



Top 10 Deep Learning Frameworks in 2026


What are deep learning frameworks?
Deep learning is a branch of machine learning that enables computers to learn patterns directly from large datasets using artificial neural networks. It powers many modern AI applications such as image recognition, speech processing, recommendation systems, and autonomous driving.
Unlike traditional machine learning, which often relies on manually engineered features, deep learning models automatically learn useful representations from raw data. This capability makes them particularly effective for complex tasks like natural language processing and computer vision.
Deep learning has developed rapidly in the past decade due to increased computing power, large datasets, and optimizations in neural network designs.
Why Deep Learning Is Transforming AI
Artificial intelligence has rapidly moved from research labs into real-world products, and deep learning sits at the center of this transformation. Applications such as medical imaging, speech recognition, recommendation engines, and autonomous driving systems all rely on deep neural networks to process large volumes of complex data.
According to Stanford Institute AI Index Report, deep learning has emerged as one of the most important sources of significant progress in artificial intelligence, and it has been applied to create breakthroughs in such areas as computer vision, natural language processing, and generative AI.
Machine Learning vs. Deep Learning
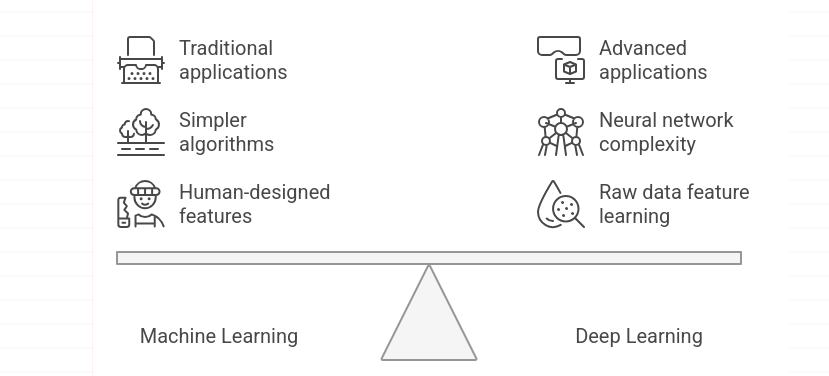
Machine learning and deep learning are closely related but differ in how models learn from data.
Machine learning and deep learning are closely interconnected but differ in the way models learn by data. The classic machine learning (ML) algorithms may rely on features that are not automatically created.
Deep learning (DL), however, uses multi-layered artificial neural networks that automatically learn patterns directly from raw data. Instead of relying heavily on manual feature engineering, these models discover useful representations during the training process itself.
This is what allows deep learning to be especially useful in processing unstructured data like images, audio, text, and allows such technologies as speech recognition, language translation, image analysis, and generative AI systems.
Why Deep Learning Frameworks Matter
Training neural networks from scratch would be extremely complex without specialized tools. Deep learning frameworks simplify this process by providing ready-to-use libraries, optimized training algorithms, and support for hardware acceleration such as GPUs and TPUs.
These frameworks allow developers to:
- Design neural network architectures quickly using pre-built layers, activation functions, and optimizers
- Train models efficiently on large datasets with GPU acceleration and distributed computing
- Deploy AI models into real-world applications through APIs, cloud platforms, and production pipelines
Consequently, deep learning systems have become an indispensable resource of AI scholars, computer programmers, and data scientists constructing current intelligent systems.
Top 10 Deep Learning Frameworks
In todays day and age, deep learning frameworks continue to evolve, powering innovations across industries. Here are the top 10 frameworks that are leading the way in AI and machine learning development.
1. TensorFlow

Overview
TensorFlow is one of the most widely used deep learning frameworks for building and deploying machine learning models. Developed by Google, it provides a large ecosystem of libraries and tools that help developers create neural networks, train models on large datasets, and deploy AI applications across multiple environments.
The system facilitates development processes such as research experiments to enterprise machine learning systems. It has model training tools, experiment tracking tools, mobile deployment tools, and machine learning pipeline tools, which makes it suitable to organizations with production AI workloads.
TensorFlow Framework Overview
Developer: Google Brain Team Initial Release: 2015 Primary Languages: Python, C++ License: Apache License 2.0 Platforms: Linux, macOS, Windows, Cloud environments, Mobile devices
Core Capabilities of TensorFlow
Model training on specialized hardware, including GPUs and TPUs, which helps reduce training time for large neural networks.
Comprehensive development ecosystem, including TensorFlow Lite for mobile AI applications and TensorFlow Extended (TFX) for machine learning pipelines.
Experiment monitoring and visualization tools such as TensorBoard, which help developers track training metrics and debug model performance.
Flexible deployment environments, allowing trained models to run on cloud infrastructure, mobile applications, and edge devices.
Where TensorFlow Performs Best
TensorFlow is frequently used in environments that require large-scale machine learning workflows and production AI systems, including:
- Large organizations often rely on TensorFlow when machine learning systems must process massive datasets and operate within complex data pipelines. Its scalable architecture supports efficient model training and deployment across cloud environments and enterprise infrastructure.
- Computer vision applications such as image classification, object detection, and facial recognition are commonly built using TensorFlow. The framework provides optimized libraries and pre-trained models that speed up the development of production-ready visual AI systems.
- Recommendation systems on digital platforms analyze user behavior, browsing activity, and purchase patterns to deliver personalized suggestions. TensorFlow’s machine learning capabilities make it well suited for building models that improve user engagement and conversion rates.
- Training large neural networks often requires significant computational power and parallel processing. TensorFlow supports distributed training across multiple GPUs and specialized hardware like TPUs, helping reduce training time for complex machine learning models.
Advantages of Using TensorFlow
Extensive ecosystem of AI development tools, covering model training, deployment pipelines, monitoring tools, and mobile AI frameworks
Wide industry adoption, resulting in strong community support and extensive technical documentation
Deployment flexibility, allowing machine learning models to run on cloud infrastructure, mobile devices, browsers, and embedded systems
Active development and long-term support, backed by Google and a large open-source community
Limitations Developers Should Consider
Learning curve for new developers, especially when working with low-level APIs or custom model architectures
Model debugging can require additional tooling, particularly in distributed training environments
Framework complexity increases with large machine learning pipelines, which may introduce overhead for small projects
2. PyTorch

Overview
PyTorch is one of the most widely adopted deep learning frameworks for building and training neural networks. Developed by Meta’s AI Research team, it provides a Python-based interface that allows developers to create machine learning models with a clear and flexible workflow.
Researchers frequently choose PyTorch when experimenting with new neural network architectures or training transformer models used in natural language processing and computer vision. The framework allows developers to modify models during execution, which simplifies debugging and experimentation compared to many traditional machine learning libraries.
Its strong adoption in research and open-source AI projects has made PyTorch a major foundation for modern deep learning development.
PyTorch Framework Overview
Developer: Meta AI (Facebook AI Research) Initial Release: 2016 Primary Languages: Python, C++ License: BSD-style License Platforms: Linux, macOS, Windows
Core Capabilities of PyTorch
Supportive neural network development process that enables developers to change model structures during execution, it makes it easy to debug and experiment.
GPU acceleration through CUDA integration, enabling faster training of large neural networks used in deep learning research.
Extensive ecosystem of supporting libraries, including TorchVision for computer vision tasks and TorchText for natural language processing pipelines.
Distributed model training support, allowing large machine learning models to be trained across multiple GPUs and computing nodes.
Where PyTorch Performs Best
PyTorch is commonly used in projects that require rapid experimentation and advanced model development, including:
Research projects exploring new neural network architectures
Natural language processing systems built on transformer-based large language model architectures
Computer vision applications such as image classification and object detection
Reinforcement learning experiments and generative AI models
Advantages of Using PyTorch
Developer-friendly Python interface, which simplifies neural network experimentation and debugging
Wide acceptance in scholarly studies, and other new model implementations and open-source materials are frequently released.
Large ecosystem of pretrained models and libraries, particularly for computer vision and NLP applications
Growing production deployment tools, including TorchServe for serving machine learning models
Limitations Developers Should Consider
Deployment workflows historically matured later than some enterprise-oriented frameworks, although tooling has improved significantly in recent years
Training large models can require careful GPU memory management to prevent performance issues
Smaller enterprise tooling ecosystem compared to frameworks designed primarily for production systems
3. Keras

Overview
Keras is a high-level API used for building and training neural networks. It was originally developed by François Chollet and later integrated into TensorFlow as the official high-level interface for deep learning model development.
A large number of developers rely on Keras when it is necessary to quickly develop neural networks without the need to write extensive amounts of low-level code.
The framework offers easy abstractions of defining layers, training models, and performance evaluation and this is the reason why this framework is common among students, researchers, and developers who are studying deep learning concepts.
Keras has found extensive use in quick prototyping machine learning models and in teaching machine learning with neural networks.
Keras Framework Overview
Developer: François Chollet / Google Initial Release: 2015 Primary Language: Python License: MIT License Platforms: Linux, macOS, Windows, Cloud environments
Core Capabilities of Keras
High-level neural network API that allows developers to define layers, loss functions, and optimizers using concise Python code.
Integration with TensorFlow, allowing Keras models to access TensorFlow’s training infrastructure and hardware acceleration.
Built-in support for common neural network architectures, including convolutional networks, recurrent networks, and transformer-based models.
Pretrained model libraries that allow developers to fine-tune popular architectures for tasks such as image classification or text analysis.
Where Keras Performs Best
Keras is commonly used in projects where ease of development and quick model experimentation are important, including:
Educational environments and deep learning courses
Rapid prototyping of machine learning models
Computer vision experiments using pretrained architectures
Natural language processing models built on TensorFlow infrastructure
Advantages of Using Keras
Clean and readable API, which reduces the amount of code required to build neural networks
Tight integration with TensorFlow, allowing developers to move from prototyping to production workflows
Large number of tutorials and educational resources, which helps beginners understand deep learning concepts faster
Access to pretrained models, enabling faster experimentation and transfer learning
Limitations Developers Should Consider
Less control over low-level model operations compared to frameworks designed for research experimentation
Advanced customization may require switching to lower-level TensorFlow APIs
Performance optimization options are limited when working only within the high-level interface
4. JAX

Overview
JAX is a machine learning library developed by Google that focuses on high-performance numerical computing and deep learning research. It is designed for developers who need precise control over mathematical operations while building neural networks and machine learning models.
The framework builds in components such as automatic differentiation and fast computation on GPUs and TPUs, extending NumPy. This flexibility makes JAX especially suitable for research settings where developers test out new algorithms or write custom neural network architectures.
Many research teams use JAX for developing advanced machine learning models, scientific computing workloads, and large transformer-based AI systems.
JAX Framework Overview
Developer: Google Research Initial Release: 2018 Primary Language: Python License: Apache License 2.0 Platforms: Linux, macOS, Windows
Core Capabilities of JAX
Automatic differentiation tools that allow developers to compute gradients for complex mathematical functions used in deep learning models.
NumPy-compatible API, enabling developers to write machine learning code using familiar numerical computing syntax.
GPU and TPU acceleration, which improves performance when training neural networks and running heavy numerical computations.
Just-in-time compilation through XLA, allowing Python code to be optimized into efficient machine-level instructions for machine learning workloads.
Where JAX Performs Best
JAX is frequently used in environments that require advanced numerical computation and experimental machine learning research, including:
Deep learning research involving custom neural network architectures
Large transformer model development and training
Reinforcement learning research projects
Scientific computing tasks involving heavy mathematical computation
Advantages of Using JAX
Strong support for mathematical computing, which makes it useful for research-driven machine learning projects
Efficient execution on modern hardware, including GPUs and TPUs
Compatibility with NumPy-style programming, allowing developers to adopt the framework without learning a completely new syntax
Growing ecosystem of libraries, including tools for large language model development
Limitations Developers Should Consider
Steeper learning curve for developers unfamiliar with functional programming concepts
Smaller ecosystem compared to older deep learning frameworks such as TensorFlow or PyTorch
Production deployment tools are still evolving, which can require additional engineering effort
5. Hugging Face Transformers
.png)
Overview
Hugging Face Transformers is a widely used library for building and deploying transformer-based models used in natural language processing and generative AI. The framework provides ready-to-use implementations of modern architectures such as BERT, GPT, and T5, which are commonly used for tasks like text generation, question answering, and language translation.
When it comes to using pretrained models or building apps that utilize large language models, developers often turn towards Hugging Face Transformers. It contains thousands of models available to the public and works seamlessly with deep learning frameworks like PyTorch, TensorFlow, and JAX.
Its strong focus on NLP and generative AI development has made it a central tool for many modern AI applications.
Hugging Face Transformers Framework Overview
Developer: Hugging Face Initial Release: 2019 Primary Language: Python License: Apache License 2.0 Platforms: Linux, macOS, Windows
Core Capabilities of Hugging Face Transformers
Large collection of pretrained transformer models, including architectures designed for language understanding, text generation, and conversational AI.
Integration with major deep learning frameworks, allowing models to run on PyTorch, TensorFlow, or JAX depending on the development environment.
Model hub and dataset libraries, providing access to thousands of community-trained models and datasets for machine learning experimentation.
Tools for fine-tuning pretrained models, enabling developers to adapt large language models for specific tasks such as sentiment analysis or document classification.
Where Hugging Face Transformers Performs Best
Hugging Face Transformers is commonly used in projects involving natural language processing and generative AI systems, including:
Chatbots and conversational AI systems
Document classification and sentiment analysis models
Question answering and information retrieval systems
Text generation and large language model applications that rely on LLM embedding techniques
Advantages of Using Hugging Face Transformers
Extensive collection of pretrained models, which allows developers to build NLP applications without training models from scratch
Large open-source community, resulting in frequent model updates and new research implementations
Integration with popular deep learning frameworks, allowing developers to choose their preferred training environment
Model hub for sharing and discovering AI models, which simplifies collaboration and experimentation
Limitations Developers Should Consider
Heavy computational requirements for large transformer models, which can require high-memory GPUs for training
Model fine-tuning can require large datasets, depending on the complexity of the task
Less suitable for computer vision or general deep learning tasks outside NLP
6. PaddlePaddle

Overview
PaddlePaddle is an open-source deep learning framework developed by Baidu to support large-scale AI applications across research and enterprise environments. The framework provides tools for building neural networks, training machine learning models, and deploying AI systems in production infrastructure.
PaddlePaddle is used in many organizations for industrial AI workloads, including computer vision systems, speech recognition and recommendation engines. It contains development tools, pretrained models, and deployment libraries that allow developers to create AI applications for cloud platforms as well for edge devices.
PaddlePaddle is heavily used in China and is expanding its global developer ecosystem via open source contributions and enterprise AI platforms.
PaddlePaddle Framework Overview
Developer: Baidu Initial Release: 2016 Primary Language: Python, C++ License: Apache License 2.0 Platforms: Linux, macOS, Windows
Core Capabilities of PaddlePaddle
Comprehensive deep learning toolkit that supports neural network training, model evaluation, and deployment across AI development workflows.
Distributed training infrastructure that allows machine learning models to be trained across multiple GPUs or computing nodes.
Industry-focused model libraries, including PaddleDetection and PaddleNLP, which provide implementations for common AI tasks.
Deployment tools for production environments, enabling trained models to run in cloud services, edge devices, and enterprise systems.
Where PaddlePaddle Performs Best
PaddlePaddle is commonly used in environments that require large-scale AI deployment and enterprise machine learning systems, including:
Industrial computer vision systems used in manufacturing and logistics
Recommendation engines used in large online platforms
Speech recognition and language understanding systems
Enterprise AI platforms running machine learning infrastructure
Advantages of Using PaddlePaddle
Strong focus on enterprise AI development, providing tools designed for industrial machine learning applications
Extensive model libraries for computer vision and NLP, which help accelerate development of common AI workloads
Active development backed by Baidu, resulting in continued improvements to training tools and deployment frameworks
Growing ecosystem of AI development tools, including support for large language models and multimodal AI systems
Limitations Developers Should Consider
Smaller global developer community compared to PyTorch or TensorFlow
Documentation and tutorials are more limited outside Chinese-language resources
Fewer third-party libraries and integrations available in the global AI ecosystem
7. Apache MXNet

Overview
Apache MXNet is an open-source deep learning framework designed for training and deploying neural networks in both research and production environments. It was originally developed by researchers at the University of Washington and later adopted by the Apache Software Foundation as an open-source project.
The framework has received recognition due to its proficiency in training machine learning models simultaneously using multiple GPUs distributed over numerous locations. Furthermore, it can be programmed in many different ways (e.g., Python, Scala, R) and therefore can be used by different teams who use different types of build tools.
Furthermore, Apache MXNet is being used on cloud-based Artificial Intelligence platforms and within other Machine Learning systems that need to efficiently train large amounts of data.
Apache MXNet Framework Overview
Developer: Apache Software Foundation Initial Release: 2015 Primary Language: Python, C++, Scala, R License: Apache License 2.0 Platforms: Linux, macOS, Windows
Core Capabilities of Apache MXNet
Support for multiple programming languages, allowing developers to build machine learning models using Python, Scala, Julia, or R.
Distributed training across multiple GPUs and machines, enabling training of large neural networks on large datasets.
Flexible model development through the Gluon API, which simplifies neural network creation while still allowing lower-level control when required.
Integration with cloud environments, enabling machine learning workflows to run in large cloud infrastructure systems.
Where Apache MXNet Performs Best
Apache MXNet is commonly used in environments that require distributed training and cloud-based machine learning workflows, including:
Large machine learning pipelines running on modern ML data engineering platforms
Computer vision systems used for image classification and detection
Recommendation systems built on large user datasets
Machine learning workloads that require multi-language development environments
Advantages of Using Apache MXNet
Multi-language support, which allows teams to integrate machine learning into different development stacks
Efficient training for large datasets, particularly in distributed computing environments
Flexible development APIs, giving developers the option to work with high-level or low-level interfaces
Open-source development model, supported by the Apache community
Limitations Developers Should Consider
Smaller community adoption compared to PyTorch and TensorFlow
Fewer recent research implementations available in the ecosystem
Documentation resources are less extensive than those of larger frameworks
8. Caffe

Overview
Caffe is an open-source deep learning framework developed by the Berkeley Vision and Learning Center (BVLC). It was created to support fast development and deployment of neural networks, particularly for computer vision applications.
The framework became popular in early deep learning research because of its performance in image classification and object detection tasks. Many research projects and industrial AI systems adopted Caffe for building convolutional neural networks used in visual recognition.
Although newer frameworks now dominate the deep learning ecosystem, Caffe remains relevant in projects focused on computer vision and model inference.
Caffe Framework Overview
Developer: Berkeley Vision and Learning Center (BVLC) Initial Release: 2013 Primary Language: C++, Python License: BSD License Platforms: Linux, macOS, Windows
Core Capabilities of Caffe
Efficient implementation of convolutional neural networks, designed for computer vision workloads such as image classification and object detection.
Model configuration through structured files, allowing developers to define neural network architectures without writing large amounts of code.
GPU acceleration support, enabling faster training and inference for image processing models.
Pretrained model availability, allowing developers to reuse well-known architectures such as AlexNet and VGG.
Where Caffe Performs Best
Caffe is commonly used in environments focused on computer vision model development and inference workflows, including:
Image classification systems for visual recognition tasks
Object detection models used in robotics or industrial vision systems
Research projects exploring convolutional neural networks
Deployment of trained vision models in production environments
Advantages of Using Caffe
Strong performance in computer vision tasks, particularly convolutional neural networks
Efficient inference for trained models, which makes it useful for deployment scenarios
Simple model configuration system, allowing developers to define neural networks through configuration files
Well-known pretrained models available for transfer learning
Limitations Developers Should Consider
Less flexible model development compared to modern deep learning frameworks
Smaller ecosystem of tools and libraries for current AI research
Limited support for newer neural network architectures used in modern AI systems
9. Deeplearning4j (DL4J)

Overview
Deeplearning4j (DL4J) is an open-source deep learning framework designed for the Java Virtual Machine (JVM). It enables developers to build, train, and deploy neural networks within Java and Scala environments, which makes it particularly useful for organizations running large enterprise systems built on JVM technologies.
Many deep learning solutions use only Python as their programming language, but DL4J allows Java developers due to its Java-based nature to use common enterprise data applications such as Hadoop, Spark, and others to extend or augment the capabilities of those applications by integrating machine learning into the enterprise environment.
DL4J is often leveraged as part of enterprise-level AI initiatives where machine learning applications need to connect to enterprise Java systems.
Deeplearning4j Framework Overview
Developer: Skymind Initial Release: 2014 Primary Language: Java, Scala License: Apache License 2.0 Platforms: Linux, macOS, Windows
Core Capabilities of Deeplearning4j
Native support for Java and Scala development, allowing neural networks to be built within JVM-based software environments.
Integration with big data platforms, including Apache Hadoop and Apache Spark, which enables machine learning workflows using large datasets.
Distributed training capabilities, allowing neural networks to be trained across clusters and large computing infrastructures.
Tools for model deployment in enterprise systems, enabling integration with business applications and data pipelines.
Where Deeplearning4j Performs Best
DL4J is commonly used in environments that rely on Java-based infrastructure and enterprise data platforms, including:
Enterprise AI systems integrated with Java applications
Machine learning pipelines connected to big data platforms that support ML data processing
Financial systems that use neural networks for fraud detection or risk analysis
Recommendation systems running inside large enterprise software platforms
Advantages of Using Deeplearning4j
Strong compatibility with Java enterprise environments, allowing deep learning models to integrate with existing software systems
Integration with big data processing frameworks, which supports machine learning workflows using large datasets
Cluster-based training support, enabling neural networks to be trained on distributed infrastructure
Enterprise-focused development tools, designed for organizations running large software systems
Limitations Developers Should Consider
Smaller developer community compared to Python-based deep learning frameworks
Fewer open-source implementations of modern AI architectures
Less adoption in academic research environments
10. MindSpore
.png)
Overview
MindSpore is an open-source deep learning framework developed by Huawei for building and training neural networks across cloud infrastructure, edge devices, and AI hardware accelerators. The framework focuses on improving the efficiency of model training and simplifying deployment across different computing environments.
MindSpore was designed to support large machine learning workloads that run on specialized AI hardware. It includes tools for model development, distributed training, and deployment pipelines that allow AI systems to run across cloud platforms and embedded devices.
The framework is commonly used in enterprise AI environments and research projects that require efficient training of deep learning models on dedicated AI infrastructure.
MindSpore Framework Overview
Developer: Huawei Initial Release: 2019 Primary Language: Python, C++ License: Apache License 2.0 Platforms: Linux, Cloud environments, Edge devices
Core Capabilities of MindSpore
Training optimization for AI hardware accelerators, which improves efficiency when running deep learning workloads on specialized chips.
Distributed training support, allowing neural networks to be trained across multiple devices and computing clusters.
Unified development pipeline, enabling developers to build models and deploy them across cloud servers, edge devices, and embedded systems.
Graph-based execution engine, designed to improve the efficiency of large neural network training workloads.
Where MindSpore Performs Best
MindSpore is commonly used in environments that require large-scale machine learning infrastructure and hardware-accelerated AI systems, including:
Enterprise AI platforms running on dedicated AI hardware
Distributed deep learning model training across large computing clusters
Edge AI systems used in mobile devices or embedded systems
Research projects focused on large neural network models
Advantages of Using MindSpore
Optimized training workflows for AI hardware accelerators
Distributed training architecture designed for large machine learning workloads
Development tools for deploying models across cloud and edge environments
Active development supported by Huawei’s AI research initiatives
Limitations Developers Should Consider
- Smaller global developer community compared to major deep learning frameworks
- Fewer third-party libraries and pretrained models available in the ecosystem
- Documentation and tutorials are still expanding
How to Choose the Right Deep Learning Framework
The choice of the appropriate deep learning framework is conditional upon a number of technical and practical considerations. Individuals who study neural networks as students, scientists who creatively test new models and developers who create production AI systems tend to place more emphasis on other factors when evaluating frameworks. A model that suits well in academic research may not be the most suitable one in the deployment of an enterprise and a tool that suits quick prototyping may fail to accommodate complex infrastructural needs. The following factors can be used to understand and decrease the number of frameworks that can be found and choose which one fits your project objectives.
Ease of Use
The speed at which developers can build and test a neural network is a commonly used aspect of frameworks compared by developers. A well-structured documentation and API allow defining model layers and running training experiments and debugging the issues in the development process easier.
With simple syntax frameworks, the team can progress risk-free between concept to working prototype with little implementation challenges.
Key aspects to evaluate include:
- API simplicity, which determines how easily neural network architectures can be defined and trained
- Documentation quality, including official guides, tutorials, and code examples
- Learning curve, particularly for developers transitioning from traditional machine learning libraries
Frameworks such as Keras and PyTorch are often chosen for their readable syntax and approachable development workflow.
Ecosystem and Community
Ecosystem strength of a framework can also have a great impact on the rate of development. A big community also generally implies additional tutorials, open-source software, and reusable models.
Important ecosystem elements include:
- Libraries and extensions that support tasks such as data processing, visualization, and model evaluation
- Tutorials and learning resources created by the community and framework maintainers
- Pretrained models that can accelerate development through transfer learning
- Community support channels, including developer forums and open-source repositories
Frameworks with active communities often evolve faster and provide more solutions when developers encounter challenges.
Performance and Hardware Support
Deep learning models require significant computational power, especially when training large neural networks. Frameworks that integrate well with modern hardware can significantly reduce training time.
Key performance considerations include:
- GPU acceleration, which allows models to train faster than CPU-only environments
- Distributed training support, enabling models to train across multiple GPUs or machines
- Compatibility with specialized hardware, such as TPUs and AI accelerators used in high-performance computing environments
Hardware-integrated frameworks can be improved to train large datasets or complex neural networks, and may be required to do so.
Deployment and Production Readiness
Training a model is only part of the development process. Many AI projects require reliable deployment pipelines that allow models to run in production systems.
Developers should evaluate frameworks based on:
- Model serving tools used to expose trained models through APIs
- Cloud compatibility with platforms such as AWS, Google Cloud, or Azure
- Edge deployment capabilities, which allow models to run on mobile devices or embedded systems
Frameworks with strong deployment tooling help organizations move from experimentation to production systems more efficiently.
Project Type
The model of AI system that you intend to develop must also affect your choice of framework. Certain frameworks would be useful in a research experiment, whereas others are configured to be deployed in an enterprise or to some niche workload like natural language processing.
Project requirements evaluation can be used at an early stage to reduce the number of frameworks that can fit within model architecture, infrastructure, and deployment environment.
Common examples include:
- Research and experimentation, where flexibility and rapid model iteration are important
- Enterprise AI systems, which require stable deployment pipelines and integration with existing infrastructure
- Edge AI applications, where models must run efficiently on mobile or embedded devices
- NLP and LLM development that often involves fine-tuning large language models
Choosing a framework that aligns with the project's technical requirements can reduce development time and simplify long-term maintenance.
Where Deep Learning Frameworks Are Heading
The concept of deep learning frameworks is under constant development with the upgrading of AI systems. Initial models concentrated largely on model training. Distributed computing, special hardware integration and production deployment pipelines are now supported by modern tools.
Industry research reflects this shift. According to McKinsey’s Global AI research, organizations are increasingly moving machine learning systems from experimental environments into production infrastructure. This transition places greater emphasis on frameworks that support efficient model training, infrastructure integration, and deployment workflows.
Frameworks Designed for Large Language Models
Large language models have become a major focus of modern AI development. Training these models requires frameworks capable of handling extremely large parameter counts and complex transformer architectures.
Framework ecosystems now include specialized tools for transformer-based models and pretrained model libraries. Developers often rely on frameworks such as PyTorch together with model libraries that simplify fine-tuning and inference workflows for language models.
Distributed Training Infrastructure
Training modern neural networks often requires large datasets and extensive computing resources. Many AI models are trained across clusters of GPUs using distributed computing
Deep learning frameworks increasingly provide built-in tools that allow developers to distribute training workloads across multiple devices or computing nodes. This approach makes it possible to train complex models within practical timeframes.
Support for distributed infrastructure is now a core requirement for frameworks used in large machine learning systems.
AI Running on Edge Devices
Machine learning models are increasingly deployed outside centralized cloud environments. Smartphones, industrial devices, autonomous systems, and IoT sensors now run machine learning models locally.
To support this shift, frameworks include tools that convert trained models into formats suitable for mobile processors and embedded hardware. These tools allow neural networks to run directly on devices without constant cloud communication.
Edge AI development continues to grow as industries integrate machine learning into connected devices.
Integration with AI Hardware
Training deep learning models relies heavily on specialized computing hardware. GPUs, TPUs, and neural processing units provide the computational power required for modern neural networks.
Framework developers are improving compatibility with these accelerators through optimized computation libraries and hardware-aware execution engines that integrate with modern infrastructure managed through cloud application development services.
Improved hardware integration allows developers to train larger models and process more data efficiently.
Integration with MLOps Workflows
Machine learning systems are systems that need continuous monitoring and updating once implemented. Models undergo retraining when new information is available and performance requirements vary.
This has necessitated the use of MLOps practices that employ software engineering processes to machine learning development. Contemporary deep learning systems have been combined with experiment tracking systems, automation of training pipelines, and model monitoring.
The integrations can assist a group to deal with the entire lifecycle of machine learning systems, such as development, deployment, and long-term maintenance.
Conclusion
Deep learning frameworks provide the foundation for modern AI development. They help developers design neural networks, train models efficiently, and deploy machine learning systems across cloud platforms, enterprise infrastructure, and edge devices.
The frameworks presented within the framework are among the most popular frameworks employed in the development of AI nowadays. Both are strong in their own way, based on the nature of project, development environment and deployment needs.
Considering aspects like ecosystem support, hardware compatibility and deployment will allow developers to select a framework that fits their objectives and technical constraints.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us