



What is a Lambda Architecture ?



Lambda Architecture is a powerful solution for processing large amounts of data, commonly known as "Big Data." It combines batch-processing and stream-processing methods to compute arbitrary functions.It is particularly used in big data systems to achieve scalability, fault tolerance, and the ability to process data in both real-time and batch modes. The architecture consists of three layers: the batch layer, the serving layer, and the speed layer.
Batch Layer
Manages the master dataset and pre-computes batch views.
Key Responsibilities
- Purpose : Stores the master dataset (an immutable, append-only set of raw data) and precomputes batch views on this dataset.
- Technology : Often uses distributed storage and processing systems like Hadoop, Spark, or similar big data technologies.
- Process : Data is processed in batches, typically at regular intervals (e.g., hourly, daily). This layer ensures accuracy and completeness since it processes large chunks of data, but it may have high latency.
The batch layer in the Lambda Architecture is responsible for managing and processing large volumes of historical data. Its primary role is to process and store the entire data set in a fault-tolerant and scalable manner, typically in batches, and to compute accurate views or results from this data. The batch layer is crucial for ensuring that the system maintains accuracy and completeness, as it deals with large historical datasets that can be processed with high throughput but at a higher latency compared to real-time systems.
Advantages
- Accuracy : Since the batch layer processes the entire dataset, it provides the most accurate and consistent view of the data.
- Simplicity : The batch layer architecture can be simpler compared to real-time systems because it doesn’t need to handle streaming or continuous processing. Data is processed in defined, predictable intervals.
- Scalability : Distributed processing frameworks like Hadoop or Spark allow the batch layer to process enormous datasets efficiently by splitting the work across many nodes.
Limitations
- Latency : Batch processing is inherently slower and introduces higher latency. It might take hours or even days to process a large dataset, which is why the Lambda Architecture includes a speed layer for real-time processing.
- High Resource Usage : Batch processing of massive datasets can require significant computational resources, especially if the data is processed frequently.
- Data Duplication : Since the batch layer and speed layer both handle data processing, some data may need to be stored and processed twice—once in the batch layer and once in the speed layer.
Workflow
- Data Ingestion : Data from various sources (logs, databases, sensors, etc.) is continuously fed into the batch layer. This data is appended to the master dataset.
- Data Processing : At regular intervals, batch jobs are executed over the entire dataset to compute accurate results, such as statistical aggregations or derived data.
- Batch View Creation: The results of the batch processing are stored in batch views, optimized for serving, and are ready for querying by users or applications.
- Serving : The batch views are read by the serving layer, which merges them with real-time views from the speed layer to provide an up-to-date and accurate view of the data.
Commonly Used Technologies
- Storage : HDFS, Amazon S3, Google Cloud Storage, Apache Cassandra.
- Processing Frameworks : Apache Hadoop, Apache Spark, Google Cloud Dataflow.
- Serving Databases : HBase, Apache Cassandra, Amazon DynamoDB.
The batch layer is crucial for handling large historical datasets in a Lambda Architecture, ensuring that the system maintains a complete and accurate representation of the data while handling scalability and fault-tolerance. It complements the speed layer by providing comprehensive views of data over time.
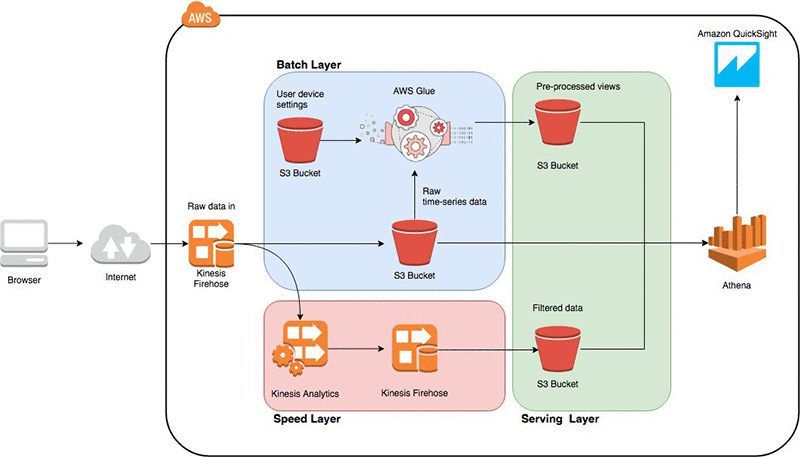
Serving Layer
Key Responsibilities
- Combining Batch and Real-time Views :
- The serving layer takes the accurate, but high-latency, batch views from the batch layer and combines them with the low-latency, possibly less accurate, real-time views from the speed layer.
- This combination allows the system to provide up-to-date results to users, where recent data processed by the speed layer is supplemented with the more comprehensive batch data.
2. Querying and Indexing:
- Data in the serving layer is typically indexed and stored in a way that allows for fast and efficient querying.
- Users or applications can query the serving layer to retrieve data, insights, or analytics results that reflect the latest available information.
- The serving layer must be optimized for quick response times, enabling real-time or near-real-time data retrieval.
3. Data Storage and Management :
- The serving layer stores precomputed views or results, which can be directly queried without requiring further computation.
- This data is usually stored in databases optimized for fast read access, such as NoSQL databases like Apache HBase, Apache Cassandra, or Amazon DynamoDB.
- The storage system must support large-scale data and handle the merging of data from both the batch and speed layers
4. Scalability and Fault Tolerance :
- Like other layers in the Lambda Architecture, the serving layer is designed to be highly scalable, allowing it to handle large amounts of data and numerous queries simultaneously.
- Fault tolerance is also critical in the serving layer, ensuring that the system continues to serve data even in the face of hardware failures or other issues.
Workflow
1. Data Ingestion :
The serving layer ingests data from both the batch and speed layers. Batch views are typically updated periodically, while real-time views are updated continuously or in near real-time.
2. Merging Data :
- The serving layer merges the batch and real-time data. For instance, the real-time view might provide the latest few minutes or hours of data, while the batch view covers the rest of the historical data.
- This merging process needs to ensure consistency and provide the most accurate and up-to-date information possible.
3.Query Handling :
- When a query is made, the serving layer retrieves data from the merged views. The result is a combination of the highly accurate batch-processed data and the low-latency real-time data.
- The serving layer must be optimized to respond to queries quickly, making use of indexes, caching, and other techniques to speed up data retrieval.
4. Serving Results :
The merged and queried data is served to end users or applications. This could be in the form of dashboards, reports, or real-time analytics displays.
Advantages
- Low Latency : By combining batch and real-time data, the serving layer provides both up-to-date and historically accurate data with minimal delay.
- Unified View : The serving layer gives a complete view of the data, combining the comprehensive insights from batch processing with the immediacy of real-time processing.
Scalability: The serving layer can handle large volumes of queries and data, making it suitable for high-demand applications.
Challenges
- Complexity : Merging data from batch and speed layers can be complex, especially when dealing with inconsistencies or ensuring that real-time updates do not conflict with batch updates.
- Data Consistency: Ensuring that the data from the batch and speed layers are consistent and accurately reflect the current state of the system can be challenging.
- Maintenance: The serving layer requires ongoing maintenance to optimize performance and handle growing data volumes.
Commonly Used Technologies :
- Databases : Apache HBase, Apache Cassandra, Amazon DynamoDB, Elasticsearch.
- Indexing Engines : Apache Lucene, Solr, Elasticsearch.
- Caching : Redis, Memcached.
Speed Layer
The Speed Layer in the Lambda Architecture is designed to handle and process data in real-time or near real-time, providing low-latency updates that complement the more comprehensive but slower batch processing done in the batch layer. The speed layer is crucial for scenarios where it's important to have the most up-to-date information available quickly, even if this data might be less accurate or comprehensive compared to batch-processed data.
Key Responsibilities
1. Real-time Data Processing :
- The speed layer processes data as it arrives, often within milliseconds or seconds, making it possible to generate real-time insights and updates.
- Unlike the batch layer, which processes large volumes of data over extended periods, the speed layer focuses on handling smaller, more immediate data streams.
2. Low Latency :
- The primary goal of the speed layer is to provide low-latency processing. This means that as soon as data is ingested, it is processed and made available for querying almost instantly.
- This low latency is crucial for applications that require real-time decision-making or immediate feedback, such as monitoring systems, fraud detection, or recommendation engines.
3. Handling Recent Data:
- The speed layer typically handles the most recent data, often within a short time window. This allows it to provide quick insights into the latest trends, behaviors, or events.
It complements the batch layer by filling in the gaps between batch processing cycles, ensuring that the system can respond to the latest data without waiting for the next batch job to complete.
4.Approximate and Incremental Computation:
- Since the speed layer is designed for real-time processing, it often relies on approximate algorithms or incremental updates rather than full re-computation.
This approach allows the speed layer to provide fast results, even if they might not be as precise as the results from the batch layer.
Workflow :
1. Data Ingestion:
- Data is continuously ingested into the speed layer from various sources, such as event streams, sensors, logs, or real-time user interactions.
- Stream processing frameworks like Apache Kafka, Apache Flink, or Apache Storm are often used to manage this data ingestion.
2. Real-time Processing:
- The ingested data is processed in real-time as it flows through the system. This could involve filtering, aggregating, transforming, or enriching the data.
The processing is often done using a distributed stream processing framework that can handle high-throughput, low-latency data streams.
3.Generating Real-time Views:
- The output of the speed layer is a set of real-time views or materialized results that represent the most current state of the data.
These real-time views are usually less comprehensive than batch views but provide the latest available data.
4. Serving Data:
- The real-time views are sent to the serving layer, where they are combined with batch views to provide a unified view of the data to end-users or applications.
- The speed layer ensures that the system can respond to new data instantly, while the batch layer provides more accurate and comprehensive results over time.
Advantages :
- Low Latency: The speed layer delivers near-instantaneous processing and results, making it ideal for real-time applications.
- Real-time Insights: It allows the system to provide up-to-date information, which is crucial for time-sensitive decisions or actions.
- Scalability: The speed layer is designed to handle large volumes of streaming data in a scalable manner.
Challenges
- Data Accuracy: Since the speed layer often uses approximate algorithms or incremental updates, the results might not be as accurate as those from the batch layer.
- Complexity: Implementing real-time processing requires a more complex system architecture and careful management of data consistency.
- Resource Intensive: Real-time processing can be resource-intensive, especially when dealing with high-throughput data streams.
Commonly Used Technologies :
- Stream Processing Frameworks: Apache Kafka, Apache Flink, Apache Storm, Apache Samza.
- Data Ingestion: Apache Kafka, Amazon Kinesis, Google Cloud Pub/Sub.
- Real-time Databases: Redis, Apache Cassandra, Memcached.
Conclusion:
Lambda Architecture is a scalable and fault-tolerant framework for processing large volumes of data by combining batch and real-time processing. It divides the workload into three layers: the batch layer for accurate, large-scale data processing, the speed layer for low-latency real-time insights, and the serving layer for merging and delivering unified views of the data. This approach ensures both timely and accurate data insights, making it suitable for applications requiring real-time analytics and comprehensive historical data, though it adds complexity in managing and maintaining the different layers.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us