



Introduction to bootstrapping in machine learning


Ever wondered how we can make machine learning models more accurate and reliable, even when we don’t have a massive dataset? That’s where bootstrapping comes in.
Bootstrapping is a smart technique that helps improve model performance by creating multiple new datasets from the original one. The trick? We randomly pick data points with replacement—meaning some points may appear multiple times in a sample, while others might be left out entirely.
Why does this matter? Because it helps estimate model performance, reduces overfitting, and improves stability, especially when working with smaller datasets. It’s a key player in ensemble learning methods like Bagging and Random Forests, where multiple models trained on different samples work together for better predictions.
In this article, we’ll break bootstrapping down in simple terms, explore why it’s important in machine learning, and look at real-world examples to see it in action. Let’s dive in!
Introduction to Bootstrapping
What is bootstrapping?
Bootstrapping is a resampling technique used in statistics and machine learning to improve model accuracy and reliability. It involves randomly selecting data points from a dataset with replacement to create multiple new samples. Since each new sample may contain duplicate data points while leaving others out, this method helps estimate variability and improve model performance.
In machine learning, bootstrapping is commonly used in ensemble learning techniques like Bagging (Bootstrap Aggregating) and Random Forests, where multiple models are trained on different subsets of data and combined for better predictions. This approach helps reduce overfitting, improve stability, and make models more robust, especially when dealing with small datasets.
By repeatedly resampling and analyzing different data subsets, bootstrapping allows models to generalize better to new data, making it a valuable tool in machine learning and statistical analysis.
Importance of bootstrapping in machine learning
Bootstrapping plays a crucial role in machine learning by improving model accuracy, stability, and reliability. Here’s why it’s important:
Reduces Overfitting
By training models on multiple subsets of data, bootstrapping prevents overfitting, ensuring that the model generalizes well to new data.
Improves Model Stability
Since bootstrapping creates different samples, it helps assess how a model performs across various data distributions, making it more stable and robust.
Enhances Accuracy with Ensemble Methods
Techniques like Bagging and Random Forests rely on bootstrapping to train multiple models and combine their outputs, leading to improved accuracy and reduced variance.
Useful for Small Datasets
When the available data is limited, bootstrapping allows better estimation of model performance by generating multiple resampled datasets.
Helps in Uncertainty Estimation
Bootstrapping provides a way to measure the confidence of model predictions by analyzing variations across different samples.
Overall, bootstrapping is a powerful tool that strengthens machine learning models, making them more reliable and effective, especially in real-world applications.
Benefits of using bootstrapping in data analysis and modeling
.png)
Bootstrapping is a widely used technique in data analysis and machine learning that offers several advantages, especially when working with small datasets or uncertain data distributions. Here are some key benefits:
1. Improves Model Reliability
Bootstrapping helps estimate the variability of data, making statistical and machine learning models more robust.
It reduces the risk of relying on a single dataset by generating multiple resampled versions.
2. Reduces Overfitting
By creating different subsets of data, bootstrapping prevents models from learning noise, leading to better generalization.
This is especially useful in ensemble methods like Bagging and Random Forests.
3. Enhances Accuracy and Stability
When combined with ensemble learning, bootstrapping improves predictive performance by aggregating multiple models.
It helps smooth out anomalies and ensures the model performs well on unseen data.
4. Works Well with Small Datasets
Traditional statistical methods require large datasets for accurate estimation, but bootstrapping enables effective analysis even with limited data.
It provides reliable estimates of confidence intervals and standard errors.
5. Helps in Uncertainty Estimation
Bootstrapping can measure the uncertainty of predictions, making it useful for applications where confidence levels are important, such as medical diagnosis and financial modeling.
6. No Assumption of Data Distribution
Unlike parametric methods that assume a specific data distribution (e.g., normal distribution), bootstrapping works well with any data type.
This makes it flexible for various real-world applications.
Bootstrapping enhances model performance, reduces overfitting, and provides better estimates of statistical properties. Whether in machine learning or traditional data analysis, it is a valuable tool for building more reliable models.
How Bootstrapping Works
Bootstrapping is a straightforward yet powerful way to make machine learning models more accurate and stable. It works by creating multiple new datasets from the original one through random sampling with replacement. This means some data points might show up more than once in a sample, while others might not appear at all. By training models on these different samples, we can get a more reliable estimate of performance and reduce overfitting.
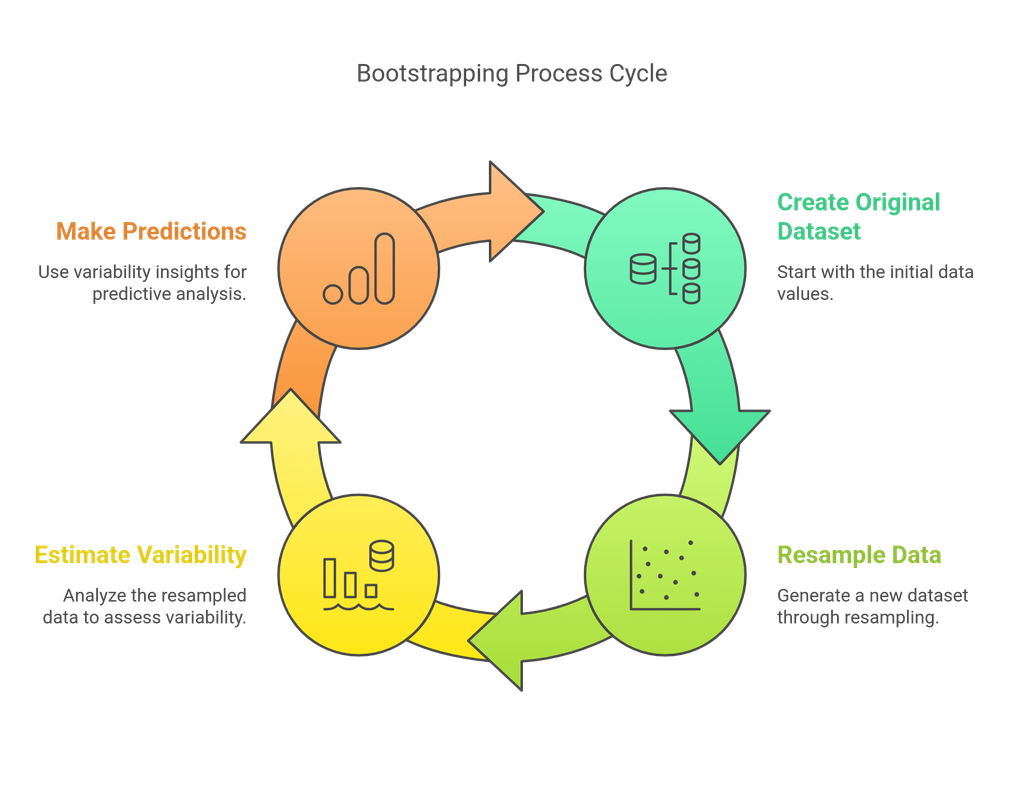
Steps in Bootstrapping
Original Dataset
Start with a dataset containing nnn observations.
Random Sampling with Replacement
Select nnn data points randomly, allowing duplicates.
Create Multiple Samples
Repeat the process multiple times to generate several bootstrap samples.
Train Models or Compute Statistics
Use these samples to train models, estimate statistical properties (like mean or standard deviation), or make predictions.
Aggregate Results
Combine the results from different samples to improve accuracy and reduce variability.
Example:
Let’s say you have a small dataset with just five numbers:
[2, 4, 6, 8, 10]
Now, if we apply bootstrapping, we randomly pick numbers with replacements to create a new sample. One possible resampled dataset could be:
[4, 4, 6, 10, 2]
Notice how some numbers appear more than once, while others are missing entirely. By repeating this process multiple times, we can analyze the variability in our data and build more reliable models.
Bootstrapping in Machine Learning
In machine learning, bootstrapping is widely used in ensemble learning techniques like Bagging (Bootstrap Aggregating). For example, Random Forests train multiple decision trees on different bootstrap samples and combine their predictions for more accurate results.
By generating multiple samples and aggregating the results, bootstrapping helps improve model performance, reduce overfitting, and make better predictions even with limited data.
Why Use Bootstrapping in Machine Learning?
Bootstrapping is a go-to technique in machine learning because it helps models perform better, prevents overfitting, and makes predictions more reliable. By repeatedly sampling data with replacement, it gives us a better sense of uncertainty and improves accuracy especially when working with smaller datasets.
Key Reasons to Use Bootstrapping
Reduces Overfitting
Bootstrapping creates multiple datasets from the original data, allowing models to learn from different variations.
This prevents overfitting, where a model memorizes the training data but fails on new data.
Improves Model Stability
By training on different bootstrap samples, models become more robust and less sensitive to variations in data.
This ensures better generalization to real-world scenarios.
Enhances Accuracy with Ensemble Methods
Bootstrapping is a key component of Bagging (Bootstrap Aggregating), where multiple models are trained on different samples and combined for better accuracy.
Random Forests, a popular machine learning algorithm, use bootstrapping to train multiple decision trees and aggregate their results.
Useful for Small Datasets
When data is limited, bootstrapping allows models to learn effectively by creating multiple resampled datasets.
This helps estimate the reliability of a model even when large datasets are unavailable.
Helps Estimate Uncertainty and Confidence Intervals
Bootstrapping provides a way to measure the uncertainty in model predictions by generating multiple estimates from different samples.
It is useful for building confidence intervals in regression models and statistical inference.
Bootstrapping is an essential technique in machine learning that improves model reliability, enhances accuracy, and reduces overfitting. By leveraging resampling, it allows models to generalize better, making it a powerful tool for data-driven decision-making.
Role of Bootstrapping in Machine Learning
Bootstrapping plays a crucial role in machine learning by improving model performance, increasing stability, and providing better estimates for statistical analysis. It helps in handling small datasets, reducing overfitting, and enhancing the accuracy of predictive models.
Key Roles of Bootstrapping in Machine Learning
1. Foundation of Ensemble Learning
Bootstrapping is a core technique in Bagging (Bootstrap Aggregating), where multiple models are trained on different resampled datasets.
It helps create diverse models, reducing variance and improving overall accuracy.
Example: Random Forests use bootstrapping to train multiple decision trees and combine their outputs for better predictions.
2. Reducing Overfitting
Overfitting occurs when a model learns patterns too specifically from training data, making it ineffective for unseen data.
By generating multiple datasets and averaging results, bootstrapping prevents models from becoming too dependent on specific data points.
3. Improving Model Stability
Training models on different bootstrap samples helps ensure consistency in predictions, reducing dependence on a single dataset.
This makes models more robust and generalizable to real-world data.
4. Handling Small Datasets Effectively
When data is limited, bootstrapping helps maximize the use of available samples.
It provides multiple variations of the dataset, improving estimation accuracy.
5. Estimating Uncertainty & Confidence Intervals
Bootstrapping is useful for computing confidence intervals and measuring the uncertainty of model predictions.
This is particularly valuable in regression models, hypothesis testing, and statistical inference.
Bootstrapping is a powerful tool in machine learning that enhances accuracy, prevents overfitting, and improves model stability. By leveraging resampling techniques, it plays a fundamental role in ensemble learning, uncertainty estimation, and small-data modeling, making it an essential technique for data scientists and machine learning engineers.
Real-World Use Cases of Bootstrapping in Machine Learning
Bootstrapping is widely used in various real-world machine learning applications to improve model performance, estimate uncertainty, and handle small datasets. Below are some key use cases where bootstrapping plays a crucial role
1. Random Forests for Predictive Modeling
Use Case: Fraud detection, recommendation systems, medical diagnosis
How Bootstrapping Helps: Random Forests rely on bootstrapping to train multiple decision trees using different resampled datasets. This diversity leads to more stable and accurate predictions.
Example: In fraud detection, bootstrapping helps create multiple models that analyze financial transaction patterns. Since each model learns from a slightly different dataset, they collectively improve fraud detection by identifying suspicious activities that a single model might miss.
2. Bagging to Reduce Variance in Models
Use Case: Stock price prediction, customer churn analysis
How Bootstrapping Helps: Bagging (Bootstrap Aggregating) trains multiple models on different bootstrap samples and combines their outputs. This reduces variance, making the model more reliable and less prone to overfitting.
Example: For customer churn prediction, bagging ensures that the model generalizes well instead of memorizing specific customer behaviors. This way, businesses can better predict which customers are likely to leave and take proactive measures to retain them.
3. Estimating Confidence Intervals in Financial Forecasting
Use Case: Stock market analysis, risk assessment
How Bootstrapping Helps: By generating multiple samples from historical stock market data, bootstrapping helps estimate confidence intervals for stock price predictions. This provides a clearer picture of potential risks and returns.
Example: A financial analyst can use bootstrapping to estimate the reliability of a stock’s future returns. Instead of relying on a single prediction, bootstrapping helps create a range of possible outcomes, reducing uncertainty and improving decision-making.
4. Medical Research and Clinical Trials
Use Case: Disease prediction, drug effectiveness testing
How Bootstrapping Helps: In medical research, bootstrapping is used to estimate treatment effectiveness by resampling patient data. This approach helps researchers analyze results without requiring a massive patient sample.
Example: When testing a new drug, bootstrapping helps determine the accuracy of success rates by creating different simulated patient groups. This allows researchers to make data-driven conclusions about the drug’s effectiveness, even with limited trial participants.
5. NLP and Sentiment Analysis
Use Case: Sentiment classification, chatbot training
How Bootstrapping Helps: Bootstrapping helps create diverse training datasets for Natural Language Processing (NLP) models by resampling text data. This improves the model’s ability to generalize across different writing styles and tones.
Example: In sentiment analysis, bootstrapping enables models to train on multiple variations of user reviews. This improves their ability to detect whether a review is positive, negative, or neutral, making them more effective in real-world applications like customer feedback analysis.
6. Image Classification with Deep Learning
Use Case: Autonomous vehicles, medical imaging
How Bootstrapping Helps: In deep learning, bootstrapping is used to create diverse image datasets by resampling existing labeled images. This helps train robust models, especially when data is scarce.
Example: In medical imaging, bootstrapping helps train AI models to detect diseases like pneumonia from X-ray images. By generating multiple variations of training data, the model learns to recognize disease patterns more accurately, even when working with a limited number of medical scans.
Python Implementation of Bootstrapping
Stock Market Example
.png)
Bootstrapping is useful in finance for estimating stock return distributions, calculating confidence intervals, and assessing risk. Below is an example where we apply bootstrapping to estimate the mean daily return of a stock and compute a 95% confidence interval.
Example: Estimating Stock Returns with Bootstrapping
import numpy as np
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
# Fetch historical stock data (e.g., Apple stock)
stock = 'AAPL'
data = yf.download(stock, start="2023-01-01", end="2024-01-01")
# Calculate daily returns
data['Returns'] = data['Adj Close'].pct_change().dropna()
# Convert returns to NumPy array
returns = data['Returns'].dropna().values
# Bootstrapping parameters
n_bootstrap_samples = 1000
bootstrap_means = []
# Perform bootstrapping
for _ in range(n_bootstrap_samples):
sample = np.random.choice(returns, size=len(returns), replace=True) # Resampling with replacement
bootstrap_means.append(np.mean(sample))
# Compute 95% confidence interval
lower_bound = np.percentile(bootstrap_means, 2.5)
upper_bound = np.percentile(bootstrap_means, 97.5)
# Print results
print(f"Estimated Mean Daily Return: {np.mean(bootstrap_means):.6f}")
print(f"95% Confidence Interval: ({lower_bound:.6f}, {upper_bound:.6f})")
# Plot bootstrapped mean distribution
plt.hist(bootstrap_means, bins=30, alpha=0.7, color='blue', edgecolor='black')
plt.axvline(np.mean(bootstrap_means), color='red', linestyle='dashed', linewidth=2, label="Mean Return")
plt.axvline(lower_bound, color='green', linestyle='dashed', linewidth=2, label="95% CI Lower")
plt.axvline(upper_bound, color='green', linestyle='dashed', linewidth=2, label="95% CI Upper")
plt.legend()
plt.xlabel('Mean Daily Return')
plt.ylabel('Frequency')
plt.title(f'Bootstrapped Mean Daily Returns Distribution for {stock}')
plt.show()How This Works
1. Fetch Historical Data
We use yfinance to pull Apple’s stock data from January 2023 to January 2024.
2. Calculate Returns
We compute the daily percentage change in adjusted closing prices.
3. Bootstrapping Process
Randomly resample daily returns with replacement multiple times. Compute the mean return for each bootstrap sample.
4. Confidence Interval Estimation
Find the 2.5th and 97.5th percentiles to create a 95% confidence interval for the mean return.
5. Visualization
A histogram shows the distribution of bootstrapped mean returns, with confidence intervals highlighted.
Why does this matter? Bootstrapping helps analyze stock returns by providing reliable statistical estimates and confidence intervals. This makes it a powerful tool for financial risk assessment and smarter investment decisions. Traders and analysts can use it to better understand market uncertainties and make more informed choices.
Bootstrap Sampling to Estimate Confidence Interval of Model Accuracy
We'll use scikit-learn for a basic classification model and numpy to perform bootstrap resampling.
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
# Load dataset
data = load_iris()
X, y = data.data, data.target
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Train model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Get original test accuracy
original_accuracy = accuracy_score(y_test, model.predict(X_test))
# Bootstrap sampling
n_bootstrap = 1000 # Number of bootstrap samples
bootstrap_accuracies = []
for _ in range(n_bootstrap):
# Sample with replacement
indices = np.random.choice(len(X_test), len(X_test), replace=True)
X_sample, y_sample = X_test[indices], y_test[indices]
# Evaluate accuracy on bootstrap sample
acc = accuracy_score(y_sample, model.predict(X_sample))
bootstrap_accuracies.append(acc)
# Compute confidence interval (95%)
lower_bound = np.percentile(bootstrap_accuracies, 2.5)
upper_bound = np.percentile(bootstrap_accuracies, 97.5)
# Print results
print(f'Original Accuracy: {original_accuracy:.4f}')
print(f'95% Confidence Interval: [{lower_bound:.4f}, {upper_bound:.4f}]')Explanation
- We train a RandomForest model on the Iris dataset.
- We then create 1000 bootstrap samples from the test set.
- For each bootstrap sample, we compute model accuracy and store it.
- We calculate the 95% confidence interval using percentiles.
Why Use Bootstrap Sampling?
- It helps estimate the variability of model accuracy.
- Works well for small datasets where traditional confidence intervals may not be reliable.
- No strong assumptions about the data distribution are needed.
This method gives a more robust understanding of model performance beyond just a single accuracy score
Key Advantages of Bootstrapping
Works with Small Datasets
Generates multiple samples from limited data, making it useful in finance, medicine, and AI.
Reduces Overfitting
Helps models generalize better by training on different dataset variations (e.g., Bagging).
Estimates Uncertainty
It provides confidence intervals and standard errors, which are crucial for financial and medical predictions.
Boosts Accuracy
Forms the backbone of Random Forests, improving model stability and performance.
No Assumptions Needed
Works with any data type, unlike parametric methods that require a specific distribution.
Easy to Implement
Simple to apply using Python (NumPy, pandas, Scikit-learn).
Enhances Ensemble Learning
Powers techniques like Bagging and Boosting for better AI predictions.
Bootstrapping is a game-changer whether for small datasets, uncertainty estimation, or building powerful machine learning models.
Challenges of Bootstrapping
Computationally Expensive
Generating multiple samples increases processing time and memory usage.
Struggles with Correlated Data
May not create diverse samples if data points are too similar.
Sensitive to Outliers
Some data points may be selected too often, distorting results.
May Misestimate Variability
Works best with a well-represented dataset; small samples can mislead results.
Less Effective for Tiny Datasets
Extremely small datasets (fewer than 10 points) may not yield meaningful insights.
Relies on Original Data Quality
If the dataset is biased, bootstrapping can amplify those biases.
Not Ideal for Time Series
Standard bootstrapping ignores data order, requiring specialized techniques.
Bootstrapping is powerful, but understanding its limits ensures better decision-making and more reliable models!
Conclusion
Bootstrapping is a powerful technique in machine learning that enhances model stability, improves predictions, and estimates statistical parameters with confidence. It plays a critical role in ensemble methods like bagging and is widely used for assessing model performance. While computationally intensive, its advantages make it a valuable tool for practitioners dealing with uncertainty in data analysis and machine learning applications.
By understanding and applying bootstrapping, data scientists and machine learning engineers can build more robust and reliable models that generalize well to unseen data.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us