



Guide To Distributed Backend Systems



What Are Distributed Systems?
Distributed systems are networks of computers or devices that work together to achieve a common goal. Unlike a single, centralized system, distributed systems involve multiple independent components that communicate and coordinate through messages. These systems share resources, data, and tasks across various locations, enabling collaboration and enhancing reliability. They allow for scalable and flexible architectures by breaking down complex tasks into smaller parts and distributing them across the network. Examples include cloud computing, peer-to-peer networks, and the internet itself, where multiple devices collaborate to deliver services or information to users seamlessly.
Fundamentals
Nodes in Distributed Systems:
- Individual devices within the system with computational power and storage capacity.
- Various forms include servers, computers, IoT devices, and sensors.
- Enable decentralized decision-making, processing tasks, and data storage.
Communication Models:
- Peer-to-Peer (P2P): Direct collaboration among nodes without a central server.
- Client-Server Paradigm: Centralized server managing client requests and resource distribution.
- Publish-Subscribe Mechanism: Publishers disseminate messages to interested subscribers.
Transparency in Distributed Systems:
- Access Transparency: Uniform access to resources regardless of their physical location.
- Location Transparency: Shielding users from resource physical addresses or network details.
- Failure Transparency: Maintaining functionality despite component failures for uninterrupted service availability.
Need Of Distributed Systems In Modern World
Scalability
- Growing Demands and User Bases: As user bases and demands for services expand, backend systems encounter increased traffic, data processing, and user interactions.
- Flexible and Seamless Scaling: Distributed systems offer the ability to scale horizontally, allowing the addition of more nodes or machines to handle rising workloads and data volumes smoothly.
- Adaptable Resource Allocation: They ensure efficient resource allocation, dynamically adjusting to accommodate varying demand patterns, ensuring optimal performance during peak usage times.
Fault Tolerance and Reliability
- Continuous and Uninterrupted Operation: Backend systems must operate without disruptions or downtime to maintain the continuity of services and meet user expectations.
- Resilience Against Failures: Distributed systems' decentralized nature mitigates risks of single points of failure by dispersing tasks and data, ensuring system reliability in the event of component failures or network issues.
- Ensuring System Availability: They maintain service availability, critical for industries like finance, healthcare, and e-commerce, where uninterrupted service delivery is crucial.
Performance and Speed
- Enhanced User Experience: Geographical distribution minimizes latency, resulting in faster response times, quicker data retrieval, and a smoother user experience.
- Optimized Data Processing: Distributed backend systems excel in optimizing data processing and transaction handling, contributing to improved application responsiveness and overall system performance.
- Supporting Real-time Applications: Their ability to process data rapidly is essential for real-time applications like gaming, financial transactions, and live streaming.
Flexibility and Adaptability
- Agility in Response to Changes: As business requirements evolve or technological advancements occur, distributed systems allow for swift adaptation, enabling businesses to incorporate new features or technologies seamlessly.
- Modularity and Integration: They support modular development, enabling easy integration with diverse services, APIs, or technologies, ensuring compatibility and ease of collaboration across different components or systems.
- Support for Dynamic Workloads: Distributed systems can dynamically adjust to varying workloads, accommodating changes in demand without compromising performance or stability.
Cost Efficiency
- Optimized Resource Utilization: Leveraging resources effectively, especially in cloud-based setups, distributed systems offer cost-effective solutions by scaling resources according to actual demand.
- Avoidance of Over-investment: They prevent unnecessary spending by optimizing resource usage, ensuring that businesses allocate resources based on fluctuating demands, thus avoiding over-investment in infrastructure or resources.
- Return on Investment (ROI): By balancing costs with performance, distributed systems offer a favorable ROI by delivering reliable, high-performing backend operations essential for modern applications and services.
Challenges Faced Due To Distributed Systems
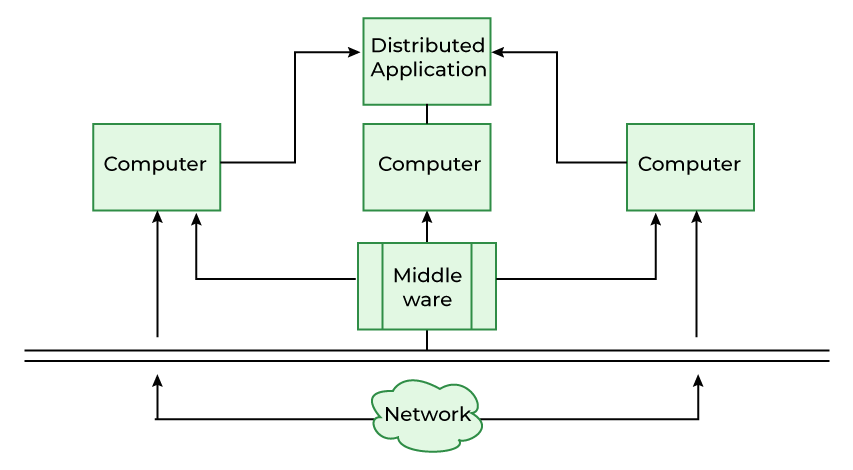
Consistency and Replication
- Data Consistency: Ensuring uniformity of data across distributed nodes presents challenges due to the need for synchronization. Maintaining consistency during updates or changes across multiple nodes in real-time without conflicts is crucial but complex.
- Conflict Resolution: Handling conflicting updates or modifications to the same data among distributed nodes requires robust conflict resolution mechanisms to maintain data integrity and prevent inconsistencies.
- Replication Strategies: Implementing efficient data replication strategies involves deciding how and when to replicate data across nodes while balancing consistency and performance trade-offs.
Concurrency and Coordination
- Resource Access Control: Managing concurrent access to shared resources among distributed nodes without conflicts or race conditions is challenging. Ensuring consistency while allowing multiple nodes to access data concurrently requires effective control mechanisms.
- Coordination Protocols: Implementing coordination protocols or distributed algorithms to synchronize actions among different nodes poses complexities. Ensuring coordinated actions without compromising system integrity demands sophisticated coordination mechanisms.
Security and Privacy
- Secure Communication: Ensuring secure communication channels among distributed nodes is critical. Implementing encryption, secure protocols, and authentication mechanisms across diverse nodes presents challenges.
- Data Protection: Safeguarding data privacy during transmission and storage across distributed environments requires robust encryption, access controls, and compliance with data protection regulations.
- Authorization and Access Control: Managing authorization and access control across distributed nodes while preventing unauthorized access or data breaches demands comprehensive security measures.
Network Partitioning
- Handling Network Failures: Dealing with network partitioning or communication failures between nodes without causing inconsistencies or disruptions poses significant challenges. Maintaining system consistency despite network splits requires careful design and fault-tolerant strategies.
- Resolving Split-Brain Scenarios: Addressing split-brain scenarios where nodes become isolated due to network partitions necessitates establishing reliable mechanisms to reconcile diverging states and maintain system coherence.
Development Complexity
- Architecture and Design: Designing distributed systems involves intricate architectural decisions considering fault tolerance, scalability, and consistency, adding complexity to development.
- Testing and Debugging: Ensuring system stability and functionality through testing and debugging in distributed environments is challenging due to diverse architectures and interactions among nodes.
- Ongoing Management: Maintaining and managing distributed systems requires specialized skills, ongoing monitoring, and management, contributing to increased complexity in system development and maintenance.
Different Architectures Of Distributed Systems
Distributed systems can adopt various architectures based on the specific requirements, scalability needs, and the nature of the application. Some prominent architectures include:
1. Client-Server Architecture:
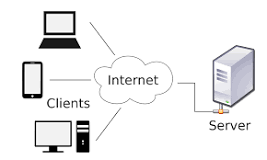
Explanation:
- Architecture Overview: In this model, clients request services or resources from centralized servers.
- Components: Clients are the end-user devices (e.g., computers, smartphones), and servers manage data, processing, and resources.
- Communication: Clients communicate with servers over a network, typically using request-response protocols.
- Key Characteristics: Centralized control and management with clients making requests and servers responding to those requests.
Pros:
- Centralized Control
- Security
- Scalability (servers can be scaled independently)
Cons:
2. Peer-to-Peer (P2P) Architecture:

Explanation:
- Architecture Overview: Peers (nodes/devices) communicate and share resources directly without relying on central servers.
- Communication: Peers act as both clients and servers, contributing resources like processing power, files, or data.
- Key Characteristics: Decentralization, no central point of control, and each peer participating in resource sharing.
Pros:
- Decentralization
- Scalability (additional nodes contribute resources)
- Redundancy in data storage
Cons:
3. Microservices Architecture:
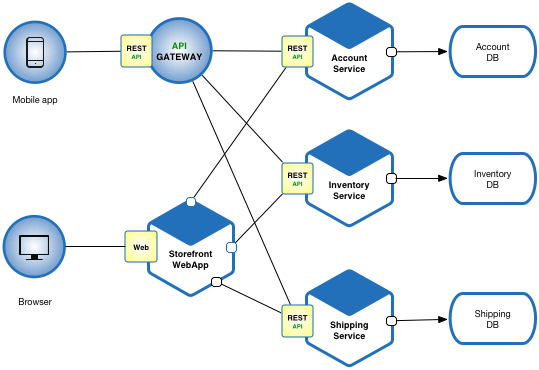
Explanation:
- Architecture Overview: Decomposes applications into small, independent services communicating through APIs.
- Components: Each service handles specific functionalities, operating as separate entities.
- Communication: Services communicate via well-defined APIs over a network.
- Key Characteristics: Service autonomy, scalability, and flexibility in technology choices.
Pros:
- Scalability and Agility (independent service scaling)
- Resilience (failure in one service doesn't impact the entire app)
- Technology Diversity (use different technologies for services)
Cons:
4. Service-Oriented Architecture (SOA):
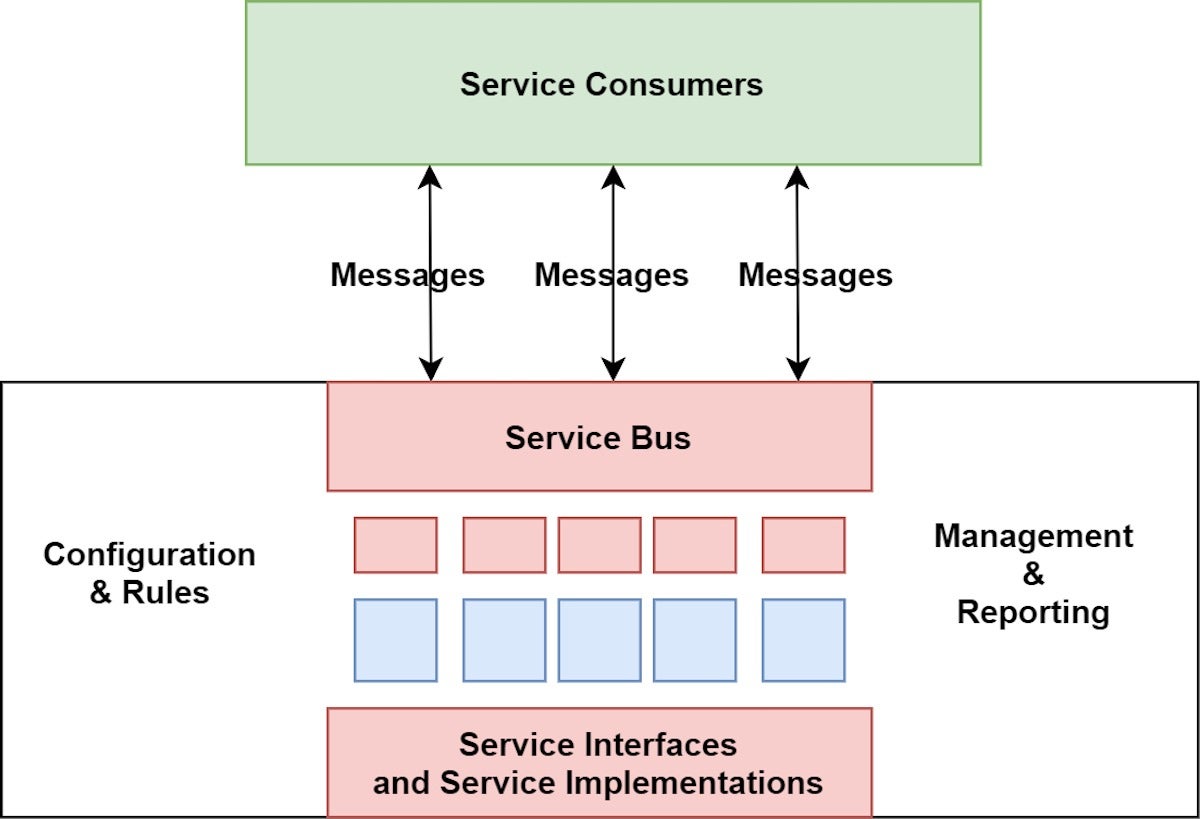
Explanation:
- Architecture Overview: Organizes functionalities into reusable services accessible over a network.
- Components: Services designed for specific tasks, communicating via standardized protocols.
- Communication: Emphasis on interoperability and reuse of services across applications.
- Key Characteristics: Service reusability, interoperability, and flexibility.
Pros:
- Reusability across applications
- Interoperability through standardized interfaces
- Flexibility to adapt to changing business requirements
Cons:
5. Event-Driven Architecture (EDA):
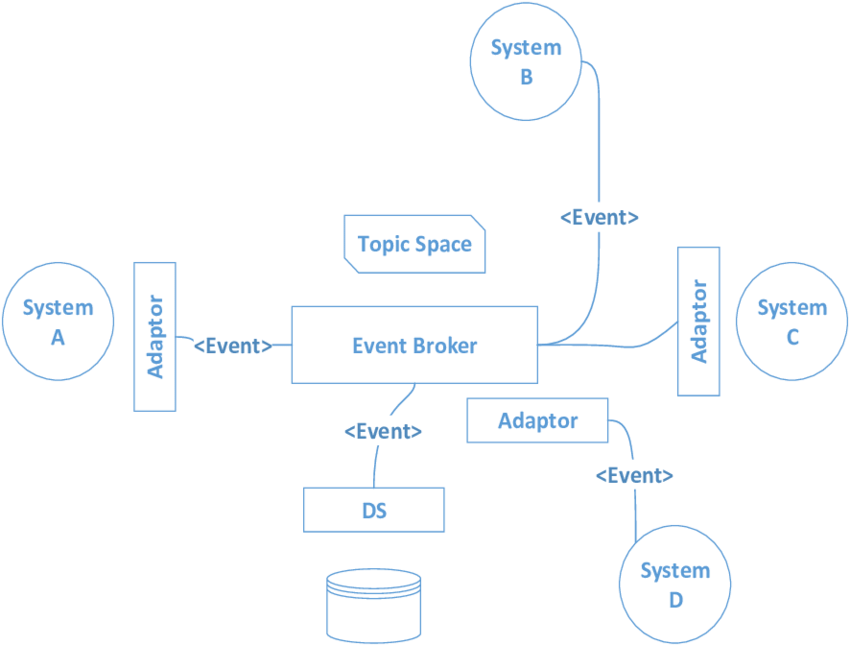
Explanation:
- Architecture Overview: Relies on events triggering actions or processes across distributed components.
- Components: Events emitted, detected, and processed asynchronously, enabling loosely coupled interactions.
- Communication: Asynchronous event flow and event-based interactions among components.
- Key Characteristics: Scalability, real-time processing, and flexibility in handling various event types.
Pros:
- Scalability through asynchronous and loosely coupled components
- Real-time processing and responsiveness to events
- Flexibility in handling diverse event types and workflows
Cons:
6. Blockchain and Decentralized Architectures:
Explanation:
- Architecture Overview: Utilizes decentralized ledgers for recording transactions across multiple nodes.
- Components: Transactions recorded in immutable and distributed blocks with cryptographic validation.
- Communication: Peer-to-peer communication and consensus mechanisms for transaction validation.
- Key Characteristics: Decentralization, immutability, and high-security standards.
Pros:
- Decentralization and trust through distributed ledgers
- Immutability, ensuring data integrity, and preventing tampering
- High-security standards through cryptographic mechanisms
Cons:
- Scalability challenges due to consensus mechanisms
- Resource-intensive consensus algorithms and data replication
- Regulatory and compliance concerns in certain industries
7. Hybrid Architectures:
Explanation:
- Architecture Overview: Combines multiple architectural patterns to address specific requirements.
- Components: Mixes the strengths of different architectures to create tailored solutions.
- Communication: Utilizes a combination of communication patterns from various architectures.
- Key Characteristics: Flexibility, optimized solutions catering to diverse needs.
Pros:
- Adaptability, leveraging strengths of multiple architectures
- Optimized solutions addressing specific needs and challenges
Cons:
- Increased complexity in managing diverse architectural patterns
- Maintenance challenges requiring expertise in hybrid setups
Each architecture comes with its own set of advantages and challenges, making them suitable for different scenarios based on specific requirements, scalability needs, fault tolerance, security considerations, and the nature of the application or system being developed.
Exploring Applications of Distributed Systems
Distributed systems have revolutionized modern computing by offering solutions to various challenges, particularly in databases and messaging systems. In this tutorial, we'll delve into popular distributed databases and messaging systems, spotlighting their architectures and how they tackle the significant hurdles inherent in distributed systems, such as partitioning and coordination.
MongoDB
MongoDB is an open-source, distributed database. It stores data as flexible documents containing field-value pairs, offering JSON-like structures. It allows the nesting of documents (embedded documents) and arrays for complex data modeling.
Data Distribution in MongoDB
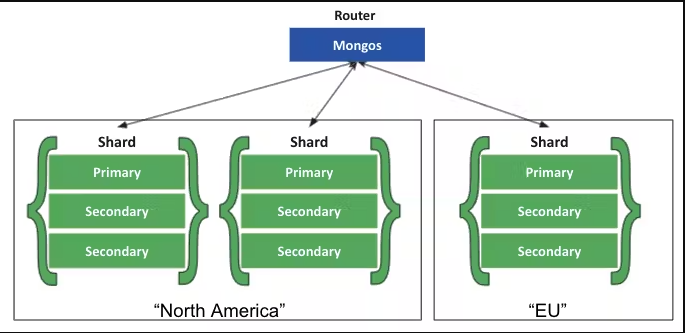
Shard Key:
- MongoDB uses the shard key to distribute collection documents across multiple shards.
- Choice of the shard key impacts performance and scalability.
Chunk Distribution:
MongoDB partitions data into chunks, aiming for an even distribution across shards.
Supports two sharding strategies: hashed and ranged sharding.
Sharded Cluster:
- MongoDB's sharded clusters ensure horizontal scalability by distributing data across machines.
- Each shard, deployed as a replica set, maintains a subset of data.
Replica Sets:
- Automatic failover and data redundancy are ensured within replica sets.
- Primary and secondary instances replicate data asynchronously.
This content outlines MongoDB's fundamental nature, focusing on its document-based structure, data distribution strategies, and coordination mechanisms within a distributed database system.
Redis
Redis is an open-source data structure store that operates as a database, cache, or message broker. Supports various data structures like strings, lists, and maps. It's an in-memory key-value store, optionally offering durability.
Data Distribution In Redis
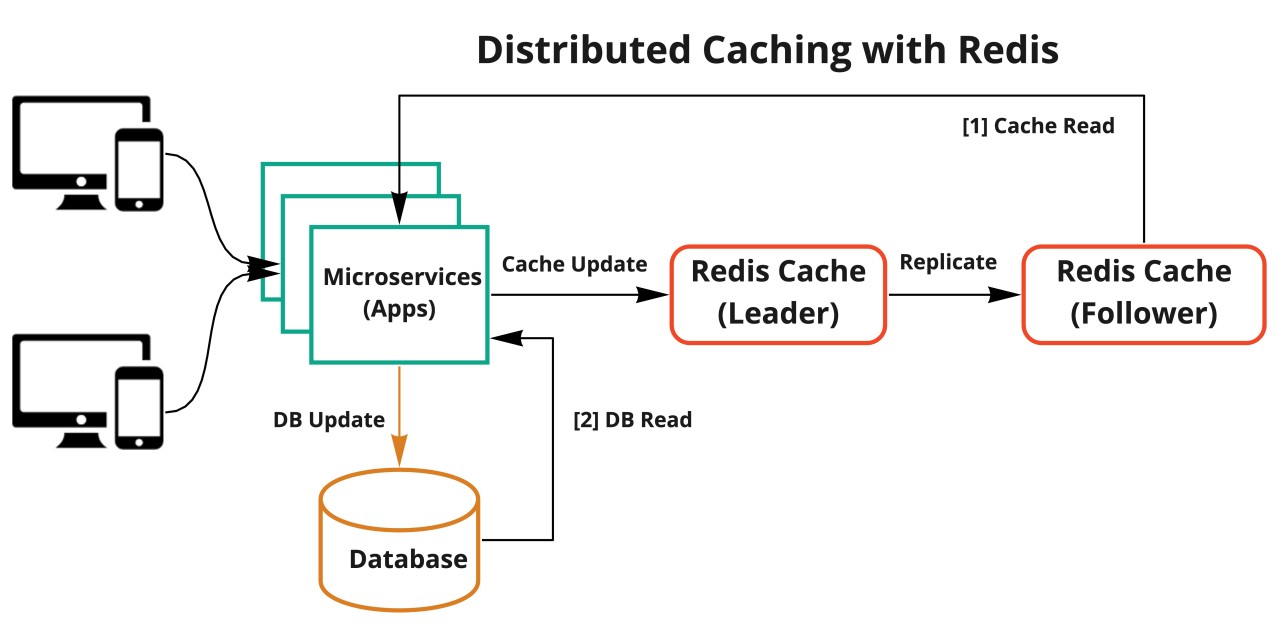
Partitioning Strategies:
- Range partitioning is simplistic but less efficient; divides data into consecutive ranges.
- Hash partitioning uses a standard hash function (like CRC32) to create a hash of the key, facilitating better distribution across instances.
- In redis cluster hash slots the keys are divided into 16384 hash slots, with each node managing a subset, ensuring efficient distribution.
Partitioning Implementation:
- Some Redis clients facilitate partitioning at the client-side for optimal data routing.
- Implementations like Twemproxy serve as proxies for partitioning and routing requests.
- Provides automatic failover and high availability within an instance or shard by monitoring and managing master-slave configurations.
Redis Cluster Architecture:
- Handle data storage, key mapping, cluster detection, and slave promotions.
- Utilizes TCP bus and Redis Cluster Bus, a binary protocol, for inter-node communication.
- Facilitates information propagation across nodes about the cluster's state and changes.
Write Safety and Failover:
- Offers asynchronous replication for higher performance but maintains reasonable write safety against failures.
- Employs a "last failover wins" strategy during partition, ensuring the latest elected master's dataset supersedes others.
- Redirects clients to nodes serving specific keys, allowing clients to receive up-to-date cluster information for direct node interaction.
This content provides additional insights into Redis's data distribution methods, partitioning implementations, and the architecture for coordination and failover mechanisms within a Redis Cluster.
Apache Cassandra
Apache Cassandra is an open-source distributed key-value system designed to handle vast amounts of data across multiple nodes in a seamless and fault-tolerant manner. It adopts a partitioned wide-column storage model, favoring high availability and scalability, making it a popular choice for diverse applications requiring robust data management.
Data Distribution in Cassandra
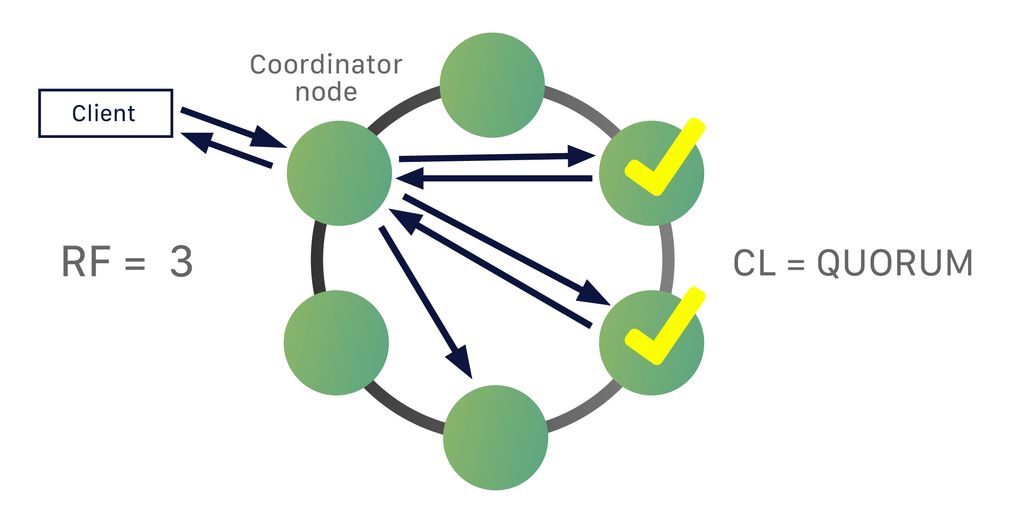
Partitioning Strategy:
- Cassandra employs consistent hashing for uniform data distribution across the nodes, ensuring efficient scalability.
- Utilizes an abstract token ring to map nodes, allowing each node to own a specific token range and, consequently, a subset of data.
Replication and Fault Tolerance:
- Every partition is replicated across multiple physical nodes, enhancing fault tolerance and ensuring data availability.
- Offers flexible replication strategies like Simple Strategy and Network Topology Strategy, allowing customization for diverse data center deployments.
Multi-Master Architecture:
- All cluster nodes can handle read and write operations independently, eliminating single points of failure.
- When receiving a request, the node becomes the coordinator, efficiently routing operations to the appropriate node responsible for the requested data.
Cluster State Management:
- Utilizes the Gossip protocol for peer-to-peer communication among nodes, ensuring the exchange of cluster state information and membership updates.
- Employs vector clocks to timestamp information exchanged through gossip, ensuring the dissemination of the latest cluster state.
This comprehensive overview sheds light on Apache Cassandra's robust data distribution methodology, its sophisticated coordination mechanisms within a multi-node environment, and its strategies for maintaining data consistency and availability.
Long story short
This summary highlights the critical aspects of distributed systems, including their fundamentals, significance, challenges, different architectural models, and their applications in MongoDB, Redis, and Apache Cassandra.
Introduction to Distributed Systems:
- Definition: Networks of computers collaborating toward common goals.
- Key Aspects: Multiple independent components, resource sharing, and task coordination across diverse locations.
- Examples: Cloud computing, peer-to-peer networks, and the internet.
Fundamentals of Distributed Systems:
- Nodes: Individual computational devices within the system.
- Communication Models: Peer-to-peer, Client-Server, and Publish-Subscribe.
- Transparency: Access, Location, and Failure transparency for seamless functionality.
Need for Distributed Systems in the Modern World:
- Scalability: Handling increased demands and user bases flexibly.
- Fault Tolerance: Ensuring continuous operation and resilience against failures.
- Performance: Optimizing speed, data processing, and real-time application support.
- Flexibility: Adapting to changes, modular development, and dynamic workloads.
- Cost Efficiency: Optimizing resource utilization and ensuring a favorable ROI.
Challenges Faced Due to Distributed Systems:
- Consistency and Replication: Data uniformity and conflict resolution among distributed nodes.
- Concurrency and Coordination: Managing concurrent access and synchronization among nodes.
- Security and Privacy: Ensuring secure communication and data protection.
- Network Partitioning: Handling network failures and split-brain scenarios.
- Development Complexity: Architectural intricacies, testing, and ongoing management.
Different Architectures of Distributed Systems:
- Client-Server Architecture: Centralized control and management.
- Peer-to-Peer Architecture: Decentralization and resource sharing.
- Microservices Architecture: Service autonomy and scalability.
- Event-Driven Architecture: Scalability and real-time processing.
- Blockchain and Decentralized Architectures: Trust and immutability.
- Hybrid Architectures: Optimized solutions catering to diverse needs.
Applications of Distributed Systems:
- MongoDB: Document-based, distributed database with effective data distribution and coordination strategies.
- Redis: Versatile data structure store with efficient partitioning and coordination mechanisms.
- Apache Cassandra: Wide-column storage system with robust data distribution and coordination in a fault-tolerant environment.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us