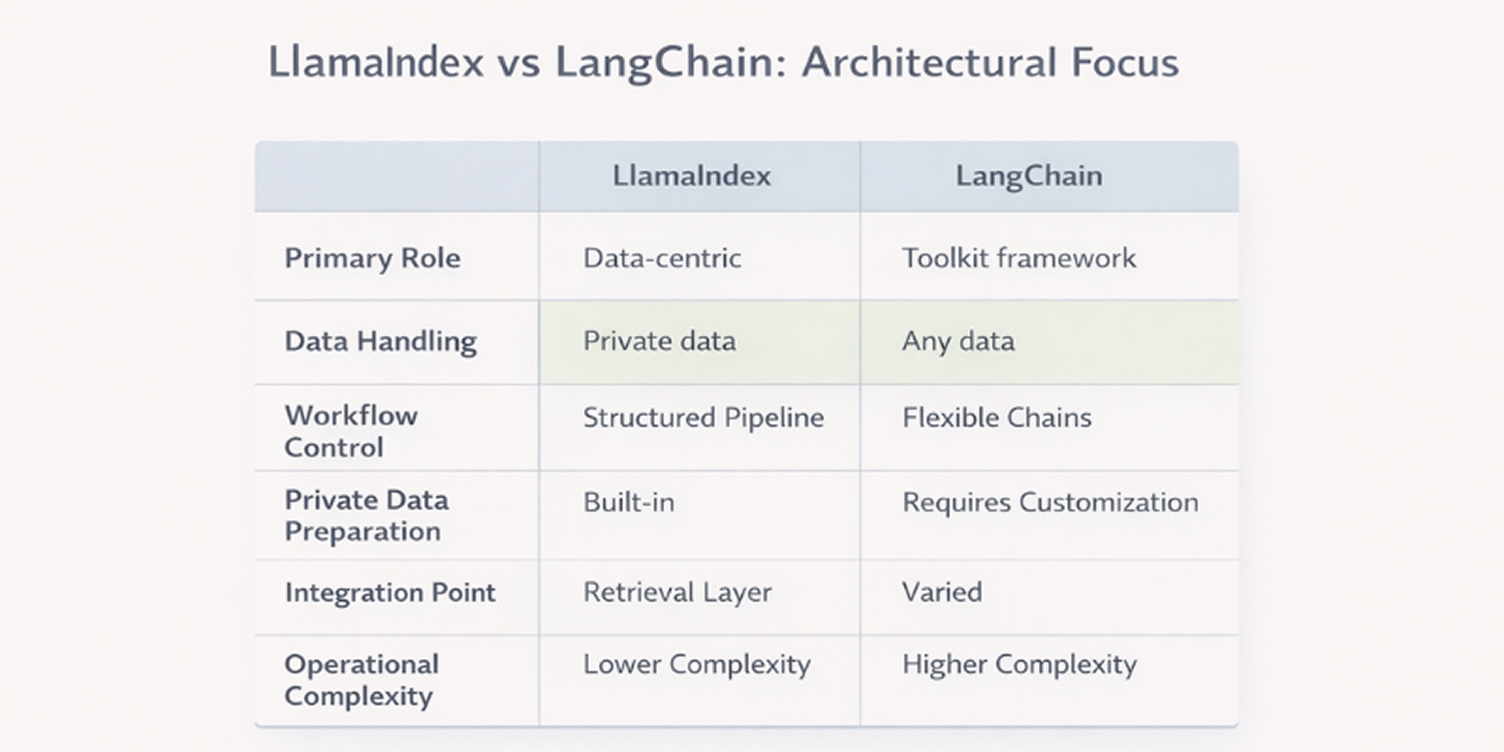
Teams evaluating LlamaIndex often compare it with LangChain and other LLM orchestration frameworks. While these tools are frequently used together, they are designed to solve different parts of the system. Understanding those differences helps avoid choosing the wrong layer for the problem at hand.
Design differences
LlamaIndex is built around one primary responsibility: preparing private data for use by language models through ingestion, indexing, retrieval, and context assembly.
LangChain, by contrast, focuses on orchestration. It provides abstractions for chaining model calls, managing tools, handling memory, and coordinating multi-step workflows.
In practical terms:
LlamaIndex specializes in data access and retrieval
LangChain specializes in workflow control and tool integration
This difference affects how each framework is introduced into an architecture and what problems it is expected to solve.
The distinction becomes clearer when comparing how each framework fits into a typical LLM application stack.
This separation is why many production systems use both frameworks together rather than choosing one over the other.
Typical use cases
LlamaIndex is commonly used when the main challenge is working with large volumes of private or structured data and delivering accurate context to a model.
LangChain is typically used when applications require complex execution flows, such as calling external tools, managing multi-turn state, or coordinating multiple model interactions.
Some teams also evaluate lighter-weight retrieval libraries or custom pipelines when their data sources are limited and system requirements are narrow.
Learning curve and operational complexity
LlamaIndex introduces concepts such as indexing strategies, retrieval configuration, and context management. These require some upfront design but remain relatively stable once deployed.
LangChain often involves a steeper learning curve due to:
Multiple abstractions for chains, agents, and tools
Rapidly evolving APIs
Greater surface area for debugging
The difference is less about difficulty and more about scope: one framework optimizes data handling, and the other optimizes control flow.
When teams combine both
In many production systems, LlamaIndex and LangChain are used together.
A common pattern is:
LlamaIndex manages ingestion, indexing, and retrieval
LangChain orchestrates how retrieved context is used across multi-step workflows
This separation allows each tool to operate within its strengths without overlapping responsibilities.
Related comparison material
A dedicated comparison article covering LlamaIndex and LangChain in depth is not currently available in this blog.
If one is published later, this section can link to that resource for a deeper breakdown of architectural trade-offs, performance considerations, and integration patterns.
When LlamaIndex is a good choice and when it isn’t
Adopting LlamaIndex is an architectural decision rather than a simple tooling choice. Its value depends on how much private data an application must handle, how frequently that data changes, and how tightly retrieval behavior must be controlled. In some systems it becomes core infrastructure. In others, it adds complexity without meaningful benefit.
Ideal scenarios
LlamaIndex fits best when applications rely on large volumes of internal data that cannot be embedded directly into prompts and must be queried dynamically.
It is most effective in situations such as:
Internal knowledge platforms spanning multiple systems
Document-heavy workflows like compliance, legal, or technical support
Products that require semantic search across thousands of files or records
In these cases, retrieval is not an optimization layer. It becomes central to whether the system produces accurate and defensible answers.
Team and infrastructure requirements
Using LlamaIndex means operating a retrieval pipeline in production, not just calling a model API.
Teams should be prepared to handle:
Data ingestion and index updates
Retrieval configuration and tuning
Basic monitoring around data freshness and failures
This typically requires backend engineering experience and familiarity with databases or vector stores. While the framework simplifies implementation, it does not remove the operational responsibility of running data-driven systems.
Data size and growth considerations
LlamaIndex provides the most value when datasets are too large to fit into a model’s context window or change frequently enough to make fine-tuning impractical.
As data volume grows, retrieval becomes necessary to control token usage, manage latency, and prevent irrelevant information from weakening response quality. When datasets are small and stable, these benefits are far less pronounced.
When simpler setups are often better
For early prototypes or narrowly scoped tools, a full retrieval framework is often unnecessary.
Simpler approaches are usually sufficient when:
The dataset is small and rarely updated
Queries are narrow and predictable
All users share the same data access level
In these situations, direct prompt injection or lightweight retrieval logic can achieve similar results with far less operational overhead.
Typical implementation workflow explained
Understanding the practical steps involved in adopting LlamaIndex helps teams estimate effort, ownership, and operational impact. While implementations vary by system, most production setups follow a similar sequence that moves from data planning to deployment.
Data source selection
The process usually starts with identifying which data the application should rely on. This may include internal documents, knowledge bases, databases, ticketing systems, or APIs.
Teams typically evaluate:
How frequently the data changes
Who is allowed to access it
Whether it is structured, unstructured, or mixed
These factors influence how ingestion is designed and how often indexes must be updated.
Index choice
Once data sources are defined, teams select how that data should be indexed. This decision affects retrieval accuracy, latency, and storage cost.
For smaller or highly structured datasets, simpler indexing approaches may be sufficient. For larger or more ambiguous text collections, semantic or hybrid indexing strategies are often preferred to improve relevance during retrieval.
LLM integration
After indexing is in place, the retrieval layer is connected to the chosen language model. At this stage, teams define how retrieved context is packaged into prompts and how model responses are handled by the application.
This step does not change the model itself, but it does determine how consistently the model receives useful, well-structured context across different types of queries.
Query flow design
Next, teams define how user requests move through the system. A typical flow includes:
Accepting the user query
Retrieving relevant data segments
Constructing the prompt
Generating the response
Designing this flow explicitly helps control latency, manage token usage, and ensure sensitive data is filtered before reaching the model.
Deployment basics
In production environments, LlamaIndex is deployed as part of the application backend rather than as a standalone service. This usually involves scheduling index updates, monitoring retrieval performance, handling failures gracefully, and ensuring data pipelines remain synchronized with upstream systems.
Over time, teams often refine indexing strategies and retrieval rules as data volume and usage patterns change. In many organizations, this layer becomes part of how teams approach developing and operating cloud-based applications, particularly when scaling, monitoring, and access control are required.
Performance, cost, and data security considerations
Once an LLM application moves beyond experimentation, performance, operating cost, and data handling become primary design constraints. Retrieval frameworks influence all three, which makes these factors critical when evaluating LlamaIndex for production use.
Latency drivers
Response time in retrieval-based systems is affected by more than the language model alone. Each request introduces additional steps such as searching the index, assembling context, and formatting prompts before inference even begins.
As datasets grow, retrieval performance becomes increasingly visible to users. Poor index design or remote storage can add noticeable delay even when the model itself responds quickly, making retrieval architecture a practical performance concern rather than a theoretical one.
Token and API cost behavior
Retrieval-based systems shift cost from training to inference.
Each request typically incurs:
Tokens for the constructed prompt
Tokens for the generated response
API charges from the model provider
More aggressive retrieval strategies increase prompt size, which directly raises per-query cost. Teams often need to balance retrieval depth against answer quality and budget limits.
Index size and storage impact
Indexing large document collections or databases increases storage requirements and operational complexity over time.
Larger indexes consume more disk or memory, take longer to rebuild or update, and can slow retrieval if poorly optimized. This makes data segmentation strategy and update frequency important variables in long-term cost and performance planning.
Privacy and data exposure risks
Retrieval pipelines introduce new paths for sensitive information to reach model inputs.
Common risks include:
Over-retrieval of irrelevant or restricted content
Leakage through model logs or telemetry
Misconfigured access controls
Production systems typically mitigate these issues by filtering data before indexing, enforcing permissions at retrieval time, and limiting what is transmitted to external model providers.
Cloud versus on-prem deployment tradeoffs
Where retrieval and inference run affects both security posture and system behavior.
Cloud deployments simplify scaling and access to managed models but raise concerns around data residency and third-party exposure. On-prem or private cloud setups provide tighter control over sensitive information but require more infrastructure management and operational overhead.
The appropriate choice usually depends on regulatory constraints, internal security policy, and tolerance for operational complexity.
Managing these trade-offs in production often falls to specialized cloud infrastructure engineering teams responsible for deployment automation, networking, and compliance controls.
Ecosystem, integrations, and best practices for production

LlamaIndex is rarely deployed in isolation. In production systems, it operates as part of a broader stack that includes data stores, model providers, and operational tooling. Understanding how these pieces fit together and which practices reduce failure rates over time is essential for building reliable applications.
Vector databases
Vector databases are commonly used when systems rely on semantic search across large text collections.
They store numerical embeddings and support similarity-based retrieval, using the same representation techniques commonly applied in semantic embedding pipelines for large language models. While not required for every deployment, they are often chosen for document-heavy or research-oriented workloads.
Typical considerations include query latency, storage growth, and how frequently embeddings must be recomputed as data changes.
Databases and file storage
Most applications also depend on traditional storage systems alongside vector indexes.
These may include relational databases for structured records, object storage for documents, or internal knowledge platforms. LlamaIndex typically reads from these sources during ingestion and may reference them during retrieval to fetch full content. The choice of storage backend often mirrors patterns seen in databases commonly used for machine learning and AI workloads.
Consistency between primary storage and indexes becomes important as data volumes increase, especially when updates are frequent.
LLM providers
LlamaIndex is model-agnostic and can be used with both hosted and self-managed language models.
Teams usually evaluate providers based on:
Model capability and context limits
API reliability and pricing
Data handling and retention policies
Switching providers rarely affects retrieval logic, but it can influence prompt design, latency, and operating cost.
Monitoring and observability tools
Retrieval-based systems introduce new failure modes that are not visible in simple prompt-based applications.
Monitoring typically focuses on:
Retrieval latency and timeouts
Index freshness
Prompt size and token usage
Error rates from model APIs
Without visibility into these metrics, performance degradation or silent data issues can persist unnoticed.
Chunking strategies
Chunking defines how documents are split into smaller units before indexing.
Chunks that are too large reduce retrieval precision, while chunks that are too small can lose important context. Most teams experiment with size and overlap settings based on document structure and query patterns.
This decision often has more impact on answer quality than model selection.
Index update practices
Indexes must evolve as data changes.
Common approaches include scheduled batch updates, incremental ingestion pipelines, or event-driven refreshes tied to upstream systems. The right strategy depends on how frequently data changes and how critical freshness is to the application.
Stale indexes are a common source of incorrect or outdated responses in production systems.
Evaluation and quality control
Unlike traditional software, LLM systems require ongoing validation after deployment.
Teams often track:
Answer relevance and completeness
Hallucination rates
Retrieval accuracy
User feedback patterns
Periodic evaluation against curated test queries helps detect regressions caused by data drift, indexing changes, or model upgrades.
Conclusion
Building LLM applications on private data is fundamentally a data engineering and system design problem, not just a model selection task. Accuracy, reliability, and security depend on how information is ingested, indexed, retrieved, and controlled long before the model generates a response.
LlamaIndex addresses this layer directly by structuring how private data is prepared and delivered to language models. It does not replace databases, vector stores, or LLM providers, but it provides the connective framework that allows these components to work together predictably in production environments.
Maintaining these systems over time typically requires experienced machine learning engineering teams who can manage retrieval quality, data pipelines, and ongoing model integration.
Understanding where LlamaIndex fits, what problems it solves, and what trade-offs it introduces enables more deliberate architecture decisions and more reliable AI systems over time.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us