



Detailed Insights on Encoders in Machine Learning


Introduction to Encoders in Machine Learning
Encoders are essential components in the machine learning toolkit that transform raw data into formats that algorithms can understand and process effectively. At their core, encoders convert information from one representation to another, usually creating numerical representations that capture the underlying patterns and relationships in the data.
In the world of machine learning, computers only understand numbers. When we feed them categorical data like "red," "blue," and "green," or text like "Hello world," they can't directly process this information. Encoders bridge this gap by converting such non-numerical data into numerical formats that machine learning models can work with.
Encoders matter because they directly affect how well a model learns. A poorly chosen encoding method can obscure important patterns in your data, while the right encoding can highlight relationships that lead to better model performance. Think of encoders as translators that convert raw, messy real-world information into a language that machine learning algorithms can understand.
Types of Encoders in Machine Learning
When you're building machine learning models, you'll often come across categorical data — things like colors, brands, cities, or education levels. The problem is, machines don't naturally understand categories the way humans do. They work best with numbers. That’s why we need encoding methods: to convert these categories into a numerical format that our models can understand and learn from.
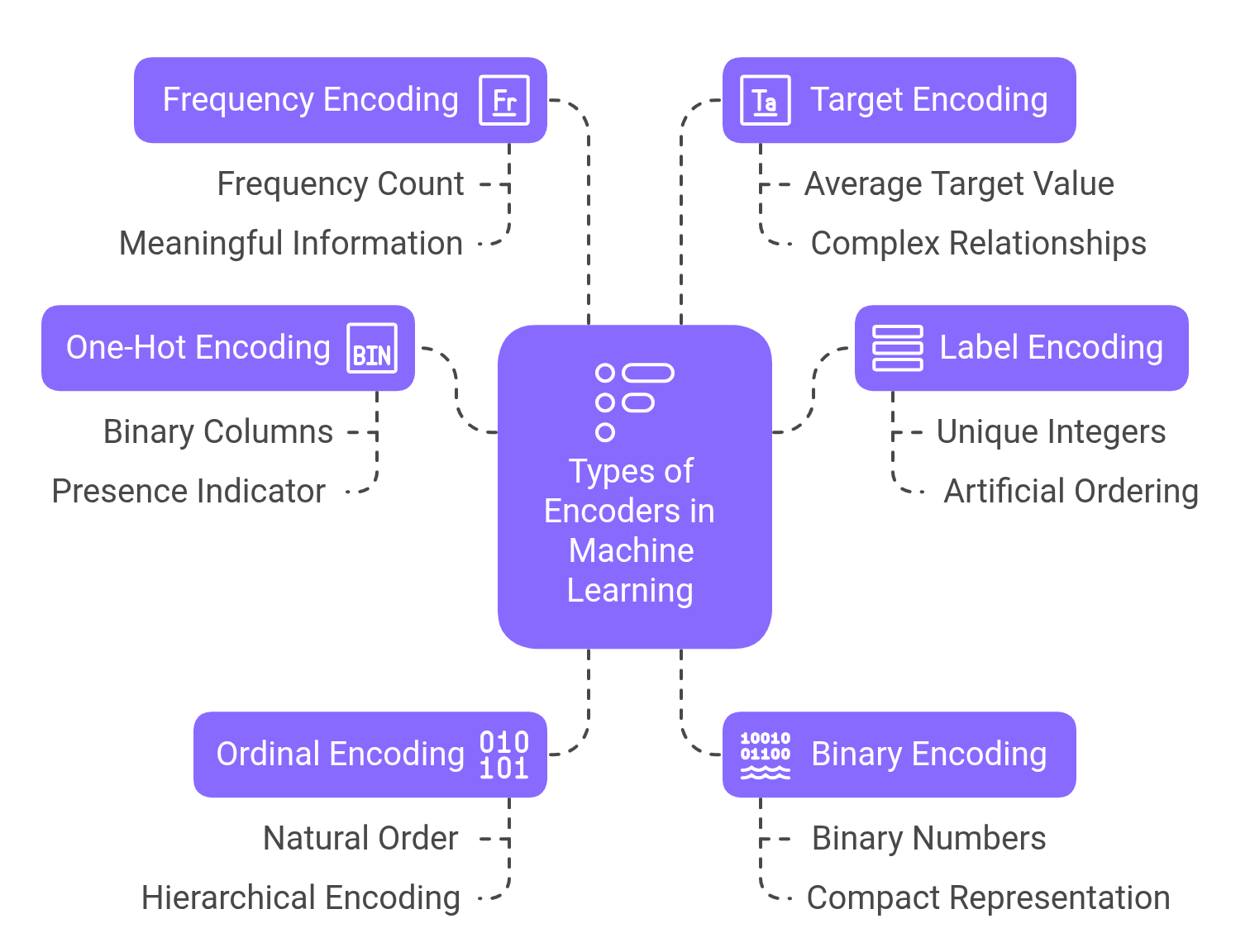
1. One-Hot Encoding
One-hot encoding creates binary columns for each category in your data. For example, if you have colors (red, blue, green), one-hot encoding creates three columns, with a 1 indicating the presence of that category and 0s elsewhere. For an item that is red, the encoding would be [1, 0, 0].
This approach is popular because it doesn't impose any artificial ordering between categories. Each category becomes equally distant from all others in the resulting vector space, which is perfect for truly nominal data like colors or product types.
2. Label Encoding
Label encoding assigns a unique integer to each category. Using our color example, red might become 0, blue becomes 1, and green becomes 2. While simple and memory-efficient, this method introduces an artificial ordering (suggesting green > blue > red), which can confuse algorithms that might interpret these numbers as having numerical significance.
Label encoding works well for tree-based models like decision trees and random forests, which don't assume relationships based on numerical values, but can be problematic for linear models and neural networks.
3. Ordinal Encoding
Similar to label encoding, ordinal encoding assigns integers to categories, but it's specifically designed for data with a natural order. For example, education levels (high school, bachelor's, master's, PhD) would be encoded as 0, 1, 2, and 3, reflecting their inherent hierarchy.
The key difference from label encoding is intentionality – we use ordinal encoding when we want to preserve and communicate the natural ordering to our model.
4. Binary Encoding
Binary encoding first assigns an integer to each category, then represents that integer as a binary number, with each bit becoming a separate column. This creates a more compact representation than one-hot encoding while still avoiding the false ordering problem of label encoding.
For example, with 8 categories, one-hot encoding would create 8 new columns, while binary encoding needs only 3 (since 2³ = 8). This efficiency becomes significant with high-cardinality categorical variables.
5. Frequency Encoding
Frequency encoding replaces each category with its frequency (count) or relative frequency (percentage) in the dataset. Common categories get higher values, while rare ones get lower values.
This method can be powerful because the frequency often carries meaningful information. For instance, in a dataset of website visits, encoding browser types by their frequency might reveal that users of less common browsers behave differently than those using popular ones.
6. Target Encoding
Target encoding (also called mean encoding) replaces categories with the average target value for that category. For example, in a loan default prediction model, each city might be replaced with the historical default rate for loans from that city.
This technique can efficiently capture complex relationships between categorical variables and the target but requires careful implementation to avoid data leakage and overfitting.
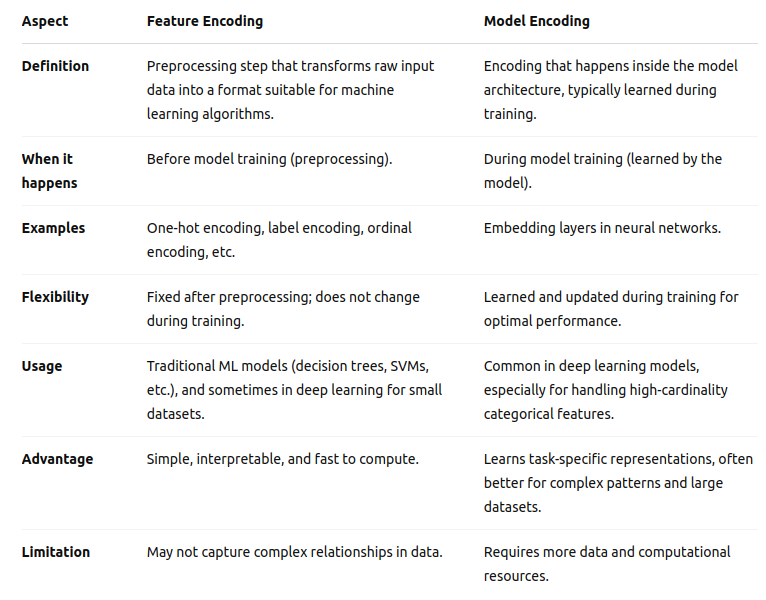
Feature Encoding vs. Model Encoding
Feature encoding transforms input data before it enters a model. This preprocessing step converts raw features into formats suitable for machine learning algorithms. The encoding methods discussed above (one-hot, label, etc.) fall into this category.
Model encoding, on the other hand, happens within the architecture of the model itself. For example, embedding layers in neural networks are a form of model encoding that learns optimal numerical representations of categorical variables during training. This approach allows the model to discover the most useful representations for the specific task it's trying to solve.
The key difference is that feature encoding is fixed before model training, while model encoding is learned during training. Modern deep learning often relies more heavily on model encoding, letting the network learn the best representations automatically.
Encoding for Different Data Types
.png)
Encoding Categorical Data
Categorical data encoding typically uses the methods covered earlier (one-hot, label, etc.). The best choice depends on the nature of your categories:
For nominal data with no inherent order, one-hot or binary encoding is usually best
For ordinal data with a clear ranking, ordinal encoding makes sense
For high-cardinality variables (with many unique values), target encoding or embedding techniques often work better
Encoding Numerical Data
While numerical data doesn't need conversion to numbers, it often needs transformation to work well in models:
Normalization (scaling to 0-1 range) or standardization (converting to zero mean and unit variance)
Binning (converting continuous values to discrete ranges)
Power transformations like log or Box-Cox to handle skewed distributions
These aren't encoders in the strict sense but serve a similar purpose of preparing data for optimal model performance.
Encoding Text Data
Text encoding converts natural language into numerical representations:
Bag-of-words models count word occurrences
TF-IDF (Term Frequency-Inverse Document Frequency) weights words by their importance
Word embeddings like Word2Vec map words to dense vectors that capture semantic relationships
Advanced methods like BERT encodings generate contextual representations that vary based on how a word is used in a sentence
Encoding Images
Image encoding transforms visual data into numerical formats:
Pixel values serve as the most basic encoding (grayscale or RGB channels)
Convolutional neural networks automatically learn hierarchical feature representations
Autoencoders compress images into lower-dimensional representations
Pre-trained models like ResNet or VGG can generate feature vectors that capture high-level visual concepts
Word Embeddings and Text Encoding
TF-IDF
TF-IDF weighs words based on how frequently they appear in a document and how unique they are across all documents. Common words like "the" or "and" get lower weights, while distinctive, informative words receive higher weights.
This encoding captures the importance of words in a document relative to a corpus, making it effective for tasks like document classification and information retrieval.
Word2Vec
Word2Vec creates dense vector representations of words by training a shallow neural network to predict either:
Words that appear near a target word (skip-gram model)
A target word based on its context (continuous bag-of-words model)
The resulting word embeddings capture semantic relationships, placing similar words close together in vector space. The famous example is that vector("king") - vector("man") + vector("woman") ≈ vector("queen").
GloVe
Global Vectors for Word Representation (GloVe) combines the advantages of two approaches:
Matrix factorization techniques that capture global statistical information
Local context window methods like Word2Vec that capture fine-grained semantic details
GloVe trains on global word-word co-occurrence statistics from a corpus, creating embeddings that perform well across many NLP tasks.
BERT Encoding
Bidirectional Encoder Representations from Transformers (BERT) represents a major advancement in text encoding. Unlike previous methods that generate a fixed vector for each word, BERT produces contextual encodings that change based on the surrounding words.
BERT pre-trains a deep transformer model on massive text corpora using masked language modeling and next sentence prediction tasks. The resulting encodings have revolutionized NLP, achieving state-of-the-art results on multiple benchmarks when they were introduced.
Autoencoders in Deep Learning
Concept of Autoencoders
Autoencoders are neural networks designed to copy their inputs to their outputs. They consist of two parts:
An encoder that compresses the input into a lower-dimensional representation (the "code")
A decoder that reconstructs the original input from this representation
Despite seeming trivial, autoencoders are forced to learn efficient representations by constraining the code to be smaller than the input or by adding regularization.
.png)
Types of Autoencoders
Vanilla Autoencoders use a simple architecture with fully connected layers to compress and reconstruct data.
Variational Autoencoders (VAEs) add a probabilistic twist by encoding inputs as distributions rather than fixed values. This encourages smooth interpolation in the latent space and enables generative capabilities.
Sparse Autoencoders add regularization that encourages the network to activate only a small subset of neurons for each input, creating more distributed and robust representations.
Denoising Autoencoders are trained to reconstruct clean inputs from corrupted versions, learning representations that capture the essential structure of the data while ignoring noise.
Applications of Autoencoders
Autoencoders excel at:
Dimensionality reduction for visualization and feature extraction
Data denoising and restoration
Anomaly detection by identifying inputs with high reconstruction error
Image generation (especially with VAEs and their descendants)
Recommender systems through collaborative filtering
Encoding for Neural Networks
One-hot vs. Embedding Layers
Neural networks often handle categorical inputs in one of two ways:
One-hot encoding followed by a dense layer
Embedding layers that learn compact representations
Embedding layers are generally preferred for categories with many values because:
They create more efficient representations with fewer parameters
They can learn meaningful relationships between categories
They avoid the extreme sparsity of one-hot encodings
The dimensionality of embeddings is typically much smaller than the number of categories but large enough to capture the complexity of the relationships (often starting with the square root of the cardinality as a rule of thumb).
Positional Encoding in Transformers
Transformer models like BERT and GPT need to know the position of each token in a sequence, but their self-attention mechanism doesn't inherently capture order.
Positional encoding solves this by adding position-dependent patterns to each token's embedding. The original transformer paper used sine and cosine functions of different frequencies, creating a unique fingerprint for each position.
This elegant solution allows transformers to process sequences in parallel while still maintaining awareness of token order, which is crucial for understanding language.
Applications of Encoders in ML & AI
1. Natural Language Processing (NLP)
In NLP, encoders convert text into numerical formats suitable for machine learning:
Machine translation systems encode source language text and decode it into target languages
Sentiment analysis models encode text to extract emotional tone
Question answering systems encode both questions and context passages to find relevant information
Text summarization tools encode documents to extract key information
The quality of these encodings directly impacts how well systems understand language nuances.
2. Computer Vision (Image Encoding)
Image encoding enables computers to "see" and understand visual information:
Object detection models encode images to locate and identify specific objects
Image classification systems encode visual information to categorize images
Style transfer techniques encode content and style separately
Image generation models encode visual concepts to create new images
Recent advances in vision transformers (ViT) apply transformer architectures from NLP to image encoding with impressive results.
3. Feature Engineering for ML Models
Effective encoding is central to feature engineering:
Converting raw data into informative features
Handling missing values through encoding techniques
Creating interaction features from multiple encoded variables
Reducing dimensionality while preserving information
Well-engineered features can make simple models perform better than complex models with poor feature encoding.
4. Compression and Data Representation
Encoders also serve practical purposes in data storage and transmission:
Compressing large datasets for efficient storage
Creating compact representations for faster model inference
Enabling privacy-preserving machine learning through encoded representations
Supporting efficient similarity search in large databases
Challenges in Encoding Techniques
1. Overfitting in Target Encoding
Target encoding can lead to overfitting when categories appear in both training and validation data. Solutions include:
Cross-validation schemes that ensure encoding is based only on out-of-fold data
Adding regularization by blending with the global mean
Using Bayesian smoothing that adjusts for sample size
Creating separate encodings for training and validation
2. Curse of Dimensionality in One-Hot Encoding
One-hot encoding creates very sparse, high-dimensional spaces that can lead to:
Increased computational complexity
More parameters to learn, requiring more training data
Risk of overfitting due to excessive model capacity
Reduced effectiveness of distance metrics in sparse spaces
Solutions include dimensionality reduction techniques, binary encoding, or embedding approaches.
3. Information Loss in Label Encoding
Label encoding can lose critical information or introduce misleading patterns:
Artificial ordering between unordered categories
Uneven distances between categories (all differences equal to 1)
Loss of the categorical nature of the data
Models may incorrectly learn from these artificial patterns, reducing performance on new data.
Best Practices for Encoding Data
.png)
1. Choosing the Right Encoding Method
Select encoding methods based on:
Data type and properties (categorical, ordinal, continuous)
The number of unique values (cardinality)
The chosen model type (tree-based, linear, neural network)
Available computational resources
The relationship between features and the target variable
Always validate your encoding choice through cross-validation to ensure it generalizes well.
2. Handling High-Cardinality Categorical Data
Categories with many unique values present special challenges:
Group infrequent categories into an "Other" category
Use clustering to group similar categories
Consider target encoding or embedding approaches
Apply dimensionality reduction after one-hot encoding
Use tree-based feature selection to identify important categories
The right approach depends on the specific dataset and problem.
3. Using Encoding Techniques Efficiently
Optimize your encoding pipeline by:
Applying encodings consistently between training and inference
Creating reusable encoding pipelines with tools like Scikit-learn's pipelines
Caching encoding results for large datasets
Testing different encoding strategies empirically
Combining multiple encoding techniques when appropriate
Usecases
1. One-Hot Encoding
Use Case: E-commerce product categories (e.g., Electronics, Clothing, Toys) In an e-commerce platform, products belong to various categories. These categories don’t have any order — "Clothing" is not greater or less than "Electronics". One-hot encoding works well here because it treats all categories equally by creating a separate column for each. When building recommendation systems or running product popularity analyses, this helps the algorithm clearly understand product types without assuming any ranking between them.
2. Label Encoding
Use Case: Player positions in sports analytics (Goalkeeper, Defender, Midfielder, Forward) Sports data often includes player positions, and label encoding can be a handy tool here. Each position is assigned a unique integer. Tree-based models like decision trees or random forests handle these numbers well because they don’t assume numerical relationships. This allows you to efficiently model player statistics, strategies, or team formations without worrying about false hierarchies.
3. Ordinal Encoding
Use Case: Customer feedback ratings (Very Unsatisfied → Very Satisfied) When collecting customer satisfaction surveys, responses often follow a natural order. Ordinal encoding helps by mapping responses like "Very Unsatisfied," "Unsatisfied," "Neutral," "Satisfied," "Very Satisfied" to integers (e.g., 0 to 4). This retains the natural progression of sentiment, allowing models to understand not just the category but also the direction and intensity of customer sentiment.
4. Binary Encoding
Use Case: ZIP codes in a delivery logistics model Delivery companies handle thousands of ZIP codes, making one-hot encoding too bulky. Binary encoding first converts each ZIP code into an integer, then to binary format, efficiently reducing the number of columns. For example, if there are 500 ZIP codes, binary encoding only needs about 9 columns (since 2⁹ = 512). This speeds up model training and makes the data manageable, especially for routing and delivery time prediction models.
5. Frequency Encoding
Use Case: Retail product sales frequency In a large supermarket chain, some products sell far more often than others. Frequency encoding replaces each product category with its sales frequency. This helps models detect patterns like: "Popular products have less likelihood of stockouts," or "Rare products correlate with high-margin specialty items." It's especially useful in inventory management and demand forecasting.
6. Target Encoding
Use Case: Real estate average house price by neighborhood When predicting house prices, the neighborhood is a crucial feature. With target encoding, each neighborhood is replaced by the average house price in that area. This helps capture the relationship between location and price effectively. However, it's important to use proper cross-validation to avoid leaking target information into the training data, which can cause overfitting.
Encoding in Popular ML Libraries
1. Encoding with Scikit-Learn
Scikit-learn provides several encoding tools:
OneHotEncoder for one-hot encoding
LabelEncoder for label encoding
OrdinalEncoder for ordinal encoding
ColumnTransformer for applying different encodings to different columns
The library also offers pipeline functionality to ensure consistent encoding between training and testing data.
2. TensorFlow/Keras Encoding Layers
TensorFlow and Keras provide specialized layers for encoding:
tf.keras.layers.Embedding for categorical variables
tf.keras.layers.TextVectorization for text data
tf.feature_column module for mixed data types in TensorFlow models
tf.one_hot for direct one-hot encoding
These integrate seamlessly with deep learning workflows.
3. PyTorch Encoding Techniques
PyTorch offers flexible encoding options:
torch.nn.Embedding for embedding layers
torch.nn.functional.one_hot for one-hot encoding
torchtext library for text processing
torch.nn.utils.rnn.pad_sequence for handling variable-length sequences
PyTorch's dynamic computation graph makes it easy to implement custom encoding schemes.
Conclusion
Encoders serve as the vital bridge between raw data and machine learning models. The choice of encoding methodology significantly impacts model performance, with different types of data requiring specialized approaches:
Categorical data benefits from one-hot, label, or target encoding depending on cardinality and data properties
Text data thrives with modern contextual embeddings like BERT
Images leverage convolutional architectures and autoencoder techniques
Numerical data requires appropriate scaling and transformation
The best encoding approach depends on your specific data, model architecture, and problem domain. There's rarely a one-size-fits-all solution, which makes understanding the strengths and weaknesses of different encoders essential for any machine learning practitioner.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us