



Top 20 Python Libraries for Data Science



Migrating Legacy Data Pipelines
Reduce bottlenecks with modern processing frameworks.
Python has over 200,000 packages on PyPI, but most data scientists rely on only a small fraction of them in real-world workflows. The challenge today is not finding Python libraries; it is understanding which libraries are actually useful, which ones scale in production, and which tools are worth learning in 2026.
From data analysis and visualization to machine learning, distributed computing, and generative AI, the modern Python ecosystem has evolved far beyond traditional analytics.
In 2026, the Python data science ecosystem is shifting toward high-performance and AI-focused workflows. Traditional tools are now being complemented by faster, more scalable libraries such as Polars, Dask, Ray, and Transformers, which can handle real-time analytics, distributed computing, and large AI models more efficiently.
As data workloads continue to grow, choosing the right Python library is no longer just about features; it depends on speed, scalability, ecosystem compatibility, and the type of data science problem you are solving.
Our Top Python Libraries for Data Science
If you are starting with Python data science or deciding which libraries are worth learning first, these are the most practical and widely used options across analytics, machine learning, scalable processing, and AI development workflows. Each library solves a different part of the data science pipeline, which is why most production systems combine several of them.
No single Python library is designed for every data science task. Some libraries are better for data analysis and visualization, while others are built for machine learning, scalable processing, or AI application development. Choosing the right tool depends on factors such as dataset size, workflow complexity, performance requirements, and how the project is expected to scale.
For example, Pandas and Scikit-learn work well for traditional analytics and ML workflows, while larger data pipelines often require tools like Polars or PySpark. Similarly, modern AI applications increasingly rely on frameworks such as PyTorch, Transformers, and LangChain for deep learning and LLM-powered systems.
Best Python Libraries for Data Science
Python’s data science ecosystem now covers everything from data analysis and visualization to scalable machine learning, deep learning, distributed processing, and LLM-powered applications. The libraries below are grouped by category to help you understand where each tool fits in real-world workflows, when to use it, and how modern data science stacks are evolving in 2026.
Core Data Manipulation Libraries
Data manipulation is one of the most important parts of any data science workflow. Before teams can train models, build dashboards, or generate insights, they need to clean raw data, process missing values, restructure datasets, and prepare information for analysis. Python has remained the preferred language for these tasks largely because of its mature ecosystem of data processing libraries.
Libraries such as NumPy, Pandas, SciPy, and Polars solve different problems within this workflow. Some focus on numerical computation, some simplify dataframe operations, while others are designed for scientific calculations or high-performance processing. Understanding where each library fits helps developers choose tools based on the size of the dataset, the complexity of operations, and performance requirements.
NumPy
NumPy is the foundation of numerical computing in Python. Most machine learning and data science libraries depend on it internally because it provides efficient array operations and mathematical computation capabilities.
It is commonly used for handling multidimensional arrays, matrix calculations, statistical functions, and vectorized operations that would otherwise be slow in standard Python loops.
In practical workflows, NumPy is often used when working with structured numerical data, linear algebra, mathematical operations on large arrays, matrix manipulation, and random number generation.
Since operations are optimized in low-level compiled code, NumPy performs significantly faster than native Python for numerical tasks. However, it is not designed for working with labeled tabular data or spreadsheet-like datasets. For those use cases, developers typically move to Pandas or Polars.
import numpy as np
# Create an array
data = np.array([10, 20, 30, 40, 50])
# Vectorized operation — no loops needed
print(data * 2) # [20 40 60 80 100]
print(data.mean()) # 30.0
print(data.std()) # 14.14...
# 2D array (matrix)
matrix = np.zeros((3, 3))
identity = np.eye(3)
# Dot product
result = np.dot(matrix, identity)Pandas
Pandas is the go-to library for working with structured, tabular data. Think spreadsheets, SQL tables, and CSVs, but with powerful Python code instead of formulas. It allows developers to clean datasets, filter records, merge tables, perform aggregations, and work with formats such as CSV and Excel using straightforward syntax.
Most beginner and intermediate data science workflows are built around Pandas because of its readability and extensive ecosystem support.
The library works well for exploratory analysis, reporting workflows, business analytics, and small to medium-sized datasets. However, as datasets become larger, memory consumption and execution speed can become limitations.
Operations on large files may slow down significantly, especially in workflows involving repeated transformations or multi-core processing. This is one reason newer alternatives such as Polars are gaining attention in modern data engineering pipelines.
import pandas as pd
df = pd.read_csv("sales.csv")
monthly_sales = (
df.groupby("month")["revenue"]
.sum()
.reset_index()
)
print(monthly_sales)Polars
Polars is a DataFrame library written in Rust that runs operations in parallel across all CPU cores by default. It was designed for the modern reality in which datasets routinely exceed what Pandas can comfortably handle.
This is the most talked-about new addition to the data science stack in 2025–2026. Benchmarks consistently show that Polars runs 5x to 15x faster than Pandas on large datasets and uses significantly less memory.
In a 2026 benchmark on 5 million rows, a groupby aggregation took ~0.45 seconds in Pandas and ~0.03 seconds in Polars, a 15x speedup. On joins at scale, the gap is even larger. It is particularly useful for ETL pipelines, analytics systems, and high-volume data processing tasks where execution speed matters.
For datasets larger than roughly 500MB, Polars is often a better option than Pandas. That said, Pandas still has broader community adoption and stronger compatibility with older Python tooling, so many teams continue using both depending on the workflow.
import polars as pl
# Load data — same idea, different API
df = pl.read_csv("large_data.csv")
# Filter and aggregate — using expressions
result = (
df
.filter(pl.col("revenue") > 10000)
.group_by("region")
.agg([
pl.col("revenue").sum().alias("total_revenue"),
pl.col("revenue").mean().alias("avg_revenue"),
])
.sort("total_revenue", descending=True)
)
print(result)Pandas vs. Polars - side by side:
# Same operation in both libraries
# Pandas
import pandas as pd
result_pd = (
df_pd.groupby("region")["revenue"]
.agg(total=("sum"), avg=("mean"))
.reset_index()
)
# Polars
import polars as pl
result_pl = (
df_pl.group_by("region")
.agg([
pl.col("revenue").sum().alias("total"),
pl.col("revenue").mean().alias("avg"),
])
)Polars is a better choice for large datasets, automated ETL pipelines, and workflows where joins, aggregations, or filtering start becoming slow in Pandas. It is especially useful when processing datasets larger than 500MB or building new high-performance data pipelines from scratch.
Pandas remains more practical for smaller datasets, exploratory analysis, and workflows that depend on libraries like Scikit-learn or Statsmodels.
In many projects, teams use both libraries together, processing large datasets with Polars and converting the final output to Pandas only where compatibility is needed, using polars_df.to_pandas().
SciPy
SciPy extends NumPy by providing advanced scientific and mathematical computing functions. It includes tools for optimization, statistics, interpolation, signal processing, and other computational tasks commonly used in research, engineering, and data analysis.
While NumPy focuses mainly on array operations and numerical computation, SciPy adds higher-level mathematical functionality that is useful in more specialized workflows.
It is commonly used in statistical modeling, simulation systems, scientific research, and engineering applications where mathematical precision and advanced algorithms are required. Unlike Pandas or Polars, SciPy is not designed for dataframe manipulation or general-purpose data cleaning tasks.
from scipy import stats
data = [12, 15, 14, 10, 18]
mean = stats.tmean(data)
print(mean)Data Visualization Libraries
Data visualization plays a critical role in data science because raw numbers are often difficult to interpret without visual context. Charts and graphs help teams identify trends, compare distributions, detect anomalies, and communicate findings more clearly. Python offers several visualization libraries, but Matplotlib, Seaborn, and Plotly remain the most widely used because each serves a different type of workflow.
Matplotlib
Matplotlib is the foundational visualization library in Python and is widely used for creating static charts with precise control over styling and layout. It supports everything from simple line graphs to highly customized publication-quality visualizations used in research, reporting, and technical analysis.
One of Matplotlib’s biggest strengths is flexibility. Developers can customize almost every part of a chart, including axes, labels, colors, annotations, and layouts. However, this level of control also means the syntax can become verbose for complex visualizations.
import matplotlib.pyplot as plt
import numpy as np
# Line chart
months = range(1, 13)
revenue = [42, 48, 55, 61, 58, 70, 75, 68, 72, 80, 85, 92]
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(months, revenue, marker="o", linewidth=2, color="#2563EB")
ax.set_title("Monthly Revenue 2025", fontsize=14, fontweight="bold")
ax.set_xlabel("Month")
ax.set_ylabel("Revenue ($k)")
ax.grid(axis="y", alpha=0.3)
plt.tight_layout()
plt.savefig("revenue_chart.png", dpi=150)
plt.show()Seaborn
Seaborn is built on top of Matplotlib and simplifies the process of creating statistical visualizations. It provides cleaner default styles and allows developers to create complex charts with significantly less code.
It is commonly used for exploratory data analysis, correlation analysis, distribution plots, and category-based comparisons. Because Seaborn integrates closely with Pandas DataFrames, it is often preferred in notebook-based analytics workflows where readability and speed of development matter more than deep chart customization.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Correlation heatmap — one of the most useful EDA tools
df = pd.read_csv("housing_data.csv")
numeric_cols = df.select_dtypes(include="number")
plt.figure(figsize=(10, 8))
sns.heatmap(
numeric_cols.corr(),
annot=True,
fmt=".2f",
cmap="coolwarm",
center=0
)
plt.title("Feature Correlation Matrix")
plt.tight_layout()
plt.show()
# Distribution plot
sns.histplot(df["price"], kde=True, bins=30)
plt.title("Price Distribution")
plt.show()Plotly
Plotly is designed for interactive visualizations and modern analytics dashboards. Unlike Matplotlib or Seaborn, Plotly charts support zooming, hovering, filtering, and dynamic interactions directly in the browser, making it especially useful for web applications and business intelligence dashboards.
In 2026, Plotly has become increasingly important in data-driven products because many analytics workflows now require interactive reporting rather than static charts. It is widely used with frameworks like Dash for building real-time dashboards and monitoring systems.
import plotly.express as px
df = px.data.gapminder()
fig = px.scatter(
df,
x="gdpPercap",
y="lifeExp",
color="continent"
)
fig.show()Machine Learning Libraries
Machine learning libraries simplify the process of training models, evaluating performance, and building predictive systems on top of structured data. While Python offers hundreds of ML packages, Scikit-learn, XGBoost, and LightGBM remain the most widely used for practical machine learning workflows because they balance usability, performance, and production reliability.
Scikit-learn
Scikit-learn is the standard machine learning library for Python and is commonly used for classification, regression, clustering, preprocessing, and model evaluation. Its biggest advantage is simplicity; developers can build complete machine learning workflows with consistent and easy-to-understand syntax.
The library works especially well for small to medium-sized datasets, experimentation, and traditional machine learning tasks such as customer prediction, fraud detection, recommendation systems, and forecasting. It also integrates closely with Pandas and NumPy, making it a common starting point for most ML projects.
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(
data.data,
data.target,
test_size=0.2,
random_state=42
)
model = LogisticRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(accuracy_score(y_test, predictions))Scikit-learn is ideal for learning machine learning concepts and building structured ML pipelines quickly. However, for large-scale tabular datasets or highly optimized boosting models, libraries like XGBoost and LightGBM often deliver better performance.
XGBoost
XGBoost is one of the most widely used gradient boosting libraries for structured and tabular data. It became extremely popular through Kaggle competitions because of its ability to produce highly accurate models with relatively minimal feature engineering.
The library works especially well for classification and regression problems involving structured business data such as financial records, customer analytics, fraud detection, recommendation systems, and churn prediction.
It also handles missing values efficiently and includes built-in regularization features that help improve model stability and reduce overfitting.
XGBoost is often preferred when model accuracy is the top priority, especially in tabular machine learning tasks where deep learning may not provide significant advantages.
from xgboost import XGBClassifier
model = XGBClassifier()
model.fit(X_train, y_train)
predictions = model.predict(X_test)LightGBM
LightGBM is another gradient boosting framework designed for faster training and lower memory usage. Compared to XGBoost, it is generally more efficient on very large datasets and can train models significantly faster in high-volume workflows.
The library is commonly used in production systems where training speed, scalability, and resource efficiency matter. It performs especially well with large feature sets and high-dimensional data.
While LightGBM is faster in many scenarios, XGBoost is often considered more stable and easier to tune for smaller datasets. Many teams choose between the two based on dataset size, training speed requirements, and infrastructure constraints.
import lightgbm as lgb
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = lgb.LGBMClassifier(
n_estimators=500,
learning_rate=0.05,
num_leaves=31,
random_state=42
)
model.fit(
X_train, y_train,
eval_set=[(X_test, y_test)],
callbacks=[lgb.early_stopping(50), lgb.log_evaluation(100)]
)
accuracy = model.score(X_test, y_test)
print(f"Accuracy: {accuracy:.3f}")LightGBM vs XGBoost
XGBoost and LightGBM are often compared because both are widely used for high-performance machine learning on structured data, but they are optimized for different workloads.
In real-world projects, the choice between them can directly affect model training time, infrastructure cost, and scalability.
For example, a model that takes hours to train in XGBoost may train significantly faster in LightGBM on large datasets, while XGBoost can sometimes produce more stable results on smaller or noisier data.
Understanding these trade-offs becomes important when building production ML systems where both accuracy and efficiency matter.
Try both. In practice, LightGBM trains faster and often matches or beats XGBoost on accuracy with less tuning. For most production work on large datasets in 2026, LightGBM is the default choice. For Kaggle competitions, many winners use XGBoost or an ensemble of both.
Deep Learning and AI Libraries
Deep learning libraries are used when traditional machine learning models are no longer enough for the problem being solved. Applications such as image recognition, speech processing, recommendation systems, chatbots, document understanding, and gen AI require neural networks, and the Python AI library has matured to support all of these use cases with well-maintained, production-tested tools.
Unlike traditional ML libraries that mainly work with structured tables, these frameworks are designed for training and deploying neural networks at scale. They also provide GPU acceleration, pre-trained models, distributed training support, and integration with modern AI workflows.
TensorFlow
TensorFlow is developed for training and deploying neural networks in production environments. It is widely used in enterprise AI systems because it supports distributed training, GPU acceleration, model optimization, and deployment across cloud, mobile, and edge devices.
The framework is commonly used for large-scale applications such as recommendation engines, computer vision systems, forecasting models, and speech recognition pipelines. It also includes tools like TensorFlow Serving and TensorFlow Lite, which help teams deploy AI models into production systems more efficiently.
TensorFlow also performs well in environments where teams need optimized GPU acceleration and distributed model training across multiple systems, the kind of ML infrastructure that larger engineering organizations typically invest in. This makes it practical for organizations handling large datasets or production AI workloads that require scalability and infrastructure support.
While it has a steeper learning curve compared to some newer frameworks, it remains a strong choice for enterprise AI systems where deployment, scalability, and long-term ecosystem support are important.
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(1)
])
model.compile(
optimizer="adam",
loss="mse"
)Keras
Keras is a high-level API built on top of TensorFlow that simplifies the process of building neural networks. Instead of writing low-level training logic manually, developers can define deep learning models using concise and readable code.
It is widely used for rapid prototyping, experimentation, and educational workflows because it reduces development complexity significantly. Tasks such as image classification, regression modeling, and sequence prediction can be implemented quickly without managing the underlying infrastructure directly.
It allows developers to move from experimentation to TensorFlow production pipelines without changing frameworks. Most TensorFlow workflows today use Keras as the primary interface because it improves readability while still providing access to TensorFlow’s backend capabilities.
For beginners entering deep learning, Keras is often the easiest starting point because it focuses more on model design and experimentation rather than framework complexity.
from keras.models import Sequential
from keras.layers import Dense
model = Sequential([
Dense(64, activation="relu"),
Dense(1)
])PyTorch
PyTorch is Meta's deep learning framework. It uses dynamic computation graphs, which means you write and debug neural network code exactly like regular Python, no compilation step, no special syntax.
PyTorch has become the dominant framework in deep learning research and modern AI development. Approximately 85% of deep learning research papers now use PyTorch. More importantly, the entire Hugging Face ecosystem, which powers most of the LLM work happening in 2026, is built on PyTorch.
Researchers and engineering teams can modify architectures, test new approaches, and debug training pipelines more easily compared to more structured frameworks. This is one reason PyTorch has become the standard framework across research labs, AI startups, and generative AI companies.
import torch
import torch.nn as nn
model = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 1)
)Hugging Face Transformers
The Hugging Face transformers library is the central repository for pre-trained models, language models like BERT, GPT, Llama, and thousands of others. It gives you a simple, unified API to download and use state-of-the-art models for any text task.
Hugging Face has become the de facto home for pre-trained AI models. The Hugging Face Hub hosts over 1 million models across text, images, audio, and video, including the multimodal vision-language models that have become increasingly relevant for document understanding and image analysis workflows.
For any NLP task in 2026, your first question should be "Is there a pre-trained model for this?" - and the answer is almost always yes. The library supports tasks such as sentiment analysis, text generation, summarization, translation, document classification, question answering, and conversational AI.
Instead of training models from scratch, teams can fine-tune existing models for business-specific use cases, which significantly reduces development time and infrastructure cost.
from transformers import pipeline
# Sentiment analysis in 5 lines
classifier = pipeline("sentiment-analysis")
results = classifier([
"This product completely transformed our workflow.",
"Disappointing performance, would not recommend."
])
for result in results:
print(f"Label: {result['label']}, Score: {result['score']:.3f}")
# Label: POSITIVE, Score: 0.999
# Label: NEGATIVE, Score: 0.997
# Text summarization
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
summary = summarizer(long_article_text, max_length=130, min_length=30)
print(summary[0]["summary_text"])
# Named entity recognition
ner = pipeline("ner", grouped_entities=True)
entities = ner("Apple Inc. was founded by Steve Jobs in Cupertino, California.")
for entity in entities:
print(f"{entity['word']} → {entity['entity_group']}")Hugging Face is now widely used in AI-powered products such as support chatbots, document automation systems, semantic search engines, recommendation systems, and internal AI assistants.
Many companies building modern AI applications use these tools to accelerate development and integrate production-ready AI features into existing business systems. How those systems are actually structured, the design patterns and tradeoffs involved, is a separate question that GenAI application architecture addresses in detail.
NLP Libraries
Natural Language Processing (NLP) libraries are used for working with text data such as customer reviews, emails, support tickets, documents, chat conversations, and search queries.
These libraries help developers process language, extract meaning from text, identify entities, and build applications such as chatbots, text classifiers, recommendation systems, and document analysis tools.
While modern LLM frameworks now handle many advanced NLP tasks, libraries like NLTK and spaCy still play an important role in text preprocessing, linguistic analysis, and traditional NLP workflows.
NLTK
NLTK (Natural Language Toolkit) is one of the oldest and most widely used NLP libraries in Python. It is mainly used for learning NLP fundamentals and experimenting with traditional language processing techniques.
The library includes datasets, tokenizers, stemmers, parsers, and linguistic processing tools that help developers understand how NLP systems work internally. Because of its educational focus, NLTK is commonly used in academic projects, NLP tutorials, and beginner-level text analysis workflows.
It is useful for Learning NLP fundamentals (tokenization, stemming, lemmatization), working with NLTK's built-in text corpora for research, and projects where you need fine-grained control over basic text preprocessing.
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
# Download required data (first time only)
nltk.download("punkt")
nltk.download("stopwords")
text = "Python libraries for data science have evolved significantly in 2026. New tools like Polars are changing how data engineers work."
# Tokenize
sentences = sent_tokenize(text)
words = word_tokenize(text.lower())
# Remove stopwords
stop_words = set(stopwords.words("english"))
filtered = [w for w in words if w.isalpha() and w not in stop_words]
# Stemming
stemmer = PorterStemmer()
stemmed = [stemmer.stem(word) for word in filtered]
print("Filtered:", filtered[:8])
print("Stemmed:", stemmed[:8])spaCy
spaCy is a production-focused NLP library designed for fast and efficient text processing. It is widely used in real-world NLP applications because it provides optimized pipelines for named entity recognition (NER), dependency parsing, text classification, and information extraction.
Compared to NLTK, spaCy is significantly faster and better suited for production workloads involving large volumes of text data. It also includes pre-trained language models that simplify tasks such as entity extraction and syntactic analysis without requiring a complex setup.
spaCy is commonly used in document automation systems, resume parsing, customer support analytics, legal text analysis, and enterprise search applications where structured information needs to be extracted from large text datasets efficiently.
import spacy
# Load pre-trained English model
# First time: python -m spacy download en_core_web_sm
nlp = spacy.load("en_core_web_sm")
text = "Google DeepMind published a new research paper on AI reasoning last week in London."
doc = nlp(text)
# Named Entity Recognition
print("Entities found:")
for ent in doc.ents:
print(f" {ent.text:25} → {ent.label_}")
# Google DeepMind → ORG
# last week → DATE
# London → GPE
# Dependency parsing — understand sentence structure
for token in doc:
print(f"{token.text:15} {token.dep_:12} {token.head.text}")Big Data Processing Libraries
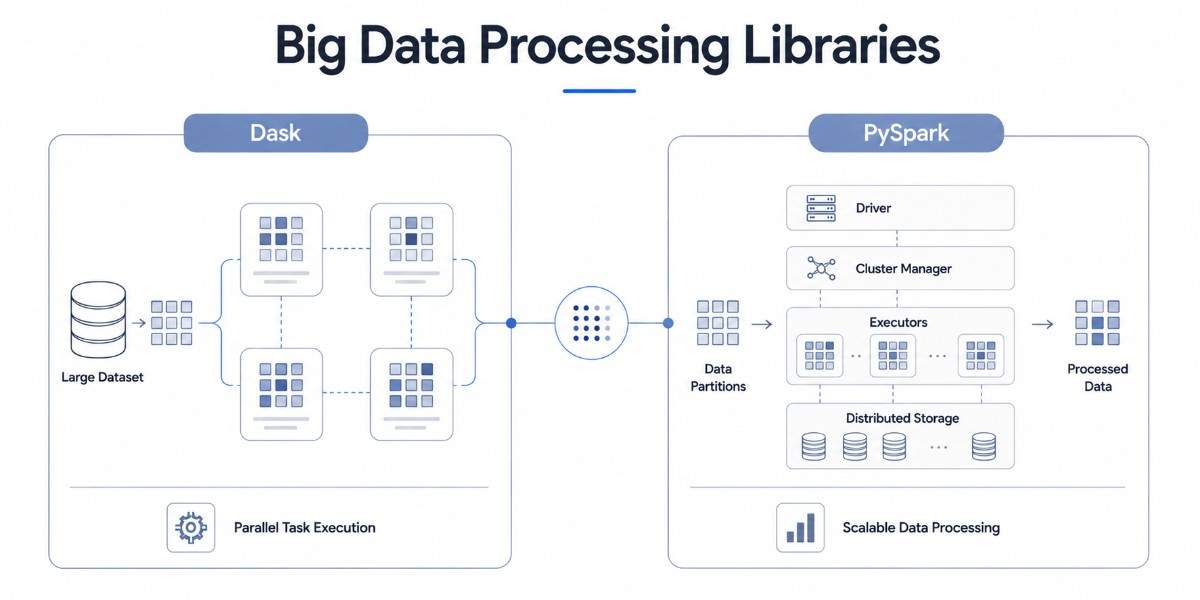
As datasets grow larger, standard dataframe libraries like Pandas can become slow and memory-intensive. This is where scalable processing frameworks such as Dask and PySpark become important, and they represent just two options within a wider ecosystem of big data tools that teams consider when designing large-scale pipelines.
In most real-world workflows, teams move from Pandas to Polars for faster single-machine processing, and then to Dask or PySpark when datasets require parallel or distributed computing across multiple systems.
A simple way to think about the scaling path is:
Under 500 MB: Pandas works fine
500 MB to 10 GB: Consider Polars or Dask
10 GB to 1 TB: Dask on a single machine or small cluster
1 TB and beyond: PySpark on a distributed cluster
Dask
Dask is a parallel computing library that extends the Pandas ecosystem for larger datasets and scalable processing. One of its biggest advantages is that it mirrors much of the Pandas API, which means developers can often scale existing Pandas workflows with minimal code changes.
The library works well for datasets that are too large for memory but still need familiar dataframe-style operations such as filtering, joins, aggregations, and group-by analysis. Dask distributes computations across multiple CPU cores and can also scale across clusters when required.
It is useful for datasets between 1 GB and 100 GB on a single machine or small cluster, when you want to parallelize existing Pandas code with minimal changes, prototyping at scale before moving to Spark.
import dask.dataframe as dd
df = dd.read_csv("large_dataset.csv")
result = (
df.groupby("category")["sales"]
.sum()
.compute()
)
print(result)For teams already using Pandas, Dask is often the easiest transition into scalable data processing because much of the syntax remains nearly identical. In many cases, existing Pandas code only requires small adjustments to work with larger datasets.
PySpark
PySpark is the Python interface for Apache Spark and is one of the most widely used frameworks for large-scale distributed data processing. It is designed for handling massive datasets across distributed clusters and is commonly used in enterprise data engineering pipelines.
The framework is widely adopted in industries such as finance, e-commerce, healthcare, and telecom, where systems process terabytes of structured and streaming data daily. PySpark supports ETL pipelines, distributed SQL queries, machine learning workflows, and real-time analytics at scale, and it typically sits upstream of the databases and storage systems where processed results land.
It is also very useful in data engineering pipelines at scale, processing hundreds of gigabytes or terabytes, and integrates well with tools like Databricks, HDFS, and Delta Lake. Teams building these kinds of workflows often pair PySpark with broader pipeline automation platforms to manage orchestration and scheduling.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(
"SalesAnalysis"
).getOrCreate()
df = spark.read.csv(
"sales.csv",
header=True
)
df.groupBy("category").sum("sales").show()Compared to Dask, PySpark is generally better suited for very large distributed systems and production-grade data engineering pipelines. However, it also comes with higher infrastructure complexity and a steeper learning curve.
For teams already working heavily with Python and Pandas, Dask offers a more gradual path into effortless computing. PySpark becomes more practical when workloads require distributed cluster processing, large-scale ETL systems, or enterprise-grade data engineering infrastructure.
LLM and Agentic AI Libraries
This is where the data science toolkit has changed. Two or three years ago, these libraries did not exist in their current form. In 2026, senior-level data scientists are increasingly expected to know how to build pipelines involving large language models.
LangChain
LangChain is the most widely used for building applications powered by large language models. It handles the plumbing, connecting an LLM to your data sources, tools, memory, and other services, so you can focus on what you want to build.
A raw LLM (like GPT or Llama) is just a model that responds to prompts. LangChain turns it into something useful: a chatbot that knows your company's documents, an AI agent that can browse the web, a pipeline that reads a database and writes a report.
LangChain is useful for building chatbots that answer questions about your data, creating AI agents that use tools, connecting LLMs to external APIs or databases, and building RAG (Retrieval-Augmented Generation) pipelines.
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Initialize an LLM
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages([
("system", "You are a data science expert. Answer questions clearly and concisely."),
("human", "{question}")
])
# Chain: prompt → LLM → parse output
chain = prompt | llm | StrOutputParser()
# Run the chain
response = chain.invoke({
"question": "What is the difference between Polars and Pandas in 2026?"
})
print(response)LlamaIndex
LlamaIndex is designed for retrieval-augmented generation (RAG) workflows, where language models retrieve information from custom datasets before generating responses.
This has become important because businesses often need AI systems to work with private documents, internal knowledge bases, PDFs, spreadsheets, and constantly changing data sources. LlamaIndex is frequently one of a broader generative AI stack that connects models, retrieval systems, and infrastructure together.
Where LangChain handles orchestration broadly, LlamaIndex excels specifically at making your data searchable and queryable by an AI.
It is widely used for enterprise search systems, AI-powered document assistants, internal knowledge management platforms, and customer support automation, where accurate retrieval from proprietary data is required.
It is best suited for building document Q&A systems, indexing internal knowledge bases, querying databases with natural language, and any scenario where "connect my data to an LLM" is the core requirement.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
# Load all documents from a folder (PDFs, Word docs, text files)
documents = SimpleDirectoryReader("./company_docs/").load_data()
# Build an index — LlamaIndex handles chunking, embedding, and storage
index = VectorStoreIndex.from_documents(documents)
# Create a query engine
query_engine = index.as_query_engine(
llm=OpenAI(model="gpt-4o")
)
# Query your documents in plain English
response = query_engine.query(
"What were the key findings from the Q1 2026 market analysis?"
)
print(response)How to Choose the Right Python Library
Choosing the right Python library is less about popularity and more about solving the problem efficiently. Many libraries offer similar functionality, but they are designed for different workloads, data sizes, and development needs.
A library that works well for exploratory analysis may not perform efficiently in a large production pipeline, while a framework built for advanced AI systems may add unnecessary complexity to a smaller project.
In most real-world workflows, teams use multiple libraries together rather than depending on a single tool. A project may use Pandas for data preparation, Scikit-learn for modeling, Plotly for visualization, and LangChain for AI integration within the same application. Understanding where each library fits helps build systems that are easier to scale, maintain, and improve over time.
Project Type
The first thing to consider is the type of problem you are solving. Different libraries are built for different workflows, and choosing tools based on actual requirements helps avoid unnecessary complexity later in the project.
For example, Pandas is widely used for data cleaning and analysis, while Scikit-learn is more suitable for traditional machine learning workflows such as classification and regression.
If the project involves deep learning, computer vision, or generative AI, frameworks like PyTorch and TensorFlow become more relevant. Similarly, LangChain and LlamaIndex are designed specifically for building LLM-powered applications and retrieval systems.
Matching the library to the workflow usually results in cleaner architecture, better performance, and simpler maintenance as the project grows.
Data Size
Dataset size plays a major role in choosing the right library. Pandas works well for smaller and medium-sized datasets, but performance can slow down significantly when handling large files or repeated transformations.
For larger analytical workloads, Polars provides faster dataframe operations and lower memory usage on a single machine. If datasets become too large for local processing, distributed frameworks such as Dask or PySpark are better suited because they can process data across multiple cores or clusters.
Choosing libraries based on scale requirements early helps avoid migration issues and performance bottlenecks in production environments.
Ecosystem Compatibility
Libraries rarely work in isolation. Most data science projects involve preprocessing, model training, visualization, deployment, and integration with external systems, so ecosystem compatibility becomes important.
Scikit-learn integrates naturally with Pandas and NumPy, making it practical for traditional ML pipelines. Plotly works well for interactive dashboards and web applications, while TensorFlow and PyTorch are more aligned with GPU-based deep learning workflows.
Choosing libraries that integrate well together reduces development friction and makes workflows more stable as systems become more complex.
Development Speed
The most advanced framework is not always the best option. In many cases, simpler libraries help teams move faster and reduce engineering overhead.
Keras simplifies deep learning workflows compared to low-level TensorFlow implementations. Seaborn makes statistical visualization easier than working directly with Matplotlib.
Dask mirrors much of the Pandas API, allowing teams to scale existing workflows without rewriting large sections of code. Balancing ease of use with scalability helps teams choose tools that fit both current requirements and long-term growth.
Recommended Stacks
For beginners learning data science, starting with NumPy, Pandas, Matplotlib, and Scikit-learn usually provides the strongest foundation because these libraries cover core analysis, visualization, and machine learning concepts.
Data analysts commonly work with Pandas, Seaborn, Plotly, and Statsmodels for reporting, visualization, and statistical analysis workflows. Machine learning engineers often rely on Scikit-learn, XGBoost, and LightGBM for predictive modeling on structured datasets.
Deep learning engineers typically use PyTorch, TensorFlow, and Transformers for neural networks, NLP systems, and generative AI applications.
Data engineering workflows increasingly depend on Polars, Dask, and PySpark for scalable processing pipelines, while AI and LLM developers use frameworks to build retrieval systems, AI assistants, and agentic workflows.
Choosing by Use Case
Projects focused on cleaning, transforming, and analyzing structured datasets generally work well with Pandas. When dataframe operations become slower as data grows, Polars is often the better choice for faster processing and lower memory consumption.
For traditional machine learning workflows, Scikit-learn remains one of the most practical libraries because of its simplicity and strong ecosystem support. XGBoost and LightGBM become more useful when working with large-scale tabular datasets where predictive performance is a priority.
Deep learning applications involving computer vision, NLP, or generative AI typically require PyTorch or TensorFlow. Projects involving RAG pipelines, AI copilots, and LLM-powered systems increasingly depend on frameworks such as LangChain and LlamaIndex.
The most practical approach is usually to start with simpler libraries and expand the stack only when performance, scalability, or AI requirements demand it.
Conclusion
The Python data science ecosystem in 2026 is more advanced than ever, but the core challenge remains the same: choosing the right tools for the type of work you are doing. While the ecosystem continues to expand with faster dataframe engines, scalable ML frameworks, and LLM application tooling, the foundation is still built around a few essential libraries that continue to power most real-world workflows.
The best approach is not to learn all 20 libraries at once. Pick the stack that matches what you are building, go deep on those five or six tools, and expand from there as your projects demand it. If you are just starting: NumPy + Pandas + Matplotlib + Seaborn + Scikit-learn.
If you have the basics and want to go further: add Polars, PyTorch, and Hugging Face Transformers, and if you are building data products or pipelines: add LangChain or LlamaIndex, and explore PySpark or Dask depending on your data scale. The libraries are the tools. What matters more is understanding the problems they solve and when to reach for each one.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us