



Full Guide to Artificial Neural Networks and Their Applications in AI


An artificial neural network (ANN) is a computational system designed to process information the way the human brain does through a network of interconnected nodes that pass signals to one another, strengthen useful connections, and gradually learn to produce accurate outputs from raw input data.
In simpler terms, it is software that learns from examples rather than being explicitly programmed with rules.
Instead of a developer writing "if the image has pointy ears and whiskers, it is a cat," a neural network is shown thousands of cat photos, makes mistakes, gets corrected, and eventually figures out the pattern on its own. That process of learning from data through trial and error is what makes neural networks so powerful and so unlike traditional software.
Importance of ANN in Modern AI
Artificial Neural Networks (ANNs) are central to modern AI because they enable systems to learn directly from data rather than rely on predefined rules. They sit at the core of machine learning and power deep learning models that handle complex tasks like image recognition, language understanding, and pattern detection.
This ability to learn and improve from data makes neural networks far more effective for real-world problems where patterns are not explicitly defined.
Traditional programming relies on fixed rules and predefined logic, which works well for simple, structured problems but fails when dealing with real-world complexity. Modern challenges, like understanding language, detecting fraud, or recognizing images, require systems that can adapt and learn dynamically.
Neural networks solve this by learning from examples rather than instructions, adjusting their internal parameters over time, and uncovering patterns that rule-based systems cannot capture.
This is why neural networks are central to real-world AI applications today, powering everything from recommendation systems and virtual assistants to medical diagnostics and financial predictions.
They enable automation at scale, improve decision-making accuracy, and drive innovation across industries. As data continues to grow, neural networks have become not just important but essential for building intelligent, scalable, and future-ready AI systems.
Understanding the Three Layer Architecture of an ANN
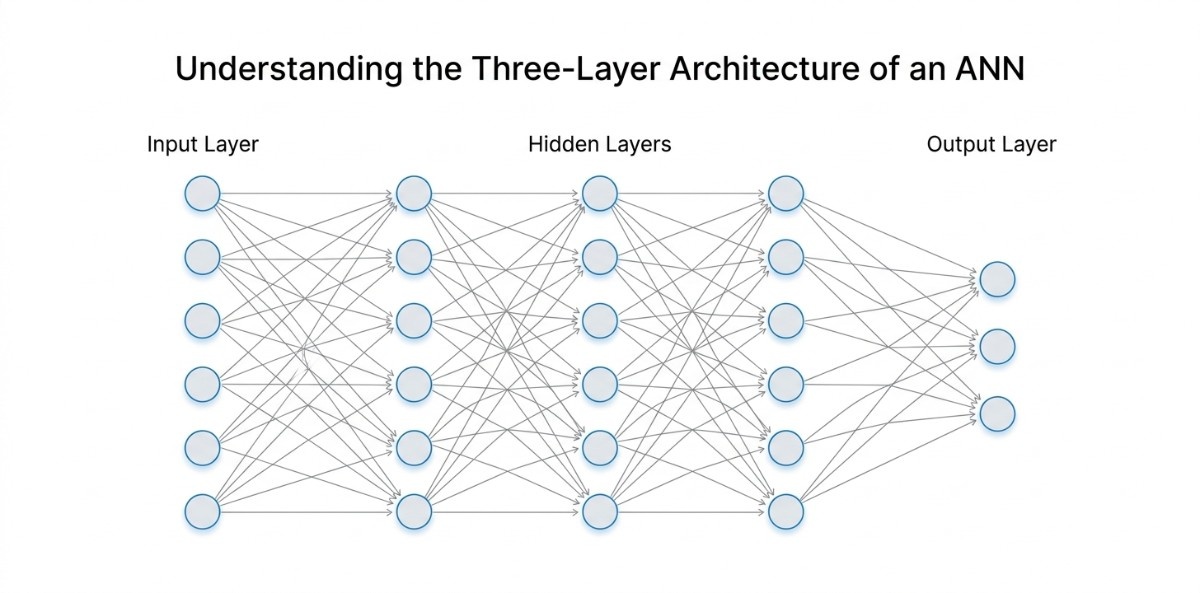
Every artificial neural network, whether it is a simple classifier or a large-scale model, follows a common structural pattern. At its core, an ANN is organized into three types of layers: the input layer, one or more hidden layers, and the output layer. This structure defines how data enters the network, how it is processed, and how the final result is produced.
Input Layer
The input layer is the first point of contact between the data and the neural network. It is responsible for receiving raw input values and passing them into the network without performing any transformation.
Each neuron in this layer represents one feature of the input data. For example, if the model is working with an image of size 28 by 28 pixels, the input layer will have 784 neurons, where each neuron corresponds to a single pixel value. In structured datasets, each neuron represents a feature such as age, income, or transaction value.
No activation function is applied at this stage because the input layer does not process the data. Its role is to ensure that all input features are correctly mapped and forwarded to the next layer.
The size of the input layer is fixed and depends entirely on the number of features in the dataset, making it directly tied to how the data is structured.
Hidden Layers
Hidden layers sit between the input and output layers and are responsible for the core learning process. These layers take the input data and transform it into more meaningful representations by applying weights, bias, and activation functions.
Each hidden layer builds on the output of the previous layer. Early layers typically capture simple patterns, while deeper layers identify more complex structures. For example, in an image recognition system, the first hidden layer may identify basic visual signals such as edges, light and dark regions, or simple textures.
The next layer combines these signals to detect shapes like curves, corners, or outlines. As the data moves deeper, the network begins to recognize more complete patterns, such as parts of objects like eyes, wheels, or letters. This gradual buildup allows the network to move from raw pixel values to meaningful understanding.
The number of hidden layers and neurons determines how much complexity the network can handle. A network with only one hidden layer is often referred to as a shallow network, while a network with many hidden layers is known as a deep neural network.
These layers are called "hidden" because their outputs are not directly visible. They operate internally, learning patterns from data that are not explicitly defined but discovered during training.
Output Layer
The output layer is the final stage of the network, where the processed information is converted into a result. The structure of this layer depends on the type of problem the network is solving.
For binary classification tasks, the output layer typically has a single neuron that represents one of two possible outcomes. For multi-class classification, the output layer contains multiple neurons, each corresponding to a specific category. For regression tasks, the output is usually a single neuron that produces a continuous numerical value.
For example, in a handwritten digit recognition system, the output layer may have ten neurons, each representing a digit from zero to nine. The neuron with the highest value indicates the predicted digit. In a price prediction model, the output layer would produce a single numerical value representing the estimated price.
This layer brings together all the processing done by the hidden layers and presents a clear and usable prediction.
By organizing the network in this way, neural networks can handle a wide range of problems, from simple classification tasks to more complex prediction and analysis. This structure is what enables them to learn from data and improve their performance over time.
Step by Step Working of Artificial Neural Networks
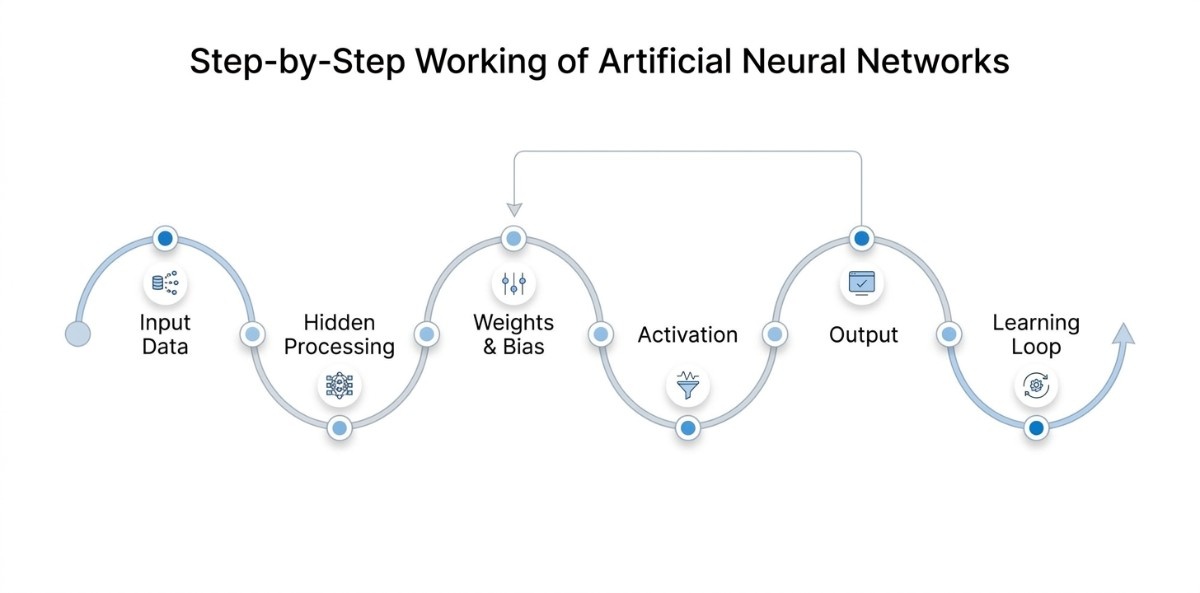
Artificial Neural Networks work by taking input data, processing it through multiple layers, and gradually turning it into a meaningful output. Instead of relying on fixed instructions, the network learns how to make better decisions by adjusting itself based on data.
Receiving and Structuring Input Data
Every neural network starts with the input layer, which is responsible for receiving the data. This data is always in numerical form, even if it originally comes from text, images, or audio. For example, an image is represented as pixel values, while text is converted into numerical vectors.
Each input node corresponds to a specific feature of the data. If the model is trained to detect spam emails, the inputs could include features such as the number of links, the presence of certain keywords, or sender details.
This layer does not perform any calculations. Its purpose is to pass clean and structured data into the network so that the next layers can begin processing it.
An important point at this stage is that the quality and relevance of input features directly affect the model’s performance. If the input data is incomplete or poorly prepared, the network may struggle to learn meaningful patterns, which can lead to inaccurate results.
Processing Data Through Hidden Layers
Once the data enters the network, it moves into the hidden layers. These layers are where most of the work happens. Each neuron receives input values, combines them, and passes the result forward.
The first hidden layer may pick up simple signals or basic relationships. As the data moves deeper, the network starts identifying more meaningful patterns.
In an image recognition task, early layers may detect edges or colors, while later layers recognize shapes and objects. This layered interpretation helps the model move from raw data to a useful understanding.
Another key aspect is that the number of hidden layers and neurons influences how well the model can learn. Too few layers may limit the model’s ability to capture complex patterns, while too many can make training slower and harder to manage.
Assigning Importance Using Weights and Bias
Inside the hidden layers, every input is multiplied by a weight. These weights decide how much influence a particular input should have on the final result. If a feature is important, its weight will be higher. If it is less relevant, the weight will be lower.
Bias is added to the calculation to give the model more flexibility. It allows the network to adjust its output even when input values are small or zero. Together, weights and bias control how information flows through the network and ensure that important signals are given more attention. These values are not fixed; they are updated continuously as the model learns.
A useful way to understand this is that weights and bias act as the memory of the network. They store what the model has learned from data and are refined over time to improve decision making.
Applying Activation to Refine the Output Signal
After applying weights and bias, the result is passed through an activation function. This function determines whether a neuron should send its output to the next layer.
This step is important because it helps the network handle complex patterns. Without activation functions, the model would only learn simple relationships and would not perform well on real world data.
By deciding which signals are strong enough to move forward, activation functions help filter out less useful information and keep the network focused on what matters.
Different activation functions are used depending on the problem, and choosing the right one can impact how effectively the model learns. This makes activation functions an important part of designing a neural network.
Generating the Final Output or Prediction
After passing through all hidden layers, the data reaches the output layer. This is where the network produces its final prediction. The form of the output depends on the task the model is solving.
For classification problems, the output could be a category such as spam or not spam. For prediction tasks, it could be a numerical value such as a price or score.
This layer brings together all the transformations from earlier stages and presents a clear result that can be used for decision making.
The structure of the output layer is designed based on the problem. For example, a binary classification task will have a different output setup compared to a multi-class classification problem.
Improving Accuracy Through Continuous Learning
Once the network produces an output, it does not stop there. The model compares its prediction with the actual result to see how accurate it is. The difference between the predicted value and the actual value is measured as error.
This error is then used to update the weights and bias across the network through a process called backpropagation. By adjusting these values, the model learns what went wrong and how to improve.
This process is repeated many times using different data samples. Over time, the network becomes better at making accurate predictions because it continuously learns from its mistakes.
The improvement does not happen in a single step. It requires multiple training cycles, often called epochs, where the model gradually refines its parameters and reduces errors with each iteration.
How This Process Works in Spam Detection
To understand this flow in a practical way, consider a spam detection system. The input layer receives details from an email, such as keywords, the number of links, and sender information. These inputs are passed into hidden layers, where the network looks for patterns commonly associated with spam.
Weights assign higher importance to strong indicators like suspicious phrases, while bias helps adjust the decision when needed. The activation function determines which signals are significant enough to influence the outcome. The output layer then classifies the email as spam or not.
If the prediction is incorrect, the model updates its internal parameters and becomes better at identifying spam in future emails.
This step by step process explains how neural networks take raw data, process it through multiple stages, and improve with experience. By continuously refining their internal parameters, neural networks are able to handle complex tasks and deliver accurate results across a wide range of real world applications.
Core Components of an Artificial Neural Network Explained
Artificial Neural Networks are built using a few fundamental components that work together to process data and generate predictions. Understanding these components helps clarify how the network makes decisions and improves over time. Each part has a specific role in controlling how information flows through the network.
Neurons (Nodes)
Neurons, also known as nodes, are the smallest units of a neural network. Each neuron receives input values, processes them, and passes the result to the next layer.
A neuron does not simply forward data. It combines multiple inputs, applies calculations, and produces an output based on that computation. In this way, neurons act as decision points within the network.
For example, in a model that analyzes customer data, a neuron may receive inputs such as age, purchase history, and activity level, and combine them to detect a pattern. When many neurons work together across layers, they enable the network to learn complex relationships in the data.
Weights
Weights determine how much influence each input has on the output of a neuron. Every connection between neurons has an associated weight, which adjusts the strength of the signal being passed.
If a particular input is more relevant to the task, it is given a higher weight. Less important inputs receive lower weights. These values are not fixed and are updated during training as the model learns from data.
For example, in a recommendation system, a user’s past purchases may carry more weight than general browsing activity. By adjusting weights, the network learns which features are most useful for making accurate predictions.
Bias
Bias is an additional value added to the weighted sum of inputs before passing it to the next stage. It helps the model shift the output and improves its ability to fit the data.
Without bias, the network would be limited in how it represents patterns, especially when input values are low or zero. Bias allows the model to make adjustments independently of the input values.
In practical terms, bias helps the network handle situations where a decision should not depend entirely on the input. It gives the model more flexibility to capture real world variations in data.
Activation Functions
Activation functions determine whether a neuron should pass its output forward. After weights and bias are applied, the result is processed through an activation function, which decides the final output of that neuron. It allows the network to learn complex patterns rather than simple linear relationships.
Different activation functions are used depending on the type of problem.
- ReLU (Rectified Linear Unit): Commonly used in hidden layers. It allows only positive values to pass through and helps the network learn efficiently.
- Sigmoid: Produces outputs between 0 and 1, making it useful for binary classification problems.
- Softmax: Converts outputs into probabilities across multiple classes, making it suitable for multi class classification tasks.
By controlling how signals move forward, activation functions play a key role in shaping how the network learns and makes decisions.
Together, these components form the foundation of any neural network. Neurons process information, weights and bias guide how that information is interpreted, and activation functions determine how it moves through the network. This combination allows neural networks to learn from data and produce meaningful results.
Types of Artificial Neural Networks You Should Know
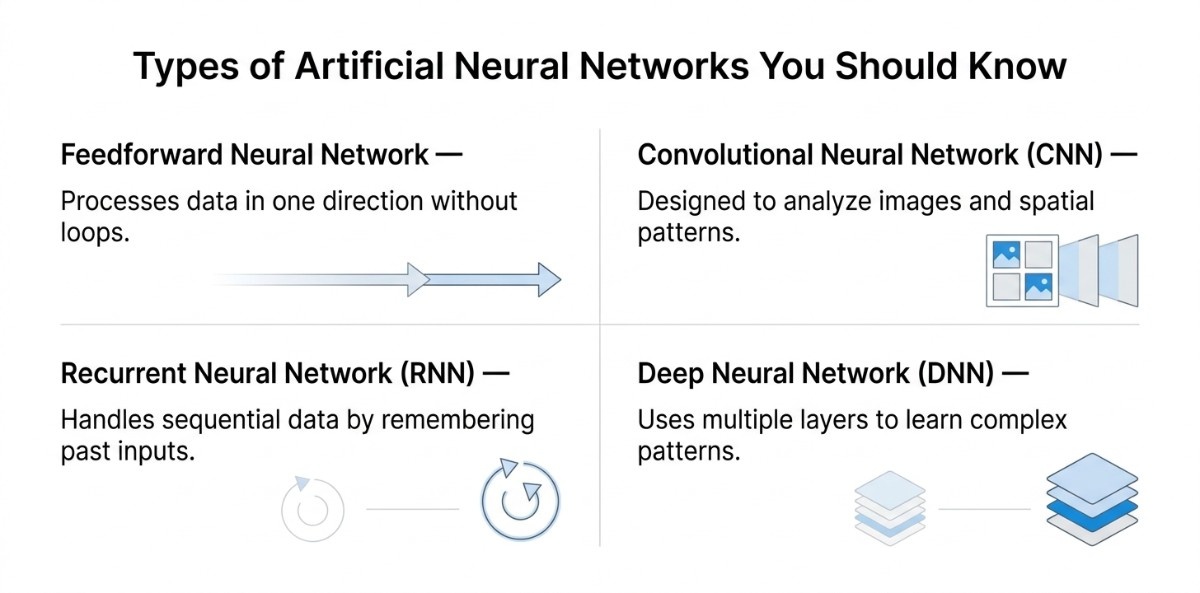
Artificial Neural Networks are designed in different forms based on how they process data and the kind of problems they are built to solve. While the basic structure remains the same, each type is optimized for a specific kind of input or pattern.
Feedforward Neural Network
A feedforward neural network is the most basic form, where data moves in one direction from the input layer to the output layer without any loops or feedback connections. Each layer processes the data once and passes it forward.
This type of network is suitable for problems where the relationship between input and output is direct and does not depend on sequence or context. It is commonly applied in tasks such as simple classification, risk scoring, or predicting outcomes based on structured data, where patterns are relatively straightforward.
Convolutional Neural Network (CNN)
Convolutional Neural Networks are designed to work with grid like data, especially images. Instead of processing every pixel independently, they focus on local patterns and gradually combine them to understand the full image.
These networks are effective in scenarios where spatial relationships matter. They can identify features such as edges, shapes, and objects within an image. This makes them well suited for tasks like image classification, object detection, and medical imaging, where understanding visual structure is essential.
Recurrent Neural Network (RNN)
Recurrent Neural Networks are designed to handle sequential data by retaining information from previous steps. Unlike feedforward networks, they consider the order of inputs, which allows them to understand patterns over time.
This makes them useful in situations where context is important, such as processing sentences, analyzing time based data, or predicting future values based on past trends. They are commonly used in language modeling, speech recognition, and time series forecasting, where the sequence of data directly influences the outcome.
Deep Neural Networks (DNN)
Deep Neural Networks refer to neural networks that contain multiple hidden layers. The added depth allows the model to learn more complex patterns by building on simpler ones at each layer.
These networks are capable of handling large and complex datasets where patterns are not easily visible. They are widely applied in advanced systems such as recommendation engines, natural language understanding, and large scale AI models, where deeper representations of data are required to achieve accurate results.
Each of these neural network types is designed with a specific purpose in mind. Feedforward networks handle simpler relationships, CNNs focus on visual patterns, RNNs capture sequential dependencies, and deep neural networks extend learning to more complex levels.
How Neural Networks Learn and Improve Over Time
Neural networks do not give accurate results from the start. They learn by going through a training process where they repeatedly make predictions, measure how far those predictions are from the actual results, and adjust themselves to improve. This learning process is what allows the model to move from initial guesses to reliable outcomes.
Training the Model Using Data and Repeated Learning Cycles
Training is the process by which the neural network is exposed to a dataset and learns patterns from it. The model takes input data, processes it through its layers, and produces an output. This output is then compared with the actual result to understand how well the model is performing.
This process is repeated across many examples. Over time, the network starts identifying patterns that help it make better predictions. The quality and size of the training data play a key role in how well the model learns.
Measuring Prediction Error Using a Loss Function
Once the model produces an output, it needs a way to measure how accurate that output is. This is done using a loss function, which calculates the difference between the predicted result and the actual result.
A smaller loss value means the prediction is closer to the correct answer, while a larger value indicates a bigger error. This measurement gives the model a clear signal of how much it needs to improve.
The choice of loss function depends on the type of problem, but the goal remains the same, to quantify how far the model is from the correct outcome.
Adjusting Weights Using Backpropagation
After calculating the error, the network needs to adjust itself to improve future predictions. This is done through backpropagation.
In this step, the error is passed backward through the network, and each layer updates its weights and bias based on how much it contributed to the mistake. Layers that had a larger impact on the error are adjusted more, while others are adjusted less.
This step allows the network to learn which parts of the model need correction and ensures that improvements are made in the right direction.
Optimizing the Model Using Gradient Descent
Gradient descent is the method used to update the weights in a controlled way. Instead of making random changes, the model adjusts its parameters step by step in the direction that reduces the error.
With each update, the model moves closer to a set of values that produces better predictions. This process continues over multiple iterations until the error is reduced to an acceptable level.
The size of each update is carefully controlled to ensure that the model improves steadily without making unstable changes.
During training, the network repeatedly performs the same cycle. It makes a prediction, measures the error, updates its internal parameters, and tries again. Each cycle helps the model refine its understanding of the data.
Over time, this process leads to a model that can recognize patterns and make accurate predictions on new data.
Building a Neural Network in Python with a Practical Example
Reading concepts helps, but building a small working model makes the process much clearer. Neural networks can be implemented in various languages and tools, but Python is widely used because of its strong ecosystem of libraries like TensorFlow and Keras. In this section, we will create a simple neural network in Python that learns from data, evaluates its performance, and makes predictions.
This kind of hands-on approach is also used when building real applications, such as a chatbot, where the same core principles are applied in a more practical setting. The aim here is not just to run code, but to understand what is happening at each stage and how all parts of a neural network come together in practice.
What We Are Building and How It Works
We are building a basic classification model that takes multiple input features and predicts an outcome. The model learns by looking at examples, identifying patterns, and adjusting itself to improve accuracy.
In simple terms:
- The model receives input data
- It processes the data through layers
- It produces a prediction
- It compares the prediction with the actual result
- It improves over multiple training cycles
This is the same learning process used in real world applications, just applied on a smaller scale for clarity.
Implementation Path Using Keras
Keras is a practical starting point because it handles most of the internal complexity and lets you focus on the flow of building and training the model.
Step 1: Install Required Libraries
pip install tensorflow scikit-learnStep 2: Load and Prepare Data
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)At this stage, the dataset is divided into two parts. One part is used to train the model, and the other is used to test how well the model performs on new data. Scaling ensures that all input features are on a similar range, which helps the model learn more effectively.
Step 3: Define the Neural Network
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=(30,)),
layers.Dense(32, activation='relu'),
layers.Dense(1, activation='sigmoid')
])Here, we define the structure of the network:
- The first layer receives 30 input features
- Hidden layers learn patterns from the data
- The final layer produces a probability as output
Step 4: Compile the Model
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy']
)This step defines how the model learns. The optimizer controls how weights are updated, and the loss function measures how far predictions are from actual values.
Step 5: Train the Model
model.fit(X_train, y_train, epochs=20, batch_size=32)During training, the model processes the data multiple times. In each cycle, it improves its internal parameters to reduce errors and make better predictions.
Step 6: Evaluate Performance
loss, accuracy = model.evaluate(X_test, y_test)
print("Accuracy:", accuracy)This step checks how well the model performs on data it has not seen before. This gives a realistic measure of its performance.
Step 7: Make a Prediction
sample = X_test[0:1]
prediction = model.predict(sample)
print("Prediction:", prediction)The model outputs a probability value. This value is then used to decide the final classification.
What the Output Looks Like
When you run this model, you will see training logs for each cycle. These logs show how accuracy improves over time.
A typical output may look like:
Epoch 20/20
Accuracy: 0.96
Loss: 0.10When making a prediction, the output might look like:
Prediction: [[0.87]]This means the model is 87 percent confident about one of the classes. Based on a threshold, this is converted into a final decision.
What This Implementation Actually Demonstrates
This example brings together all the core concepts of a neural network into a working flow. It starts with preparing raw data so the model can learn from it, then builds a structured network using layers, and shows how the model improves through training. It also makes it clear how performance is measured using unseen data and how final predictions are generated based on learned patterns.
More importantly, it turns theory into something practical. Concepts like layers, weights, and learning are no longer abstract. You can see how they work together as part of a system that takes input, processes it step by step, and produces a clear output.
Why This Matters
Although this is a simple model, the same process applies to more advanced neural networks used in real applications. Whether it is recommendation engines, fraud detection systems, or image recognition, the underlying workflow remains the same.
Starting with a basic implementation helps build a strong foundation. Once this flow is clear, it becomes much easier to understand and work with more complex models, because you already know how each part contributes to the final result.
How to Train a Neural Network and Get Reliable Results
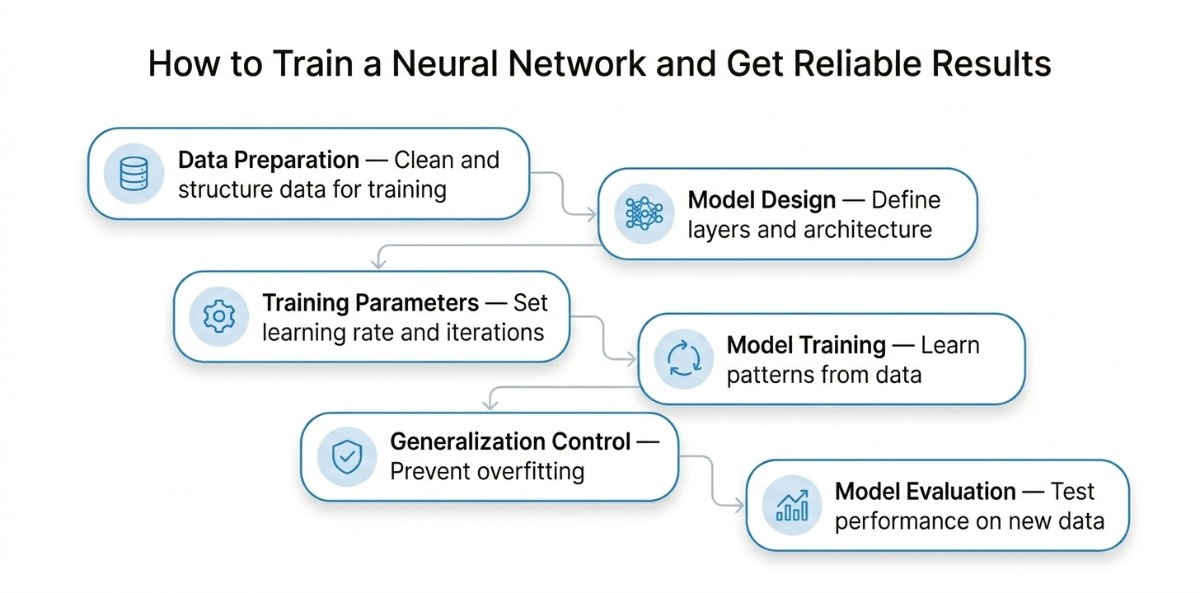
Now that we have seen how a neural network processes data internally, the next step is to understand how to train it so that it produces accurate and reliable results. Training is not about how data flows inside the network, but about how we prepare data, guide learning, and evaluate performance.
Stage 1: Preparing Data for Effective Learning
Training starts with data, and the quality of this data directly affects the model’s performance. Before training, the dataset must be cleaned, structured, and converted into a numerical format that the network can process, and ensure that labels are correctly defined using correct data annotation.
This includes handling missing values, encoding categorical features, and scaling inputs so that all features are on a similar range. Without proper scaling, some inputs may dominate others, leading to unstable learning.
The data is then split into training and testing sets. The model learns from the training data, while the test data is used later to check how well it performs on new inputs. This separation is important to ensure that the model is actually learning patterns and not just memorizing the dataset.
Stage 2: Designing the Model for the Problem
Once the data is ready, the next step is defining the structure of the network. This involves deciding how many layers to use and how many neurons each layer should have.
The goal is not to build the most complex model, but to choose a structure that matches the problem. A simple model is often enough for smaller datasets, while more complex problems may require deeper networks.
At this stage, activation functions are also selected to help the model learn patterns that are not straightforward. In most cases, standard configurations work well and do not require frequent changes.
Stage 3: Setting Training Parameters
Before training starts, certain parameters need to be defined. These include how many times the model will go through the data, how updates are applied, and how quickly it learns.
These settings control how the model improves over time. If they are not set properly, the model may learn too slowly, stop improving early, or fail to reach a stable solution.
Choosing balanced settings helps ensure that the model learns steadily and reaches good performance without unnecessary complexity.
Stage 4: Training the Model and Tracking Its Progress
During training, the model processes the training data, makes predictions, and compares them with actual results. Based on the difference, it adjusts its internal parameters to improve future predictions.
This process is repeated over multiple cycles. As training progresses, the error should reduce and the predictions should become more accurate.
Tracking performance during this stage is important. It helps in understanding whether the model is learning correctly or if adjustments are needed.
Stage 5: Preventing Overfitting and Improving Generalization
A common issue during training is overfitting, where the model performs well on training data but does not perform well on new data. This happens when the model learns specific details instead of general patterns.
To prevent this, the training process needs to be controlled. This can include limiting model complexity, stopping training at the right time, or applying techniques that help the model generalize better.
The goal is to ensure that the model performs consistently, not just on known data but also on new inputs.
Stage 6: Evaluating the Model on Unseen Data
After training is complete, the model is tested on data it has not seen before. This step shows how well the model performs in real scenarios.
Evaluation should go beyond just accuracy, especially when the dataset is not evenly distributed. Looking at different performance measures helps in understanding how reliable the model is.
This stage confirms whether the model is ready to be used or needs further improvement.
By following a structured process, you ensure that the model learns meaningful patterns, performs consistently, and produces reliable results. A well designed model will not perform well unless it is trained with the right data and approach. This approach applies across different problems and forms the foundation of working with neural networks in practice.
Key Differences between ANN, Machine Learning and Deep Learning
Artificial Neural Networks, Machine Learning, and Deep Learning are closely related, but they are not the same. Understanding how they differ helps choose the right approach to a problem and clears up a common source of confusion.
Machine Learning is the broader field that focuses on building systems that learn from data, where the way data is processed and prepared directly impacts how well models perform. Artificial Neural Networks are one type of model used within machine learning. Deep Learning is a subset of neural networks that uses multiple layers to learn more complex patterns.
Machine Learning is an overall approach that encompasses many techniques, such as decision trees, regression models, and neural networks. Artificial Neural Networks are one of these techniques, designed to handle pattern recognition and complex relationships in data.
Deep Learning takes neural networks further by increasing the number of layers, which allows the model to learn more detailed and abstract patterns. This is why deep learning is used in advanced applications like image recognition and natural language processing.
Understanding these differences helps in selecting the right method and avoids using overly complex solutions when a simpler approach would work just as well.
Common Challenges in Implementing Neural Networks
Neural networks are powerful, but working with them in real projects is not always straightforward. Beyond the concepts, there are practical challenges that affect how well a model performs and how easy it is to use in real situations. Being aware of these early helps avoid common mistakes and saves time during development.
Data Quality and Availability Issues
Neural networks learn entirely from data, so the quality of that data matters a lot. If the dataset has missing values, incorrect labels, or too much noise, the model will struggle to learn the right patterns.
In many cases, the bigger challenge is not building the model but preparing the data. Cleaning, organizing, and selecting the right features often takes more effort than the training itself. A simple model with good data can perform better than a complex model with poor data.
Overfitting and Poor Generalization
A common issue is when the model performs very well during training but fails on new data. This happens when the model starts memorizing the training data instead of learning general patterns.
This usually occurs when the model is too complex for the dataset or when there is not enough data. The result is a model that looks accurate during development but does not work well in real use. Managing this requires balancing the model design and monitoring how it performs beyond the training data.
Training Time and Computational Effort
Training a neural network can take time, especially as the size of the data and the model increases. Even a well designed model may require multiple training cycles before it reaches good accuracy.
This becomes more noticeable when working with larger datasets or when the model needs frequent updates. In such cases, training can slow down development and require careful planning to manage time and resources effectively.
Infrastructure and Cost Considerations
Neural networks often need more computational power than traditional models. For larger problems, using standard hardware may not be enough, and specialized resources like GPUs are required.
Along with hardware, there are costs related to storing data, running training processes, and deploying the model. These factors can add up, especially for large scale applications. It is important to balance performance with practical constraints to keep the solution manageable.
These challenges show that building a neural network is not just about writing a model. It involves working with data, managing resources, and ensuring the model performs well in real situations. Understanding these aspects early helps in making better decisions and building systems that are not only accurate but also reliable and practical to use, especially when developing AI solutions for real-world applications.
Real World Applications of Neural Networks Across Industries
Artificial Neural Networks are not limited to theory. They are used across industries to solve practical problems where patterns are complex and not easy to define with rules. Their ability to learn from data makes them useful in areas that involve prediction, recognition, and decision making.
Supporting Diagnosis and Medical Analysis
In healthcare, neural networks are used to assist in diagnosing diseases and analyzing medical data. They can process large amounts of patient information, including medical images, and identify patterns that may not be obvious.
For example, neural networks are used in detecting conditions from X-rays or scans, helping doctors make more accurate and faster decisions. They are also used in predicting disease risks based on patient history and clinical data.
The growing use of AI in healthcare reflects this shift. The global AI in healthcare market is expected to exceed 51.20 billion USD in 2026 to approx 613.81 billion USD by 2034, showing how rapidly these systems are being adopted in medical environments.
Detecting Fraud and Managing Risk
In the financial sector, neural networks help identify unusual patterns in transactions. These patterns can indicate fraud or suspicious activity.
Banks and financial platforms use these models to monitor transactions in real time and flag anything that does not match normal behavior. Neural networks are also used in credit scoring and risk assessment, where they analyze multiple factors to support better decision-making.
Personalizing Recommendations
E-commerce platforms use neural networks to understand user behavior and suggest relevant products. These systems analyze browsing history, past purchases, and user preferences to recommend items that are more likely to be of interest.
For example, platforms like Netflix suggest content based on what users have watched before, while online stores recommend products based on similar customer activity. This improves user experience and increases engagement, especially with the growing use of gen AI in e-commerce, which further enhances personalization and customer interaction.
It is also estimated that over 35 percent of consumer purchases on major platforms are influenced by recommendation engines, showing how important these systems have become.
Powering Chatbots and Assistants
Neural networks are at the core of modern AI tools that interact with users. Systems like ChatGPT use advanced neural network models to understand language and generate responses.
Voice assistants and chatbots also rely on neural networks to process user input, understand intent, and provide relevant answers. This is especially relevant when building conversational systems, and a chatbot directly depends on how these models handle language and context.
These tools are widely used in customer support, content generation, and automation.
Recognizing Images and Faces
Neural networks are widely used in computer vision, where systems need to interpret visual data. They can identify objects, recognize faces, and understand scenes in images or videos.
For example, face recognition systems used in mobile devices or security applications rely on neural networks to match patterns in images. Navigation systems like Google Maps also use these models to analyze routes, traffic patterns, and visual data for better guidance.
These examples show how neural networks are applied in everyday systems that people interact with regularly. From healthcare to digital platforms, they help improve accuracy, automate decisions, and enhance user experience.
Key Takeaway
ANN are at the core of how modern AI systems work, from simple predictions to advanced applications like language models and computer vision. What makes them valuable is not just their structure, but their ability to learn from data and improve over time. As you have seen, understanding how they work, where they are used, and how they are trained gives you a clear foundation to approach real-world AI problems. The key takeaway is simple; neural networks are not just a concept; they are a practical tool that continues to shape how technology solves complex problems across industries.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us