



LLM Embeddings Explained: How They Work & Use Cases



LLM embeddings are numerical representations of language. They convert words, sentences, or entire documents into lists of numbers called vectors, placing text inside a high-dimensional mathematical space where meaning can be measured.
A single embedding may contain 384, 768, or 1536 values. Each value is a floating-point number, and together they define the text’s position in that space. Texts with similar meanings appear closer together, while unrelated concepts sit farther apart.
This idea powers much of modern AI and plays a central role in building LLM applications. Systems such as OpenAI ChatGPT, Google AI Overviews, Perplexity AI, recommendation engines, semantic search tools, and enterprise knowledge systems all rely on embeddings to understand relationships between language.
Words Into Numbers
Older systems often used one-hot encoding, where each word was represented as a mostly empty vector with a single active position in a fixed vocabulary. In that setup, “cat,” “kitten,” and “parliament” looked equally unrelated because the representation stored identity, not meaning.
Embeddings changed that by learning dense numerical representations where geometry reflects semantics. Similar words move closer together, related concepts form clusters, and meaningful relationships emerge. A classic example is:
king − man + woman ≈ queen
This illustrates that the model has learned patterns in language rather than memorizing isolated words.
Meaning as Position
You can think of embedding space as a semantic map. “Dog” and “puppy” appear near each other. “Machine learning” and “neural network” form another nearby cluster. “Astrophysics” and “cooking” are likely much farther apart.
These positions are learned from massive training data. By observing how language appears in context, models gradually organize concepts into a geometry that mirrors real-world usage.
Earlier models, such as Word2Vec, created one fixed vector per word. The word “bank” had the same representation whether referring to money or a riverbank.
Modern LLMs use contextual embeddings, in which the meaning changes with the surrounding text. Models like BERT and GPT generate different vectors depending on usage. “Bank” in a finance sentence differs from “bank” in a geography sentence.
Context awareness is one of the biggest reasons modern embeddings perform far better in search, retrieval, translation, recommendation, and real-world language understanding.
How LLM embeddings are created step by step
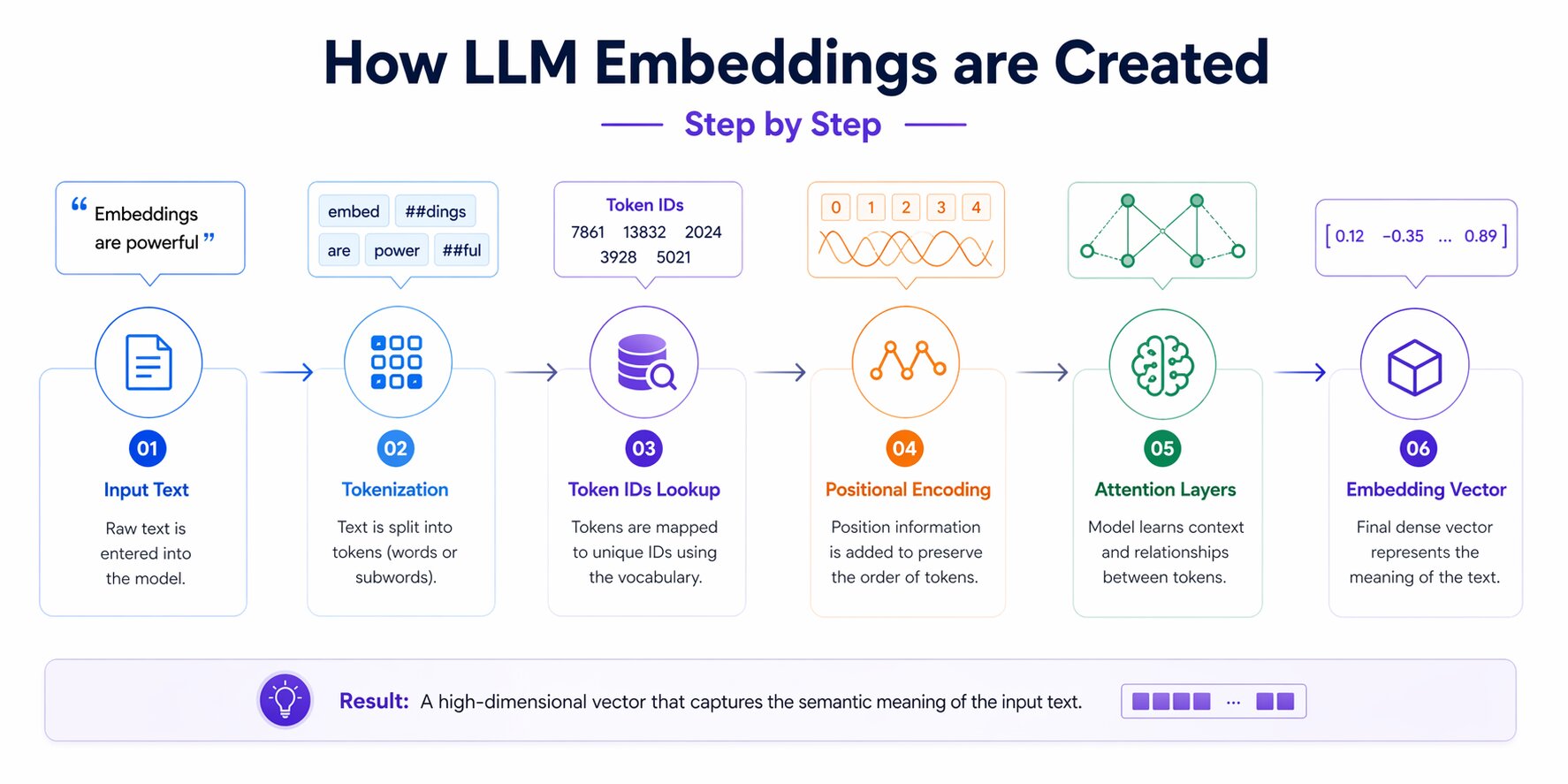
The pipeline from raw text to a usable vector involves several distinct stages, each building on the last. Most explanations skip the middle steps. This one does not.
When you pass a sentence to an embedding model, it does not read the text the way a person would. It runs the input through a structured sequence tokenization, lookup, positional encoding, and attention-based refinement, before producing the final vector. Each stage shapes the quality and meaning of the output.
Tokenization
The first step is breaking the input text into smaller units called tokens. Tokens are not always full words. Modern tokenizers, BPE (Byte Pair Encoding) used by GPT, WordPiece used by BERT, split text at the subword level.
The choice of tokenizer and architecture also depends on which programming languages and frameworks your team works with.
The sentence "embeddings are powerful" might tokenize into ["embed", "##dings", "are", "power", "##ful"]. This matters because it allows the model to handle words it has never seen before by decomposing them into known subword units.
It also means a single word can become multiple tokens, which affects how you count input length and budget your context window.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize("embeddings are powerful")
# Output: ['em', '##bed', '##dings', 'are', 'powerful']
print(tokens)Token IDs and the vocabulary lookup table
Once tokenized, each token gets converted into an integer ID, its position in the model's fixed vocabulary. BERT's vocabulary has roughly 30,000 entries. GPT-4's tokenizer handles around 100,000 tokens.
Example token IDs:
"embed" → 7861
"##dings" → 13832
"are" → 2024
"powerful" → 3928Positional encoding
A detail many readers miss is that transformer models process tokens in parallel rather than one word at a time. Without some notion of order, the model would treat “dog bites man” and “man bites dog” as the same set of tokens, even though the meanings are completely different.
Positional encoding solves this by adding sequence-order information to each token’s initial vector. In the original Transformer architecture, this was done using sine and cosine patterns at different frequencies. Modern models such as Llama 3 and Google Gemini often use Rotary Positional Encoding (RoPE), which captures relative token positions more effectively and tends to perform better on longer contexts.
final_token_vector = token_embedding_vector + positional_encoding_vector
This combined vector is what feeds into the attention layers.
Attention and Contextual Meaning
The attention mechanism is what transforms the initial token vectors into rich, context-aware embeddings. For each token, attention computes a weighted sum of all other tokens in the sequence, weighted by how relevant each other token is to understanding the current one.
For the word "bank" in "she deposited money at the bank," the attention mechanism learns to assign high weight to "deposited" and "money" — pulling their semantic signal into the representation of "bank" and steering it toward the financial meaning. Change the context to "she sat by the river bank," and attention shifts to "river" and "sat," producing a meaningfully different final vector.
Modern LLMs stack dozens of these attention layers. Each layer refines the representations further. By the time you extract the final embedding, it encodes not just the token's base meaning but the full semantic context of the passage around it.
The final embedding may be produced by averaging token vectors or selecting a designated output representation, depending on the model.
Choosing Embedding Models vs Generative LLMs
Embedding models and generative language models serve different purposes, though they often use similar architectures. Generative systems range from large models to (SLMs) small language models built for greater efficiency, lower cost, or on-device use.
Large language models such as OpenAI GPT-4o, Anthropic Claude, and Google Gemini are designed for tasks like text generation, summarization, and reasoning.
Embedding models, by contrast, are built to convert text into vector representations that can be used for semantic search, retrieval, clustering, and recommendation systems. Examples include OpenAI’s text-embedding-3-large, Voyage AI’s voyage-3, and BAAI’s BGE.
Because they focus on a narrower task, embedding models are typically lighter, faster, and less expensive to run. In production environments such as RAG systems or search platforms, dedicated embedding models are usually the practical choice for both performance and cost efficiency.
Types of LLM Embeddings and When to Use Them
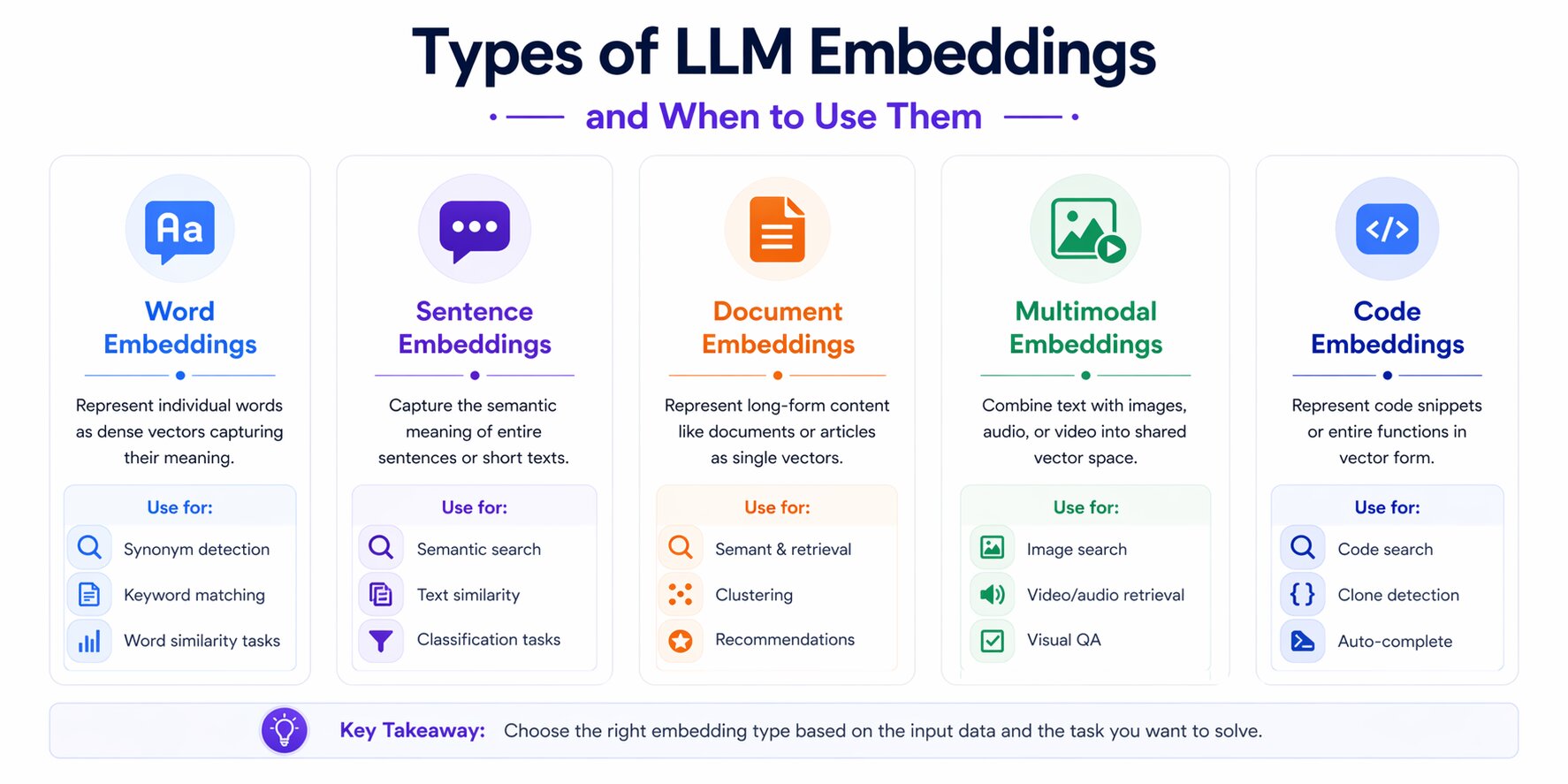
Embedding models and generative language models serve different purposes, even though they are often built on similar architectures. Generative models range from large language models to small language models designed for faster or lower-cost deployment.
Some models are built to represent individual words, while others are better suited for sentences, full documents, source code, or multimodal data such as images paired with text.
As embedding systems have evolved, they have moved from fixed word vectors to context-aware language models, then to sentence and document representations, and more recently to multimodal and domain-specialized systems. Understanding these categories helps you choose the most practical approach for your application.
Word embeddings
Early embedding models laid the foundation for modern semantic search and language representation by assigning each word a fixed numerical vector based on patterns in training data.
Word2Vec (2013, Google) introduced the skip-gram and CBOW architectures, both of which learn word vectors by predicting surrounding context words.
The resulting embeddings captured strong semantic relationships: synonyms cluster together, analogies hold arithmetically, and they helped lay the groundwork for later advances in artificial neural networks for language understanding.
GloVe (Stanford, 2014) took a different approach: instead of local context windows, it factorized the global word co-occurrence matrix across an entire corpus. This gave better performance on analogy tasks and broader semantic relationships.
FastText (Meta, 2016) extended Word2Vec by representing words as bags of character n-grams. This made it robust to misspellings and morphologically rich languages: "running" and "runner" share a subword structure that FastText explicitly captures.
The key limitation across all three: one vector per word, no context sensitivity. These models are largely retired from production NLP but remain relevant for lightweight deployments and teaching the fundamentals.
Contextual word embeddings
Contextual embeddings marked a major shift from static word vectors by allowing the same word to carry different meanings depending on the surrounding text.
ELMo (Allen Institute, 2018) was the first widely adopted contextual embedding model. It used a bidirectional LSTM to generate token representations that changed with context; the same word got different vectors in different sentences.
BERT (Google, 2018) transformed the field. Its bidirectional transformer architecture trained on masked language modeling, predicting randomly hidden tokens, produced embeddings that captured left and right context simultaneously. BERT's embeddings became the foundation for dozens of downstream NLP tasks and remain in active use in enterprise systems today.
GPT-style models use unidirectional (left-to-right) attention, which makes them better suited for text generation than embedding. When people extract embeddings from GPT models, they typically pool the hidden states from the final layer.
For most embedding tasks in 2026, pure BERT-style models have been superseded by larger, better-trained descendants, but understanding BERT is still essential because the architecture underpins almost everything that follows.
Sentence embeddings
Word-level vectors are useful, but many tasks require understanding the meaning of a complete sentence or paragraph. Search systems, question matching, and document retrieval usually work better when each passage is represented by a single embedding.
Sentence-BERT (SBERT) fine-tunes BERT on sentence-pair tasks using siamese and triplet network structures. The result: semantically similar sentences produce vectors that are close together, making it possible to use cosine similarity directly on sentence embeddings for tasks like semantic search and paraphrase detection. SBERT-based models are the backbone of many open-source embedding deployments in 2026.
Universal Sentence Encoder (USE) by Google offers two architectures: a transformer variant for higher accuracy and a Deep Averaging Network (DAN) variant for speed. USE is trained on a diverse mixture of tasks, making it general-purpose and robust.
For most production search and RAG systems, sentence embedding models are the default choice because they produce one vector per chunk of text, which is exactly what vector database retrieval requires
Document embeddings
When the unit of comparison is an entire document rather than a sentence, document embedding models apply.
Doc2Vec extended Word2Vec by adding a paragraph vector, a document-level representation trained alongside word vectors. It can represent arbitrarily long documents as a single fixed-size vector.
InferSent (Meta, 2017) used supervised learning on natural language inference data to train a bidirectional LSTM that produces general-purpose sentence and document representations. It was notable for showing that supervised training signals produced better embeddings than purely self-supervised approaches at the time.
In 2026, most teams handle long documents by chunking them into passages and embedding each chunk separately, rather than embedding the whole document as one unit. This approach integrates better with vector database retrieval and preserves local context. True document-level embedding is used primarily for document-level classification and clustering tasks.
Multimodal embeddings
Many modern systems need to work across more than one type of data. Multimodal embeddings are designed to represent text, images, and increasingly audio or video within the same vector space, making cross-format search and retrieval possible.
CLIP (OpenAI, 2021) is the defining example. It trains a text encoder and an image encoder jointly using contrastive learning on 400 million image-text pairs from the internet, extending earlier image advances built with convolutional neural networks.
The result: the text "a dog running in a park" and a photograph of a dog running in a park produce vectors that are close together in the shared embedding space. This enables zero-shot image classification, image search from text queries, and cross-modal retrieval.
VisualBERT and UNITER extend the BERT architecture to jointly process image regions and text tokens, enabling tasks like visual question answering and image captioning.
In 2026, multimodal embeddings are no longer experimental; they are standard infrastructure in e-commerce visual search, content moderation, medical imaging AI, and any system that needs to reason across text and images together.
Domain-specific embeddings
General-purpose embeddings trained on internet text perform poorly on specialized domains because the language, vocabulary, and semantic relationships are fundamentally different. A general model trained on Common Crawl has seen very little medical literature, legal text, or source code in context.
ClinicalBERT fine-tunes BERT on clinical notes from the MIMIC-III database. It outperforms general BERT on clinical NLP tasks by a significant margin because it has internalized the vocabulary and conventions of medical documentation, making it well suited for AI applications in healthcare.
SciBERT uses a custom scientific vocabulary and trains on 1.14 million papers from Semantic Scholar, making it well-suited for academic paper search and scientific information extraction.
CodeBERT (Microsoft) trains on code paired with natural language documentation across multiple programming languages. It powers code search tools that retrieve relevant functions from natural language queries.
If your application operates in a specific domain, using or fine-tuning a domain-specific embedding model is almost always worth the effort. The performance gap over general models in specialized domains is substantial
LLM Embedding Applications Across Industries and Use Cases
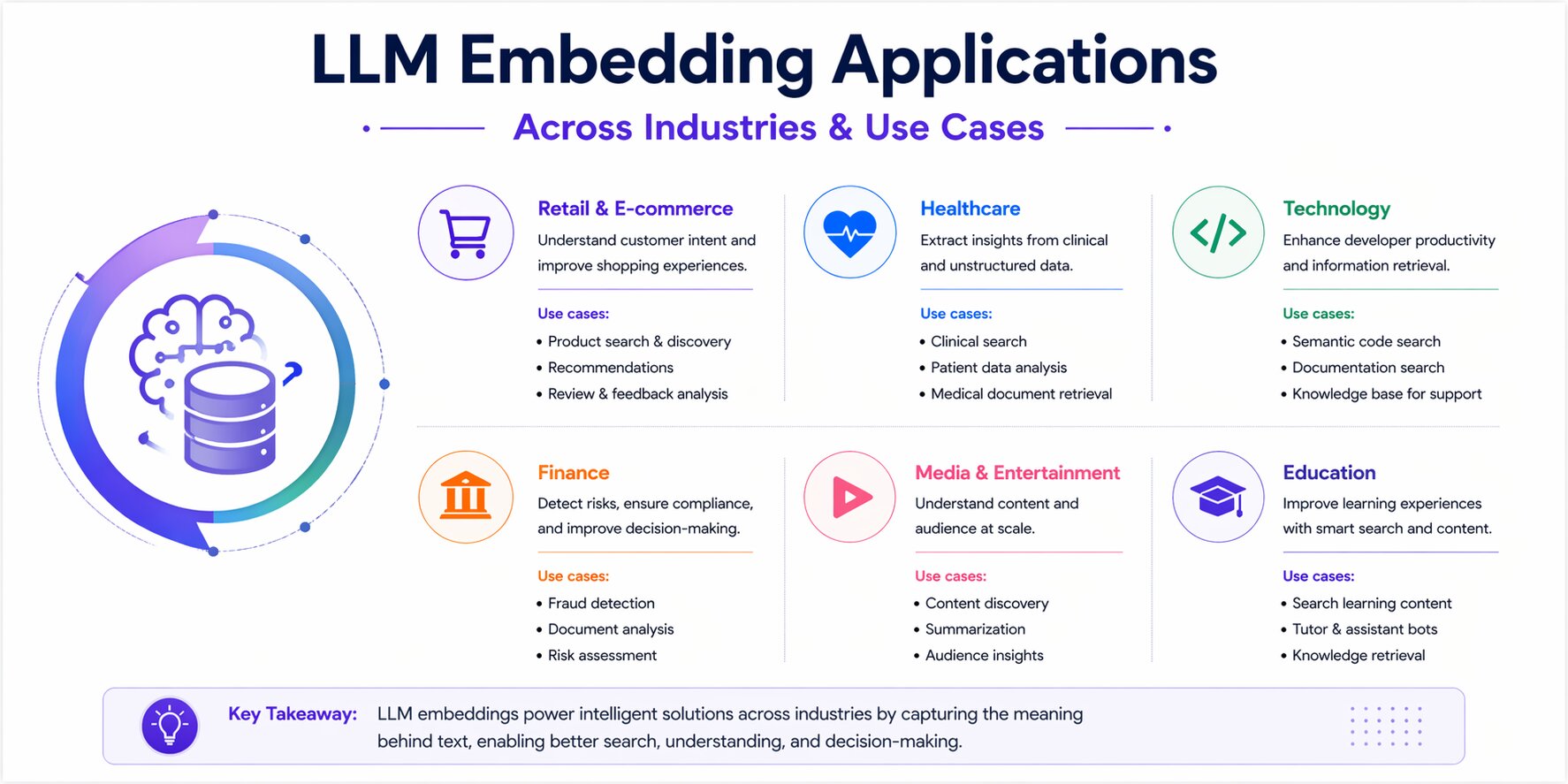
Embeddings matter because they solve practical problems that traditional keyword systems often handle poorly. They help machines understand meaning, compare related content, and retrieve relevant information at scale.
That makes them useful across search, recommendations, classification, question answering, and modern AI systems. The application pattern you choose also affects downstream decisions such as model selection, storage design, indexing strategy, and retrieval speed.
Semantic Search
Traditional search matches exact terms. Semantic search matches meaning.
A user searching for “how do I restart my account” should still find documentation about account recovery, even if those exact words do not appear in the source text.
The common approach is simple: documents are embedded during indexing, the user query is embedded at search time, and the nearest matching vectors are retrieved.
This allows search systems to handle synonyms, paraphrases, and varied phrasing without relying entirely on manual keyword rules.
Semantic search has become a common capability across enterprise software, support centers, internal knowledge bases, and developer documentation.
Recommendation Engines
Recommendation systems often place users, products, or content items in the same vector space so similarity can be measured directly.
A user who regularly reads articles about distributed systems may appear closer to content about Kubernetes, databases, or system design than unrelated topics.
Spotify, Netflix, LinkedIn, and many SaaS platforms use embedding-based recommendations to improve discovery and engagement.
The same pattern is widely used for product suggestions, content feeds, and customer success workflows.
Text Classification and Sentiment Analysis
Embeddings are powerful features for classification tasks. Rather than training a classifier on raw text, which requires large labeled datasets, you can embed your text, then train a lightweight classifier (logistic regression, SVM, or a small neural network) on the embedding vectors.
This dramatically reduces the labeled data requirement because the embedding model has already done the heavy lifting of encoding semantic meaning. A classifier trained on 500 labeled examples using BERT embeddings often outperforms a keyword-based classifier trained on 10,000 examples.
For sentiment analysis specifically, the embedding naturally clusters positive, negative, and neutral text in different regions of the vector space, and the classifier learns boundaries between those regions.
Duplicate Detection and Similarity Clustering
Legal discovery, content moderation, customer support ticket management, and academic integrity tools all need to identify documents that say the same thing in different words.
Embeddings make this tractable at scale. Embed all documents, compute pairwise similarities, and flag pairs above a threshold. For collections too large for pairwise comparison, use approximate nearest neighbor (ANN) indexes to find candidates efficiently.
Near-duplicate clustering, grouping documents that cover the same topic even if not verbatim copies, is equally valuable for content deduplication in knowledge bases and eliminating redundant support tickets before routing.
Question answering systems and chatbots
Modern question answering systems use embeddings to retrieve relevant context before generating an answer. The flow: embed the question, retrieve the most relevant passages from a knowledge base, pass those passages to an LLM as context, and generate a grounded response.
Without the embedding-based retrieval step, the LLM generates answers from training data alone, which may be outdated, incorrect, or hallucinated. The retrieval step grounds the generation in verified, current information. This is the RAG pattern, covered in depth in the vector databases section.
Modern NLP chatbots also use embeddings for intent classification, mapping user messages to predefined intents without relying on exact keyword matches. This makes chatbot routing more flexible and natural for end users.
Code search and code similarity
Embedding models trained on code, CodeBERT, UniXcoder, and the code-specific variants of text-embedding-3 enable natural language queries against codebases. A developer asking "function that parses JSON and handles null values" can retrieve the relevant implementation across a repository of thousands of files.
GitHub Copilot, Sourcegraph Cody, and similar tools use code embeddings to surface relevant context from large codebases. The same mechanism powers plagiarism detection in academic contexts and license compliance checking in open-source software.
Code embeddings are now widely used in developer tooling. Many AI coding assistants rely on them to provide repository-aware context rather than depending only on model training data.
RAG pipelines
Retrieval-Augmented Generation (RAG) has become one of the most widely used architectures for knowledge-intensive AI applications. It addresses a core limitation of LLMs by allowing access to external data beyond what was available during training.
The pipeline: your documents are chunked, embedded, and stored in a vector database. At inference time, the user's query is embedded, the most relevant document chunks are retrieved via cosine similarity, and those chunks are injected into the LLM's prompt as context.
The LLM generates a response grounded in those retrieved documents.
The quality of the RAG system depends heavily on embedding quality. Poor embeddings retrieve irrelevant context, causing the LLM to generate wrong or irrelevant answers.
Good embeddings, properly sized chunks, an appropriate model, and domain-matched, retrieve exactly the passages that contain the answer.
This is why embedding model selection and RAG architecture are inseparable topics for any team building production AI applications.
Choosing the Right Embedding Model
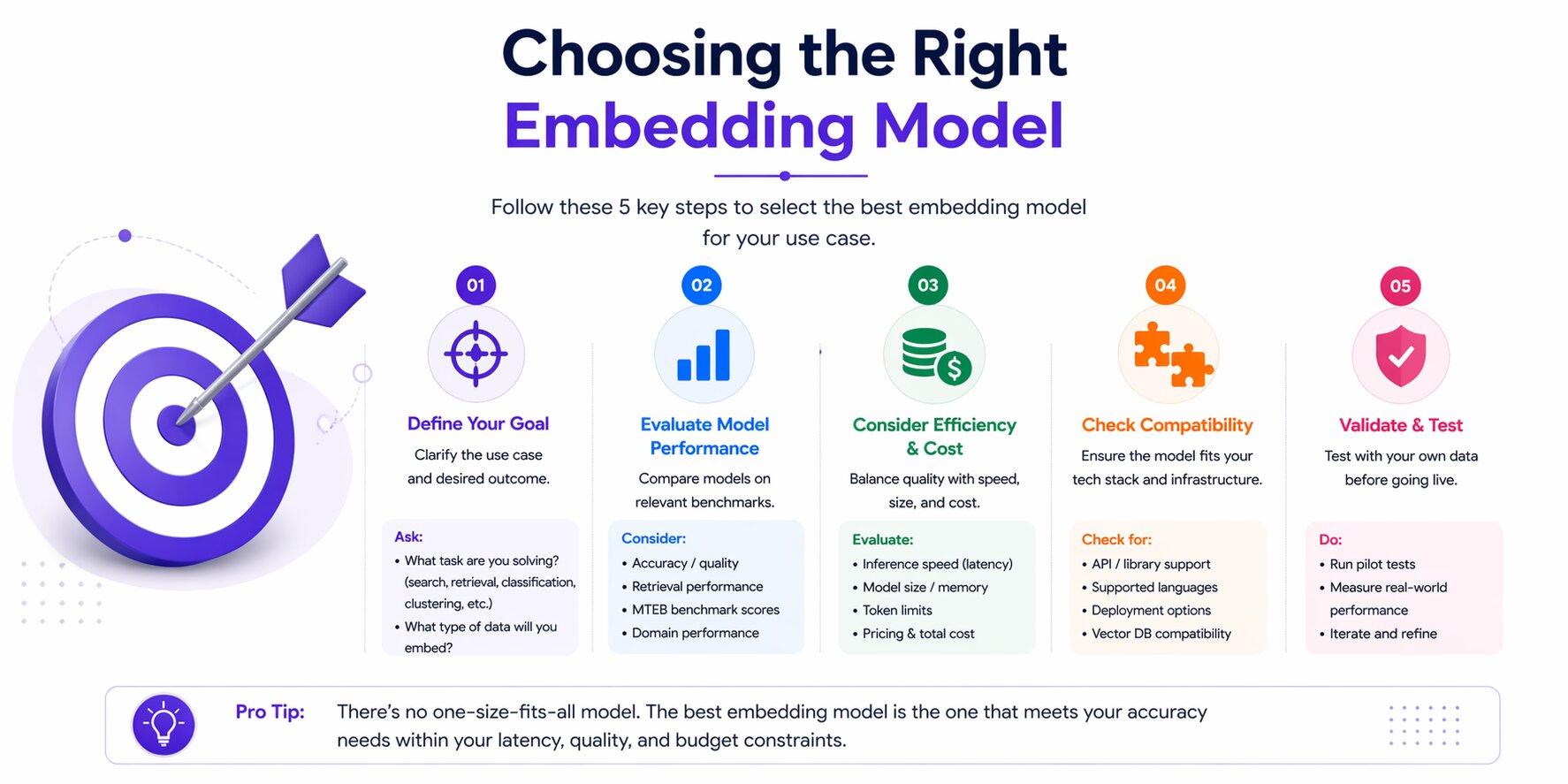
Selecting an embedding model is one of the most important decisions in any search, retrieval, or RAG system. Many teams start with the model used in a tutorial or quick demo, then discover later that it does not match their performance, cost, or latency requirements.
The right choice depends on several factors: your task, expected query volume, response-time targets, data privacy needs, language coverage, and whether your domain uses specialized terminology.
Your choice of infrastructure also matters, as the tools used for LLM-based applications can shape how easily you upgrade, replace, or scale embedding models later. There is no universal best model, but there is a practical way to evaluate the options.
The MTEB Leaderboard
The Massive Text Embedding Benchmark (MTEB) is the standard evaluation framework for embedding models, maintained on Hugging Face.
It evaluates models across 56 datasets and 8 task categories: retrieval, clustering, classification, reranking, semantic similarity, summarization, pair classification, and bitext mining.
A model that tops the overall MTEB leaderboard may underperform on your specific task or domain. Always look at task-specific scores, not just the aggregate.
Things to read on the leaderboard for any model:
Retrieval score: Most relevant for RAG and semantic search
Max tokens: How much text can be embedded in one call
Embedding dimensions: Affects storage and retrieval cost
Model size: Affects inference latency and hosting cost
License: Relevant for commercial deployment
Embedding Dimensions
Dimension count affects storage requirements, retrieval speed, and indexing cost. Larger vectors can preserve more information, but they also consume more memory and increase infrastructure overhead.
For most production RAG systems, 768 or 1024 dimensions hit the right balance. 384-dimension models all-MiniLM-L6-v2 are appropriate when you are embedding millions of documents, and latency or storage cost is a binding constraint.
Using 3072 dimensions without a compelling accuracy requirement is typically wasteful.
After comparing dimensions and performance trade-offs, the next step is evaluating the model ecosystem itself.
In practice, most teams choose between open-source models they can run themselves and API-based models managed by external providers.
Open-Source Models
Open-source embedding models have improved significantly and are now strong production choices, especially for teams that want self-hosting, cost control, or stricter data governance.
For many use cases, they now match or exceed proprietary options at zero marginal cost.
all-MiniLM-L6-v2 (384 dims): The workhorse for fast, good-enough embeddings. 6 layers, tiny footprint, runs comfortably on CPU. Not competitive with modern models on MTEB, but still excellent for prototyping and cost-sensitive production.
BAAI/bge-large-en-v1.5 (1024 dims): Strong retrieval performance, widely used in enterprise RAG. Supports instruction-prefixed queries for improved retrieval accuracy.
intfloat/e5-large-v2 (1024 dims): Competitive with BGE on most retrieval tasks. Uses a simple "query: " / "passage: " prefix convention that improves retrieval accuracy.
nomic-ai/nomic-embed-text-v2 (768 dims): First embedding model using Mixture-of-Experts architecture. Trained on 1.6 billion pairs across ~100 languages. Strong multilingual performance.
mixedbread-ai/mxbai-embed-large-v1 (1024 dims): Top MTEB scores among fully open models (Apache 2.0). Strong for both English retrieval and clustering.
API-Based Models
Managed APIs are a practical option when teams want strong performance without operating their own infrastructure.
OpenAI text-embedding-3-small / 3-large: The standard. Well-documented, easy to integrate, strong performance. MRL support for flexible dimensions. The safe default for teams without specialized requirements.
Voyage AI voyage-3 / voyage-3-large: Consistently competitive with or superior to OpenAI on MTEB retrieval benchmarks. Particularly strong on domain-specific retrieval. Anthropic-backed. Worth evaluating if retrieval accuracy is critical.
Google Gemini Embeddings (gemini-embedding-001): 3072 dimensions, 8192 token context window, strong multilingual performance. Best choice for teams already on Google Cloud infrastructure.
Cohere Embed v3: Specialized in multilingual embeddings and document compression. Strong for international deployments.
Latency, Cost, and Throughput Trade-Offs
Model quality is only part of the production decision. Operational constraints often matter just as much.
API-based services reduce infrastructure overhead but add recurring usage costs and vendor dependency. Self-hosted GPU deployments can become cost-efficient at scale, while CPU deployments may be sufficient for smaller models or moderate traffic.
For lower-volume systems, APIs are often the simpler choice. At higher usage volumes, self-hosting can become more economical.
API-based models typically respond in 50–200 ms per call, depending on batch size. Costs are usually token-based, with no infrastructure to manage, though rate limits may apply.
Self-hosted GPU deployments can reach 5–20 ms per call on high-performance hardware such as an A100 for 1024-dimensional models. They involve higher fixed infrastructure costs, but the marginal cost can be low at scale while offering full data control.
Self-hosted CPU deployments often range from 50–500 ms, depending on model size. They are practical for smaller models, particularly where GPU infrastructure is unnecessary.
Serverless GPU platforms such as Modal, Replicate, and RunPod offer a middle ground, providing pay-per-inference GPU performance without owning dedicated hardware.
Match the Model to the Task
Different workloads reward different model strengths. A model that performs well for retrieval may not be the best choice for clustering or sentence similarity, so selection should be tied to the actual task.
Retrieval (RAG, semantic search): Prioritize MTEB retrieval scores. Use instruction-prefixed models (BGE, E5) when your queries are short but documents are long. Consider cross-encoders for re-ranking.
Classification: Prioritize MTEB classification scores. Smaller models often perform comparably to larger ones here because the classifier learns task-specific decision boundaries on top of the embeddings.
Clustering: Prioritize MTEB clustering scores. Models trained with more diverse data tend to produce better-separated clusters. UMAP + HDBSCAN is the standard clustering pipeline in 2026.
Semantic similarity: Prioritize MTEB STS (semantic textual similarity) scores. SBERT-based models typically excel here.
In practice, the most effective model is usually the one that performs best on the specific task you need to solve, not the one with the highest overall benchmark score, since data processing in ML often needs to account for scale, latency, and domain-specific quality requirements.
Limitations and Challenges of LLM Embeddings

Embeddings are powerful, but they are not flawless. Many production issues, poor retrieval results, hidden bias, rising infrastructure cost, or declining relevance over time come from limitations that are well understood but often overlooked during implementation.
These are practical engineering challenges rather than theoretical edge cases. Knowing them early helps teams design stronger search, recommendation, and RAG systems.
Bias in Training Data
Embedding models learn from human-generated text. Human text carries historical biases in gender, race, geography, occupation, and countless other dimensions. Because embeddings learn statistical patterns from this data, those biases become encoded into the vector space.
Classic example: Word2Vec embeddings trained on Google News placed "man" closer to "doctor" and "woman" closer to "nurse" reflecting historical patterns in the training corpus, not ground truth about medical professions. More modern models trained on more carefully curated data show reduced but not eliminated bias.
The practical consequence: embedding-based systems used for hiring, loan decisions, content recommendation, or any consequential application can perpetuate and amplify historical inequalities. Bias in embeddings → biased retrieval → biased AI output.
Detection tools like WEAT (Word Embedding Association Test) can measure bias along specific dimensions. Mitigation approaches include debiasing algorithms, adversarial training, and careful curation of fine-tuning data.
Limited Interpretability
Individual embedding dimensions usually do not have clear human-readable meanings. A single value inside a large vector cannot be cleanly labeled as “technical content,” “positive sentiment,” or another direct concept.
This makes debugging difficult. When a retrieval system returns the wrong result, teams cannot inspect the vector in the same way they can inspect keyword matches in a traditional search engine.
For most production systems, evaluation still depends on outcome testing: whether the model retrieves the right results on representative queries.
Cost at Scale
Generating embeddings is not free. At a small scale (thousands of documents), it is negligible. At a large scale (millions of documents, real-time ingestion pipelines), the cost, in time, compute, and money, becomes significant.
Specific cost drivers:
Embedding generation: GPU time for local models; API cost for managed services
Vector storage: 1536-dimensional float32 vectors consume 6KB each — 10 million documents = 60GB of raw vector data before indexing overhead
ANN index build time: HNSW indexes can take hours to build for very large collections
Query latency at scale: Without proper sharding and replication, retrieval latency degrades under concurrent load
Standard mitigations: quantization (8-bit or 4-bit vectors reduce storage by 4–8x with small accuracy loss), dimensionality reduction via MRL, tiered storage (hot vs cold index partitions), and horizontal sharding across multiple vector database instances.
Long-Text Limits
Most embedding models have a maximum input token limit. all-MiniLM-L6-v2 handles 256 tokens. BERT-based models cap at 512.
Even models with longer limits (8192 tokens for some modern models) can lose quality on very long inputs because attention mechanisms struggle to maintain coherent representations across very long sequences.
The practical consequence: you cannot embed a 50-page contract as a single vector and expect high-quality retrieval. You must chunk it. Chunking strategy size, overlap, and boundary detection have a significant impact on retrieval quality.
Poor chunking (splitting in the middle of a paragraph, using chunks that are too small to carry context) degrades performance just as much as a weak embedding model.
Semantic gaps
Embedding similarity does not equal factual relevance. Two sentences can be semantically close (same topic, similar vocabulary) but factually opposed. "The vaccine is safe and effective" and "The vaccine is not safe or effective" will produce vectors that are relatively close in most embedding models, because they share nearly identical tokens and topics.
For factual question answering, this creates a retrieval failure mode where the system retrieves confident-sounding but incorrect information. The embedding system does not understand truth; it understands semantic proximity.
Mitigation: cross-encoder re-ranking, which processes the query and each retrieved document together, can better distinguish relevant from plausible-but-wrong results.
Combining retrieval with structured knowledge sources (knowledge graphs, databases) for factual queries adds a layer of verification. In high-stakes applications, human review of generated answers remains the safest backstop.
The Future of Embeddings in AI
Embedding systems are evolving quickly, with progress focused on flexibility, efficiency, and broader real-world use. While the core idea of representing meaning as vectors remains the same, newer models are becoming easier to deploy, more capable across formats, and better suited to global applications.
This matters because decisions made today, model choice, storage design, multilingual support, and retrieval architecture, should remain practical as the ecosystem advances.
Multimodal Models
Text-only embeddings are increasingly seen as a special case rather than the default. The leading embedding systems handle text, images, audio, and code within a single unified vector space.
OpenAI's CLIP and its successors embed text and images such that "a red sports car" and a photograph of a red sports car are genuinely close in vector space. Newer systems like Google's Gemini Embeddings and Meta's ImageBind extend this to audio, video, and 3D representations.
The practical consequence for builders: applications that once required separate text and image pipelines can now use a single embedding model and a single vector database, dramatically simplifying architecture.
E-commerce visual search, medical imaging combined with clinical text, and multimodal content moderation are all benefiting from this convergence.
Embeddings for Agent Memory
Agentic AI systems need memory across long-running tasks, not just one-time retrieval.
Embeddings are increasingly used to store prior interactions, observations, retrieved knowledge, and planning steps inside vector memory systems. Retrieval quality directly affects how well agents recall useful past context.
As agents scale, teams also need efficient indexing, memory pruning, and recency-aware retrieval.
Matryoshka for Flexible Dimensions
Matryoshka Representation Learning (MRL) allows a larger embedding to contain smaller, useful versions inside it.
This means one model can serve multiple performance tiers: full dimensions for highest-accuracy indexing, smaller dimensions for faster queries, lower storage cost, or latency-sensitive workloads.
For production teams, this creates more flexibility without retraining separate models.
Smaller Models at the Edge
Not every application runs in a cloud data center with abundant GPU resources. Mobile applications, IoT devices, air-gapped enterprise systems, and latency-sensitive real-time applications need embeddings that run on constrained hardware.
This demand has driven a generation of highly compressed embedding models. all-MiniLM-L6-v2 (22MB) runs on CPU with acceptable latency. Newer distilled models in 2026 push further, models under 50MB with 384 dimensions that run in under 10ms on modern smartphone hardware.
Quantization—converting float32 weights to int8 or even int4—reduces model size by 4–8x with minimal accuracy loss. Knowledge distillation - where a small model learns from a larger one- helps compact models perform above their size class. PEFT methods such as LoRA further reduce deployment cost by adapting models with only a small number of trainable parameters.
As AI moves to the edge, embedding models are moving with it. Federated learning approaches allow edge devices to fine-tune embedding models on local data without that data leaving the device, directly addressing data privacy concerns for consumer and healthcare applications.
Cross-Lingual by Design
English has dominated NLP research and most commercial embedding models. That is changing rapidly. In 2026, cross-lingual embedding models, trained on text from dozens of languages within a shared vector space, make it possible to retrieve documents in one language using a query in another.
The business impact: a single embedding index can serve users across languages without a translation infrastructure. A customer support system can retrieve English documentation for a French query, or a legal search platform can operate across jurisdictions without separate language-specific indexes.
For any product targeting global users with international audiences, cross-lingual embedding evaluation should be a standard part of model selection. The performance gap between monolingual and multilingual models on English-only tasks has narrowed significantly, making the multilingual option the pragmatic default for most new systems.
Conclusion
LLM embeddings have quietly become one of the most important components in modern AI. They allow systems to move beyond exact keywords and work with meaning, similarity, and context at scale.
That shift is what makes better search, smarter recommendations, stronger retrieval pipelines, and more useful AI assistants possible. While they often operate in the background, many visible AI experiences depend on them working well.
Understanding embeddings is not only about knowing how vectors are created. It is about knowing when to use them, how to choose the right model, where their limits appear, and how to design systems around them effectively.
The models will continue to improve, but the core value remains the same: helping machines connect related information in ways traditional systems cannot.
For anyone building products that need to search, organize, compare, or retrieve information intelligently, embeddings are no longer an advanced concept. They are part of the modern AI foundation.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us