



Guide to Data Processing in ML with Steps, Techniques, and Applications



Data Processing Maturity Model for ML
Assess and improve your data pipeline maturity
Data processing in machine learning is the process of collecting, cleaning, transforming, and organizing raw data into a structured format suitable for training models. It ensures data quality, consistency, and usability, directly impacting model accuracy and performance.
Within this process, data preprocessing is a key subset that focuses specifically on cleaning and transforming data before it is used by machine learning algorithms.
Why Data Processing Matters in Machine Learning Models
Data processing plays a fundamental role in determining how well a machine learning model performs. Since models learn patterns directly from data, their accuracy and reliability are heavily dependent on the quality, consistency, and structure of the input data.
In real-world scenarios, poor data can lead to serious failures. For example, if a fraud detection model is trained on incomplete or biased transaction data, it may incorrectly flag legitimate transactions or fail to detect actual fraud. This highlights the direct impact of bad data on predictions and business outcomes.
Effective data processing helps address these issues and delivers several key benefits:
- Better accuracy: Clean and well-structured data allows models to learn meaningful patterns, leading to more accurate predictions.
- Faster training: Properly processed data reduces noise and complexity, improving training efficiency and reducing computation time.
- Reduced bias: Handling imbalanced or inconsistent data ensures fairer and more reliable model performance across different scenarios.
Understanding the Complete ML Data Pipeline
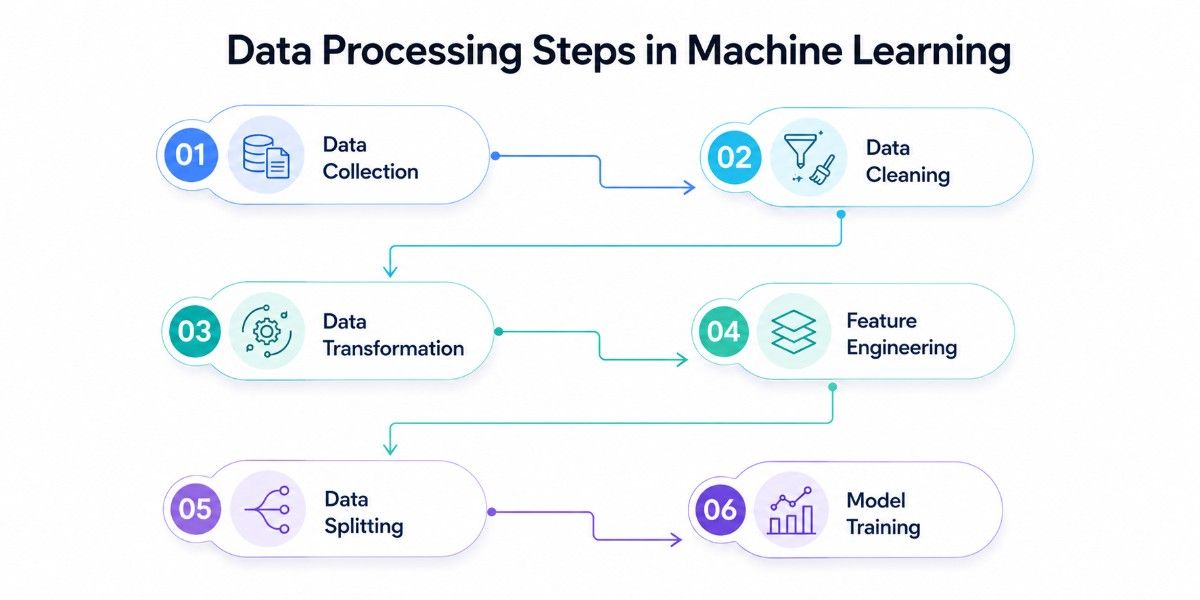
Building a successful machine learning model is not just about choosing the right algorithm; it starts with a well-structured data pipeline. This pipeline ensures that raw, unstructured data is systematically refined into a format that models can effectively learn from, improving both accuracy and reliability.
1. Data Collection
Data collection is the foundation of the pipeline, gathering raw data from sources such as databases, APIs, sensors, logs, and user interactions. The relevance, diversity, and volume of this data directly impact how well a model can learn patterns, so spending time exploring it through early data analysis is critical to understanding its structure and quality.
Poor or insufficient data at this stage can limit model performance regardless of later improvements. Ensuring high-quality, representative data, covering all possible scenarios, is critical for building high-performance machine learning systems.
2. Data Cleaning
Data cleaning focuses on identifying and fixing issues within the dataset, such as missing values, duplicate records, inconsistent formats, and noisy or incorrect entries. It forms a core part of data preprocessing, preparing raw data for transformation and modeling and ensuring it remains accurate and reliable.
Without proper cleaning, models may learn incorrect patterns or biases, leading to poor predictions. Techniques like imputing missing values, removing outliers, and standardizing formats help improve overall data quality and model trustworthiness.
3. Data Transformation
Data transformation converts raw data into a structured and usable format suitable for machine learning algorithms. This includes encoding categorical variables, normalizing or standardizing numerical values, and reshaping datasets into consistent formats.
This step is essential because most machine learning algorithms require numerical and well-scaled inputs. Proper transformation helps models converge faster, improves performance, and ensures that different features contribute proportionately during training.
4. Feature Engineering
Feature engineering involves creating, selecting, and refining features to enhance the predictive power of a model. It includes generating new features from existing data, selecting the most relevant variables, and reducing dimensionality when necessary.
This step often has the greatest impact on model performance. Well-engineered features help models capture meaningful patterns, reduce noise, and improve accuracy, making it a key differentiator in high-performing machine learning systems.
5. Data Splitting
Data splitting divides the processed dataset into training, testing, and sometimes validation sets. This ensures that the model is trained on one portion of the data and evaluated on unseen data to measure its real-world performance.
Without proper splitting, models can overfit, performing well on training data but failing in real scenarios. A well-structured split helps in building models that generalize effectively and provide reliable predictions.
6. Model Training
Model training is the stage where machine learning algorithms learn patterns from the prepared data. The model adjusts its internal parameters based on the training data, which is supported by Python frameworks used in a production environment to minimize errors and improve prediction accuracy.
The effectiveness of this stage heavily depends on the quality of the previous steps. Clean, well-structured, and meaningful data enables faster convergence, better learning, and ultimately stronger model performance.
Difference Between Data Processing and Preprocessing in ML
Understanding the difference between data processing and preprocessing is important for building a clear machine learning workflow. While both are closely related, they operate at different levels. One is a broad, end-to-end process, and the other is a focused step within it.
The difference between data processing and preprocessing lies in their scope and purpose. Data processing is the broader workflow that transforms raw data into a usable form, while data preprocessing is a critical step within it that ensures the data is clean, structured, and ready for machine learning models.
Step by Step Guide to Data Preprocessing in ML
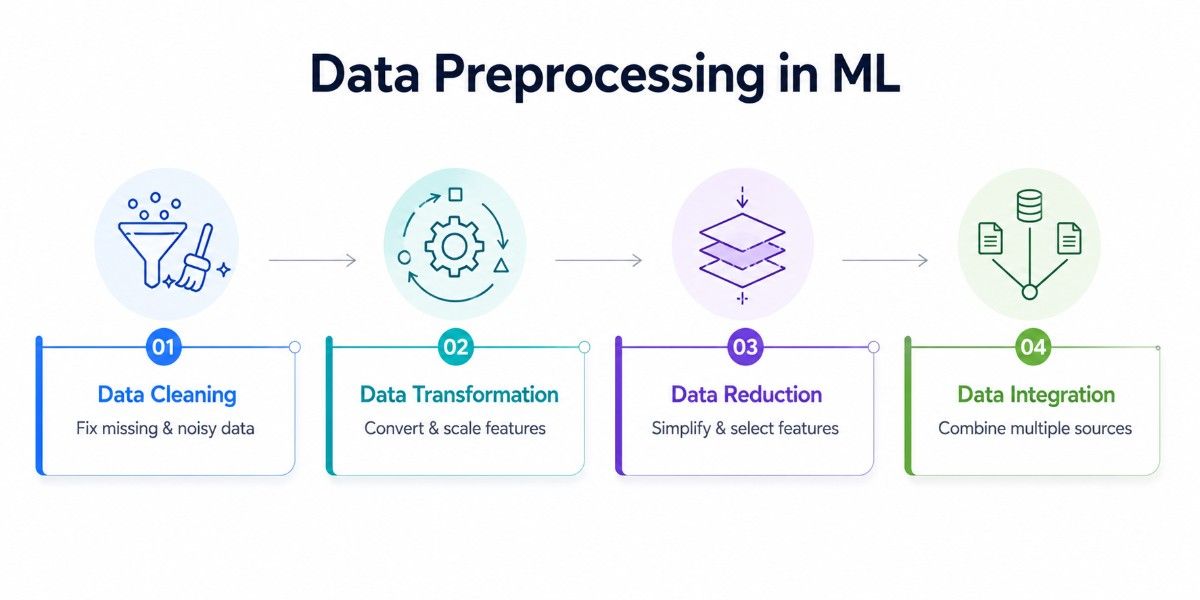
Data preprocessing is a structured process that transforms raw, unorganized data into a clean and machine-readable format. Each step plays a specific role in improving data quality, ensuring consistency, and enabling machine learning models to learn meaningful patterns effectively.
1. Data Cleaning
Data cleaning is the first and most essential step, focused on improving the quality and reliability of the dataset. Real-world data is often incomplete, inconsistent, or noisy, which can negatively impact model performance if not handled properly.
This step involves handling missing values using techniques like mean, median, or mode imputation, or removing records when necessary. It also includes identifying and removing duplicate entries, correcting inconsistencies, and filtering out noise or irrelevant data to ensure accuracy and consistency across the dataset.
For example, in a customer dataset, correcting missing income values or removing duplicate user entries can significantly improve prediction accuracy and ensure more trustworthy results.
2. Data Transformation
Once the data is clean, it needs to be transformed into a format that machine learning algorithms can understand. Since most models work with numerical inputs, this step converts raw data into structured and usable forms.
This includes encoding categorical variables using techniques like label encoding or one-hot encoding, and applying feature scaling methods such as normalization and standardization. Proper transformation ensures that all features contribute fairly during training and prevents bias caused by differences in data ranges.
For instance, scaling features like age and income ensures that large numerical differences do not skew the learning process, allowing the model to treat all inputs fairly and converge faster during training.
3. Data Reduction
Data reduction focuses on simplifying the dataset while preserving its essential information. Large datasets with too many features can increase computational complexity and may introduce noise that affects model performance.
This step involves feature selection, where only the most relevant variables are retained, and dimensionality reduction techniques like PCA (Principal Component Analysis), which transform data into fewer dimensions while maintaining important patterns.
Reducing unnecessary data helps improve model efficiency and accuracy. For example, removing redundant features in a dataset can speed up training time and reduce overfitting, enabling the model to generalize better on new, unseen data.
4. Data Integration
Data integration involves combining data from multiple sources into a unified dataset. In real-world scenarios, data often comes from different systems, formats, or databases, making integration a critical step in preprocessing.
This process includes merging datasets, resolving schema differences, and handling inconsistencies such as mismatched formats or duplicate attributes.
Proper integration ensures that the final dataset is consistent, complete, and ready for further processing and model training, while modeling tools help structure relationships across different data sources in a more organized way.
For example, combining customer transaction data with demographic data can help build more accurate predictive models, as it brings together multiple dimensions of information into a single, cohesive dataset.
Each step in data preprocessing, cleaning, transformation, reduction, and integration works together to improve data quality and usability. When executed properly, these steps enable machine learning models to train more efficiently, reduce errors, and deliver more accurate and reliable predictions.

What Is Feature Engineering in Machine Learning?
Feature engineering is where raw data starts becoming truly useful for machine learning. It focuses on shaping input variables in a way that makes patterns clearer and more meaningful for the model.
In the overall data processing workflow, feature engineering comes after basic preprocessing and plays a more strategic role. It is the process of modifying or enhancing input features so that models can better understand relationships within the data.
It goes beyond cleaning and formatting by focusing on improving the quality of information rather than just its structure. Even with clean data, models can struggle if the features do not clearly represent the problem.
For example, converting a timestamp into separate features like day, month, or hour can reveal patterns that raw data would not show directly. This is why feature engineering often has a direct impact on how well a model performs.
Types of Feature Engineering Techniques
Feature engineering techniques can be grouped into three main approaches, each helping improve the dataset differently.
1. Feature Creation
This involves generating new features from existing ones to uncover deeper insights. It could be as simple as combining two variables or extracting useful components from complex data. These new features often capture patterns that were not obvious before.
2. Feature Selection
Feature selection in ML focuses on keeping only the most useful features and removing the rest. Not all data points contribute equally; some may be redundant or even harmful. By selecting the right features, you reduce noise, simplify the model, and improve performance.
3. Feature Extraction
Feature extraction transforms data into a new representation, often reducing the number of features while keeping the important information intact. Techniques like PCA help compress data into fewer dimensions, making it easier for models to process without losing key patterns.
Feature engineering improves performance by making patterns easier for the model to detect. When inputs are well-structured and meaningful, the model does not have to work as hard to learn relationships, which leads to better accuracy and faster training.
It also helps avoid overfitting by removing unnecessary features and focusing only on what matters. In practice, well-engineered features often make a bigger difference than switching between algorithms, as they directly influence how effectively the model learns from the data.
Types of Data Processing in Machine Learning
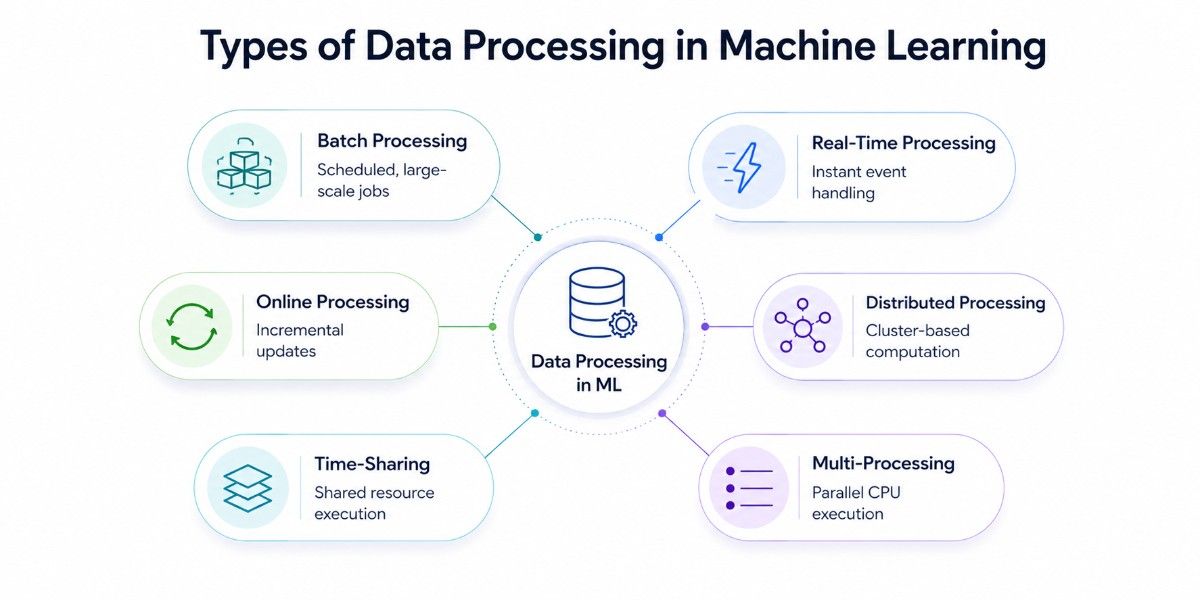
When most people think about data processing in machine learning, they imagine a single, linear pipeline: collect data, clean it, and feed it into a model. In reality, the way you process data depends heavily on when results are needed, how much data you’re handling, and where that data lives.
There are six primary approaches, each suited to different workloads, data volumes, and latency requirements.
Batch Processing
Batch processing remains the most widely used approach, where data is collected over a period and processed all at once on a scheduled basis. The entire dataset is loaded, transformed, and passed through the pipeline from start to finish, producing outputs only after the job completes.
This makes it ideal for training models on historical data, running ETL workflows, or generating predictions that do not require immediate results.
For example, an e-commerce platform might retrain its recommendation model every night using the previous day’s transactions, processing millions of rows in one run and deploying an updated model by morning.
While this approach is reliable and scalable with tools like Spark or Hadoop, it inherently introduces delay because results are tied to batch intervals, and failures can require reprocessing the entire dataset.
Real-Time (Stream) Processing
Real-time processing handles data continuously as it arrives, enabling systems to react within milliseconds instead of waiting for scheduled jobs. Each event, whether it’s a user click, sensor reading, or transaction, is processed and scored immediately, with features computed on the fly.
This approach is essential in scenarios like fraud detection, live personalisation, or anomaly detection, where decisions must happen instantly. For instance, a bank can stream transactions through a system that evaluates risk in under a second before approving or flagging a payment.
However, this speed comes at the cost of significantly higher system complexity, especially when dealing with out-of-order events, late data, and state management, making it unnecessary unless low latency is critical.
Online (Incremental) Processing
Online processing sits between batch and real-time by updating models and preprocessing logic incrementally as new data arrives, rather than retraining from scratch. Instead of recomputing everything, the system continuously adjusts using new data points or mini-batches.
This is particularly useful in environments where data evolves, such as recommendation systems or financial models that need to reflect changing behavior. A news platform, for example, can update user preferences dynamically as users interact with content, improving recommendations without waiting for a full retrain cycle.
While this enables adaptability and efficiency, it introduces challenges in monitoring and stability, as noisy or anomalous data can quickly degrade model performance if not handled carefully.
Distributed Processing
Distributed processing focuses on how computation is performed by spreading data and workloads across multiple machines. Large datasets are partitioned and processed in parallel across a cluster, allowing systems to handle volumes far beyond the limits of a single machine.
This approach becomes necessary when working with massive datasets, complex joins, or large-scale model training. For example, a logistics company can process years of shipping data across a cluster in under an hour, a task that would take days on a single server.
While powerful, distributed systems introduce infrastructure overhead and network latency, which means they are most effective only at scale and can be inefficient for smaller workloads.
Time-Sharing (Multi-Tenant) Processing
Time-sharing allows multiple workloads or users to share the same infrastructure, with resources dynamically allocated across tasks. Instead of dedicating machines to a single job, systems schedule and manage multiple processes concurrently, often handled automatically by cloud platforms.
This is particularly valuable for teams running multiple experiments or for organizations optimizing costs by avoiding dedicated clusters.
However, since resources are shared, performance can become less predictable, especially during peak usage when multiple workloads compete for the same compute capacity.
Multi-Processing (Parallel Processing)
Multi-processing improves performance by using multiple CPU cores within a single machine to process data in parallel. The dataset is divided into chunks, each handled by a separate process, and the results are combined at the end.
This approach is well-suited for medium-sized datasets or compute-heavy tasks like image processing or NLP feature extraction, where parallel execution can significantly reduce processing time without requiring distributed infrastructure.
It also works well for speeding up operations like cross-validation. However, since it is limited to a single machine, it does not scale beyond the available hardware and cannot handle extremely large datasets as distributed systems can.
How to Handle Common Data Problems in ML
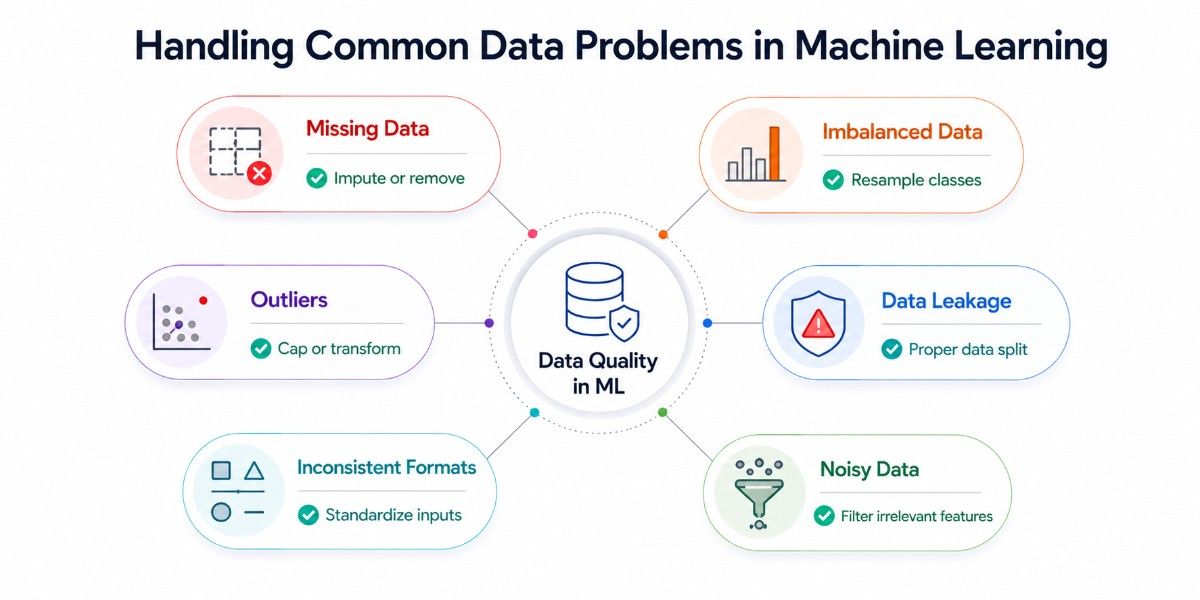
In real-world projects, data rarely comes in a perfect, ready to use format. Even after basic preprocessing, there are underlying issues that can quietly affect model performance if not handled properly. The key is not just identifying these problems, but knowing how to deal with them practically.
Missing Data
Missing values are almost unavoidable, whether due to system errors, incomplete inputs, or data collection gaps. If ignored, they can distort patterns and lead to unreliable predictions, especially when large portions of data are affected.
The impact depends on where and how frequently the data is missing. For example, missing values in critical features like income or age can significantly affect model outcomes, while minor gaps may have less impact.
In practice, start by analyzing the pattern of missing data. Use median or mean imputation for numerical fields, and the most frequent value for categorical ones. If a column has too many missing values (e.g., >40–50%), it’s often better to drop it. For more advanced cases, use model-based imputation like KNN or predictive filling.
Imbalanced Datasets
Imbalanced datasets are common in real-world use cases like fraud detection or disease prediction, where one class is much rarer than the other. Models trained on such data tend to favor the majority class, giving misleadingly high accuracy but poor real-world performance.
The challenge is not just imbalance, but ensuring the model actually learns to detect the minority class effectively. Simply training on raw data often results in biased predictions.
A practical approach is to first check class distribution, then apply techniques like oversampling (e.g., duplicating the minority class or using SMOTE) or undersampling the majority class. Also, switch evaluation metrics, use precision, recall, and F1-score instead of accuracy to properly measure model performance.
Outliers
Outliers are data points that fall far outside the normal range. Sometimes they represent real but rare events, and other times they are simply errors or noise. If not handled carefully, they can heavily influence model behavior, especially in regression tasks.
The key is understanding whether an outlier is valid or not. Blindly removing all outliers can lead to loss of important information, while ignoring them can skew results.
In practice, visualize data using box plots or scatter plots to identify outliers. If they are errors, remove them. If they are valid but extreme, consider capping them (winsorization) or applying transformations like log scaling to reduce their impact without losing information.
Data Leakage
Data leakage is one of the most serious and often overlooked problems in machine learning. It happens when information that should not be available during training unintentionally influences the model, leading to unrealistically high performance during testing.
This usually occurs when preprocessing is applied before splitting data, or when future information leaks into the training set. The result is a model that performs well in evaluation but fails in real-world use.
To avoid this, always split your data into training and testing sets before any preprocessing. Apply transformations like scaling or encoding only on training data, then apply the same logic to test data. Also, carefully review features to ensure none of them directly or indirectly contain target information.
Inconsistent Data Formats
When working with multiple data sources, inconsistencies are common, such as different date formats, units, naming conventions, or even mismatched categories. These issues can silently break models or lead to incorrect interpretations.
The problem becomes more complex when integrating datasets, where even small mismatches can cause alignment issues or data duplication.
A practical way to handle this is to standardize formats early in the pipeline. Convert dates into a single format, unify measurement units, and normalize categorical labels. Creating a data validation step or schema check helps catch these issues before they impact the model.
Noisy and Irrelevant Data
Not all data is useful. Some features may add noise rather than value, making it harder for the model to identify meaningful patterns. This often results in reduced accuracy and overfitting.
The challenge is identifying which data is actually contributing and which is just adding complexity.
In practice, start with basic correlation analysis or feature importance techniques to identify irrelevant features. Remove or reduce noisy variables, and focus on inputs that have a clear relationship with the target, this makes the model simpler, faster, and more effective.
Handling data issues is not just a preprocessing step; it’s an ongoing process that requires the right tools and an experienced ML team to handle it effectively, as it directly impacts model success. By addressing these issues with practical methods, you ensure that your model learns from reliable and meaningful data, leading to stronger real-world performance.
Data Preprocessing Example Using Python
Understanding how preprocessing works is useful, but understanding why each step is done is what actually helps in real projects. Below is a simple, practical walkthrough using AI libraries like Pandas and Scikit-learn, explaining not just the steps, but the reasoning behind them.
Let’s take a small dataset that includes missing values, categorical data, and features with different scales, common issues in real-world datasets.
Step 1: Load and Inspect the Data
Before making any changes, it’s important to understand what the data looks like. This step helps identify missing values, data types, and potential inconsistencies that need to be addressed.
import pandas as pd
data = {
'Age': [25, 30, None, 35, 40],
'Salary': [50000, 60000, 55000, None, 65000],
'Department': ['IT', 'HR', 'IT', 'Finance', 'HR']
}
df = pd.DataFrame(data)
print(df)
print(df.isnull().sum())By inspecting the dataset, you can clearly see where values are missing and which columns need attention. Skipping this step often leads to incorrect assumptions and poor preprocessing decisions later.
Step 2: Handle Missing Values
Machine learning models cannot work with missing (NaN) values, so they must be handled before moving forward. Ignoring them can either break the model or introduce bias.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean')
df[['Age', 'Salary']] = imputer.fit_transform(df[['Age', 'Salary']])Here, missing values are replaced with the mean of the column. This is a simple and commonly used approach when data is fairly evenly distributed. The idea is to fill gaps without significantly altering the overall data pattern.
In practice, the choice of method depends on the dataset. For skewed data, the median works better, and for categorical data, the most frequent value is typically used. The goal is to retain as much information as possible without introducing distortion.
Step 3: Encode Categorical Data
Machine learning algorithms work with numbers, not text. So, categorical values like “IT” or “HR” must be converted into a numerical format.
df = pd.get_dummies(df, columns=['Department'])This applies one-hot encoding, where each category becomes a separate column with binary values (0 or 1). This ensures that the model does not assume any ordinal relationship between categories.
For example, without proper encoding, a model might incorrectly assume “HR” > “IT”, which is not meaningful. Encoding removes this ambiguity and allows the model to interpret categories correctly.
Step 4: Scale the Features
Different features often have different ranges, salary might be in thousands, while age is much smaller. This imbalance can cause models to give more importance to larger values.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['Age', 'Salary']] = scaler.fit_transform(df[['Age', 'Salary']])Scaling standardizes the data so that all features contribute equally during training. This is especially important for algorithms like gradient descent, KNN, or SVM, which are sensitive to feature magnitude.
Without scaling, the model may converge slowly or produce suboptimal results because it is biased toward features with larger numerical values.
Final Output
After these steps, the dataset has been transformed into a clean and structured format:
- Missing values are handled
- Categorical data is converted into numerical form
- Features are scaled to a consistent range
This ensures that the model receives high-quality input, which directly impacts its learning and performance.
Data preprocessing is not just about applying steps; it’s about making informed decisions at each stage. Handling missing values, encoding categories, and scaling features are all done to remove obstacles that prevent models from learning effectively.
When done correctly, these steps make the difference between a model that struggles with messy data and one that delivers accurate, reliable results in real-world applications.
Best Tools & Libraries for Data Processing in ML
The tools you choose for data processing in machine learning depend on multiple factors, how large your dataset is, how quickly you need results, where your data lives, and how experienced your team is. What matters is not just knowing the tools, but understanding where each one fits and when it starts to break.
Pandas
Pandas are the foundation for tabular data. It remains the starting point for almost every machine learning workflow involving structured data.
Its DataFrame abstraction, often compared to a programmable Excel table, makes it easy to load data from formats like CSV, Excel, JSON, SQL, or Parquet and immediately begin exploring and transforming it.
In practice, Pandas handles everything from cleaning missing values using functions like fillna, dropna, or interpolation, to filtering rows, selecting and reshaping columns, and performing aggregations through groupby operations.
It also supports merging and joining datasets and includes strong support for time series transformations such as resampling and date parsing. However, its limitation becomes clear when datasets grow beyond available memory.
Once you cross roughly 4 to 8 GB on a typical development machine, performance degrades sharply, or the process fails, making it necessary to transition to tools designed for larger-scale processing.
NumPy
NumPy sits underneath nearly every data science and machine learning library, providing the numerical backbone for efficient computation. While it is rarely used in isolation for full data pipelines, it becomes essential when applying mathematical transformations to data.
Its strength lies in vectorised operations, which allow computations to run significantly faster than standard Python loops, along with support for matrix algebra, statistical transformations, and multi-dimensional arrays.
This makes it particularly useful for operations like normalising skewed features using logarithmic or power transformations, generating random samples for experiments, or handling structured data such as images, embeddings, or time series windows.
In most real-world workflows, Pandas is used for data loading and manipulation, and NumPy comes into play when those DataFrames need to be converted into arrays for efficient numerical computation or model input.
Scikit-learn
Scikit-learn defines the standard for how preprocessing should be done correctly in machine learning pipelines. Its key strength is not just the transformations themselves, but the discipline it enforces through its fit and transform paradigm.
In practice, this means transformations such as scaling, encoding, or imputation are learned only from the training data and then consistently applied to validation and production data, preventing data leakage.
This distinction is subtle but critical, as improper preprocessing is one of the most common causes of overly optimistic model performance during development.
Because of this, Scikit-learn pipelines are widely used not only for classical machine learning models but also as a reliable preprocessing layer even when the final model is built in another framework.
Apache Spark & PySpark
When data grows beyond what a single machine can handle, Apache Spark becomes the industry standard for distributed processing. PySpark, its Python interface, allows data scientists to work with Spark without needing to switch to Scala or Java.
These data platforms operate by partitioning datasets across multiple machines in a cluster and processing them in parallel, which makes it capable of handling extremely large datasets efficiently.
It integrates effortlessly with cloud storage systems like S3, Google Cloud Storage, and Azure Blob, and supports both batch and streaming workloads within the same framework. Its built-in MLlib library also enables distributed preprocessing and model training.
In practical terms, Pandas works best when data fits comfortably in memory and speed of development is the priority.
As datasets move into tens or hundreds of gigabytes, tools like Dask or Polars may act as an intermediate step, while Spark becomes essential once you reach terabyte-scale data or need a production-grade, cloud-native pipeline.
The trade-off is complexity, as Spark introduces infrastructure overhead and requires more effort to maintain compared to single-machine tools.
TensorFlow Data (tf.data)
In deep learning workflows, traditional preprocessing approaches often become a bottleneck because models train on GPUs while data preparation happens on CPUs. If the data pipeline cannot keep up, expensive GPU resources sit idle waiting for the next batch.
TensorFlow’s tf.data API addresses this by building highly efficient, parallelised data pipelines that integrate directly with the training process. It enables preprocessing to run across multiple CPU cores while simultaneously feeding data to the GPU, ensuring continuous utilisation.
Techniques like parallel mapping allow transformations to run concurrently, prefetching prepares the next batch while the current one is being processed, and caching avoids redundant computation across training epochs.
For PyTorch users, similar behaviour is achieved through custom Dataset classes combined with DataLoader and multiple worker processes, often paired with transformation ML libraries for data augmentation.
AutoML Preprocessing Tools
One of the most significant changes in the data processing landscape between 2023 and 2026 is the rise of AutoML platforms that automate significant portions of the preprocessing pipeline. Rather than hand-crafting imputation strategies, encoding choices, and scaling methods, these tools use search algorithms or LLMs to automatically select and optimise preprocessing steps.
Google Vertex AI AutoML
Vertex AI's preprocessing pipeline automatically handles feature engineering, encoding, scaling, and missing value imputation for tabular datasets. You provide a CSV or BigQuery table; the platform analyses your data, determines appropriate transformations per column, and outputs a trained model with its preprocessing embedded.
AWS SageMaker Data Wrangler
SageMaker Data Wrangler provides a visual interface for building preprocessing pipelines. It generates the underlying PySpark or Pandas code, which you can then export and customise. In 2026, it includes AI-suggested transformations based on your data profile and target variable.
Auto-sklearn and FLAML
For Python users who want AutoML without a cloud platform, Auto-sklearn and Microsoft's FLAML perform automated preprocessing as part of a broader AutoML search; they try different combinations of imputation, encoding, and scaling strategies alongside different model architectures to find the best end-to-end pipeline.
# AutoML with FLAML — automated preprocessing + model selection
from flaml import AutoML
automl = AutoML()
automl.fit(
X_train=X_train,
y_train=y_train,
task="classification",
time_budget=300, # search for 5 minutes
metric="roc_auc",
log_file_name="automl_log.json"
)
print(f"Best pipeline: {automl.best_estimator}")
print(f"Best config: {automl.best_config}")
predictions = automl.predict(X_test)AutoML preprocessing tools are powerful for prototyping and baseline-setting, but they are not a substitute for understanding what transformations are being applied and why.
In high-stakes domains (healthcare, finance, legal), you need to be able to explain every preprocessing step to auditors and stakeholders. Use AutoML to accelerate exploration, but understand and validate what it chooses before deploying to production.
Applications of Data Processing Across Industries in ML
Data processing is not just a technical step; it is what makes machine learning usable in real-world industries. Across industries, better data processing has led to measurable improvements in efficiency, accuracy, and business outcomes.
Healthcare
In healthcare, data processing enables machine learning systems to work with complex and unstructured medical data such as electronic health records, medical images, and clinical notes.
By cleaning and standardizing this data, models can identify patterns for early disease detection, personalized treatment, and faster diagnosis, significantly improving patient outcomes.
This becomes more impactful in advanced NLP use cases, where unstructured clinical text is transformed into meaningful, actionable insights. It also plays a critical role in reducing administrative burden and improving operational efficiency.
For example, processed clinical data allows AI systems to automate documentation, assist in diagnostics, and support decision-making, helping healthcare professionals focus more on patient care.
The impact is already visible at scale in 2026, with over 40 million people using AI daily for healthcare related queries, showing how processed medical data is driving real-world adoption and changing how patients interact with healthcare systems.
Finance
In the finance industry, data processing is essential for handling massive volumes of transactional and behavioral data in real time.
Clean and structured data allows machine learning models to detect fraud, assess credit risk, and generate personalized financial insights with high accuracy.
It also enables institutions to move from rule-based systems to predictive models, improving decision-making and reducing financial risks. For example, banks use processed data to identify unusual transaction patterns, preventing fraud before it occurs.
The impact is significant; machine learning adoption in banking is driving up to 20% reduction in customer churn and improved product sales, showing how data-driven insights are directly influencing revenue and customer retention.
E-commerce
In e-commerce, data processing powers recommendation engines, customer segmentation, and demand forecasting. By organizing and analyzing user behavior data, machine learning models can deliver personalized product recommendations, improving user experience and increasing conversions.
It also helps businesses optimize pricing, inventory, and marketing strategies by transforming raw customer interaction data into actionable insights. This allows companies to respond quickly to changing consumer behavior and market trends.
NLP & Computer Vision
In domains like Natural Language Processing (NLP) and Computer Vision, data processing is critical because the data is often unstructured: text, images, audio, or video. Preprocessing helps convert this raw data into structured formats that models can understand, such as tokenized text or labeled image datasets.
For NLP, processed data enables applications like chatbots, sentiment analysis, and document summarization by standardizing language and removing inconsistencies.
In computer vision, preprocessing techniques like image normalization and augmentation improve model accuracy in tasks such as object detection and facial recognition.
Across industries, the real value of machine learning comes from how well data is processed before it reaches the model. Whether it’s improving patient care, detecting fraud, personalizing shopping experiences, or understanding language and images, high-quality data processing is what turns raw data into real-world impact.
Best Practices for Effective Data Preprocessing in ML
Data preprocessing is not just about applying standard steps; it’s about doing them in the right way to avoid errors that can silently impact your model. Following a few practical best practices can help ensure your data remains reliable, your model performs well, and your results are trustworthy in real-world scenarios.
Always Split Before Scaling
One of the most common mistakes is applying preprocessing steps like scaling or encoding before splitting the dataset. This can cause the model to indirectly learn from the test data, leading to overly optimistic results.
In practice, always split your data into training and testing sets first. Then apply transformations only to the training data and use the same parameters on the test set. This ensures that your model evaluation reflects real-world performance and avoids hidden bias.
Avoid Data Leakage
Data leakage occurs when information that should not be available during training influences the model. This happens mostly through improper preprocessing, feature selection, or using future data unintentionally. To prevent this, first review your features and preprocessing steps.
Ensure that no target-related information is included in the input data, and that all transformations are applied within a controlled pipeline, just as structured workflows are enforced in modern CI/CD pipelines. Keeping a strict separation between training and testing workflows is critical for building reliable models.
Automate Pipelines
Manual preprocessing can become inconsistent and error-prone, especially as datasets grow larger or workflows become more complex. Automating these steps ensures that the same transformations are applied consistently, making results more reliable and easier to reproduce.
Using tools like Scikit-learn pipelines, you can combine steps such as imputation, encoding, and scaling into a single workflow. This not only reduces manual effort but also ensures that preprocessing is applied consistently across training and testing, making it easier to manage and deploy models in production environments.
Validate Data Quality
Even after preprocessing, it’s important to continuously validate data quality. Issues like unexpected values, format inconsistencies, or data drift can still affect model performance over time.
In practice, implement validation checks such as summary statistics, schema validation, and anomaly detection. Regularly monitoring your data ensures that your model continues to perform reliably and adapts to changes in real-world data.
Effective data preprocessing is as much about discipline as it is about technique. By following these practices, you create a strong foundation for building ML models that are accurate, scalable, and dependable.
How Code B Structures ML Systems for Production Use
Most organisations discover the same problem when moving from ML experiments to deployed systems; the model works in the notebook, but fails in production. The culprit, almost always, is not the model; it's the data pipeline underneath it.
Training a model that performs well on a test set is straightforward. Building a preprocessing pipeline that is reproducible, scalable, and continues to perform correctly six months after deployment is the engineering problem most teams underestimate.
At Code-B, we build the data infrastructure that makes ML reliable in production. This means starting with a proper data audit before writing a line of preprocessing code, profiling every feature for distribution, missing rate, leakage risk, and privacy sensitivity.
It means designing preprocessing pipelines that are version-controlled, unit-tested, and built to handle the edge cases that notebooks never encounter: schema changes, upstream data outages, and input distributions that drift over time.
We work across the full data processing stack, Pandas, PySpark, Scikit-learn Pipelines, Feast, dbt, and Apache Airflow, selecting the right tool for your scale rather than applying the same architecture to every project.
We work with product and engineering teams at scale-ups across fintech, healthtech, logistics, and SaaS, helping them move from working prototypes to systems that perform consistently and can be maintained and improved over time.

Final Thoughts
Data processing in ML is not just a preparatory step; it is the foundation that determines how well a model performs in actual scenarios. From understanding the complete data pipeline to applying preprocessing techniques, handling data issues, etc., each stage plays a critical role in shaping reliable outcomes. When done correctly, it ensures that models learn from accurate, relevant, and well-structured data rather than noise or inconsistencies. As machine learning continues to evolve across industries, the ability to process and refine data effectively remains one of the most valuable skills, directly impacting model accuracy, efficiency, and long-term success.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us