



Introduction to LLMOps for machine learning : Beginners Guide


Large Language Models (LLMs) like GPT and BERT are transforming the landscape of machine learning by enabling applications such as conversational AI, content generation, and advanced analytics. However, managing, deploying, and scaling these models comes with unique challenges, giving rise to the field of LLMOps.
This article is a beginner's guide to understanding LLMOps—the specialized practices and tools for handling LLMs efficiently. Whether you're a data scientist, engineer, or AI enthusiast, this guide will help you grasp the fundamentals and unlock the potential of LLMOps in your machine learning projects.
Benefits for Readers
By reading this article, you'll learn:
- The importance of LLMOps in modern AI workflows.
- How to streamline processes like model fine-tuning, deployment, and monitoring.
- Tools and best practices to manage LLMs effectively.
- Ethical considerations and real-world applications of LLMOps.
What We’ll Cover
- Introduction to LLMOps: Understanding its role and how it differs from MLOps.
- Key Components of LLMOps: A breakdown of training, fine-tuning, deployment, and monitoring processes.
- Challenges and Solutions: Tackling computational costs, scalability, and model performance.
- Tools and Frameworks: Overview of popular tools like Hugging Face and LangChain.
- Best Practices and Tips: Actionable advice for beginners to implement LLMOps effectively.
- Future Trends: Insights into where LLMOps is headed in the evolving AI ecosystem.
By the end of this article, you’ll have a solid foundation to get started with LLMOps and integrate it into your machine learning workflow, making the most out of the power of large language models.
What is LLMOps?

LLMOps, or Large Language Model Operations, is a system of practices and tools designed to manage large language models (LLMs) effectively. These models, like GPT or BERT, are the engines behind many modern AI applications such as chatbots, automated content generation, and virtual assistants. While they are incredibly powerful, they also come with unique challenges due to their size, complexity, and the resources they require.
LLMOps focuses on simplifying and streamlining the entire lifecycle of LLMs. This includes tasks like preparing the data, fine-tuning the model for specific needs, deploying it into real-world systems, and ensuring it keeps performing well over time.
Why Do We Need LLMOps?
Large language models are shaping the future of artificial intelligence, but they are not easy to work with. Here’s why LLMOps is becoming so important:
Managing Complexity: LLMs are much larger and more resource-intensive than traditional machine learning models. They require special tools and strategies to handle their size and computational needs.
Customizing for Real-World Use: A generic language model might not be the best fit for every task. For example, a company might want a model that understands legal documents or customer reviews. LLMOps makes it easier to fine-tune these models for specific industries or tasks.
Making Deployment Easier: Putting an LLM into action isn’t as simple as clicking a button. It needs to be optimized for speed, accuracy, and cost. LLMOps ensures the model runs efficiently in production environments.
Keeping Models Up-to-Date: Over time, the data and needs of a business can change. LLMOps helps in retraining and updating models so they stay relevant and accurate.
Ensuring Fair and Ethical AI: Large language models can unintentionally reflect biases in their training data. LLMOps provides tools to monitor, identify, and reduce bias, ensuring the models are fair and responsible.
Why Does LLMOps Matter to Machine Learning?
Imagine trying to operate a high-performance car without a proper maintenance plan—it might run well for a while, but it’s bound to break down eventually. That’s what happens when large language models are deployed without LLMOps. They may seem magical at first, but without proper management, they can become expensive, slow, or even unreliable.
With LLMOps, businesses can make sure their AI systems are:
- Scalable: Ready to handle growing workloads.
- Cost-effective: Optimized to avoid wasting resources.
- Reliable: Consistently accurate and performing as expected.
- Ethical: Free from harmful biases or unintended consequences.
Role of LLMOps in Machine Learning
Large Language Models (LLMs) are transforming the AI landscape with their ability to process and generate human-like text. However, managing these models effectively requires specialized approaches, as traditional machine learning workflows often fall short. This is where LLMOps comes in, providing targeted tools and practices for handling the unique challenges of large language models.
How LLMOps Complements MLOps
LLMOps builds on the foundations of MLOps, extending its capabilities to address the specific needs of LLMs. While MLOps is designed for general machine learning model management, LLMOps focuses on the distinct requirements of large-scale language models.
1. Handling Scale and Complexity
- MLOps is well-suited for smaller, domain-specific models, but LLMs demand far greater computational resources and infrastructure due to their size and complexity. LLMOps introduces techniques like distributed training and inference optimization to manage these requirements effectively.
2. Specialized Fine-Tuning
- In MLOps, fine-tuning typically involves retraining models on new data. With LLMOps, fine-tuning becomes more complex, often requiring domain-specific strategies and tools for adapting pre-trained models to niche tasks.
3. Inference Efficiency
- Traditional MLOps handles model deployment efficiently, but the sheer size of LLMs makes real-time inference a challenge. LLMOps optimizes inference pipelines through methods like model compression, quantization, and caching to ensure responsiveness.
4. Monitoring and Maintenance
- MLOps provides general monitoring tools to track model performance. LLMOps takes this further with advanced monitoring tailored for LLMs, focusing on aspects like output quality, latency, and ethical concerns.
5. Ethical AI Management
- While MLOps includes basic mechanisms for bias detection, LLMOps emphasizes thorough auditing and mitigation strategies to ensure that large-scale models generate fair and responsible outputs.
6. Collaboration Across Roles
- LLMOps bridges the gap between MLOps workflows and the unique requirements of LLMs, enabling better collaboration between AI teams, DevOps, and business stakeholders.
Why LLMOps is Essential
By complementing and extending MLOps, LLMOps ensures that the immense potential of large language models is realized efficiently and responsibly. It provides a tailored framework for managing LLMs at scale, enabling their effective integration into machine learning workflows and real-world applications.
Key Components of LLMOps
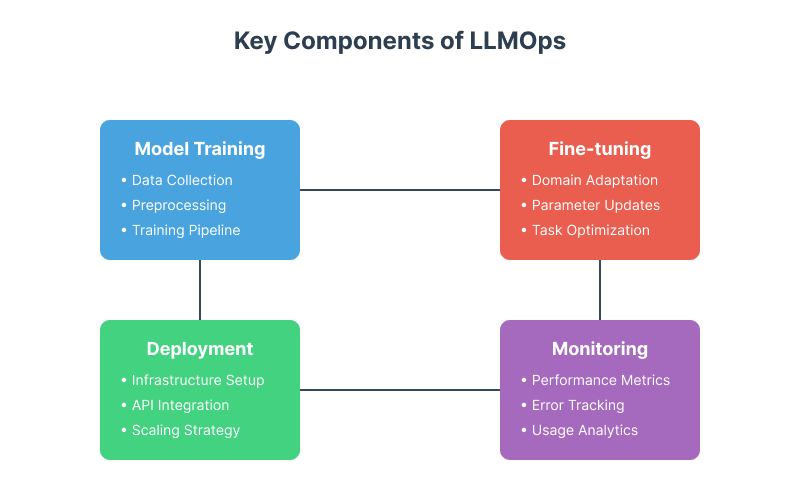
Managing large language models (LLMs) effectively requires a well-structured approach to ensure they perform optimally in real-world applications. LLMOps breaks this process into key components, each addressing a specific stage in the lifecycle of an LLM. These components include model training, fine-tuning, deployment, and monitoring.
Model Training
What it is: Model training involves building an LLM from scratch or using an existing pre-trained model as a foundation. It requires vast datasets and substantial computational resources to ensure the model understands a wide range of language patterns.
Key aspects:
- Data Preparation: Cleaning and organizing datasets to improve model quality.
- Infrastructure: Using distributed systems like GPUs or TPUs to handle the computational load.
- Optimization: Techniques like gradient descent and adaptive learning rates to enhance training efficiency.
Challenges Addressed by LLMOps:
- Managing large datasets and ensuring their quality.
- Efficiently utilizing compute resources to reduce time and cost.
Fine-Tuning
What it is: Fine-tuning is the process of adapting a pre-trained model to a specific task or domain by retraining it on specialized datasets. For example, an LLM can be fine-tuned to understand legal documents or customer service conversations.
Key aspects:
- Task-Specific Data: Collecting domain-relevant data for retraining.
- Parameter Adjustment: Modifying model weights to optimize performance for the new task.
- Evaluation: Measuring task-specific performance to validate the fine-tuning process.
Challenges Addressed by LLMOps:
- Automating and scaling fine-tuning workflows for multiple use cases.
- Ensuring that fine-tuning doesn’t degrade the model’s performance on general tasks.
Deployment
What it is: Deployment is the process of making an LLM available for use in production systems. This could be through APIs, applications, or integrated systems.
Key aspects:
- Model Serving: Hosting the model for real-time or batch processing.
- Latency Optimization: Reducing response times to meet user demands.
- Scalability: Ensuring the system can handle increasing loads without performance degradation.
Challenges Addressed by LLMOps:
- Managing infrastructure costs while ensuring high performance.
- Optimizing models for deployment environments, such as edge devices or cloud servers.
Monitoring
What it is: Monitoring involves tracking the performance and behavior of an LLM in production to ensure it continues to meet expectations over time.
Key aspects:
- Performance Metrics: Tracking latency, accuracy, and throughput.
- Drift Detection: Identifying changes in data patterns that might reduce the model’s effectiveness.
- Error Analysis: Investigating and resolving issues like incorrect or biased outputs.
Challenges Addressed by LLMOps:
- Automating monitoring to quickly detect and respond to issues.
- Providing insights into model behavior to improve future iterations.
Why These Components Matter
These key components—training, fine-tuning, deployment, and monitoring—form the backbone of LLMOps. Together, they ensure that large language models are built, customized, and managed in a way that maximizes their value while minimizing risks. By addressing each stage systematically, LLMOps enables organizations to unlock the full potential of LLMs in real-world scenarios.
Challenges in Managing Large Language Models
Large Language Models (LLMs) have revolutionized AI applications, but managing them effectively comes with significant challenges. These include the need for extensive computational resources, ensuring data privacy and security, and addressing cost management concerns. Let’s explore these challenges in detail.
1. Computational Resources
The Challenge: LLMs are computationally intensive, requiring massive amounts of processing power and memory. Training or even fine-tuning these models demands high-performance hardware, often using GPUs or TPUs in distributed systems. Running these models in real-time for inference also places a heavy burden on infrastructure.
Key Issues:
- Scalability: Managing large-scale distributed training across multiple nodes.
- Latency: Ensuring fast response times during inference, especially in real-time applications.
- Energy Consumption: High energy requirements make LLMs less sustainable.
Possible Solutions:
- Leveraging optimized frameworks like PyTorch or TensorFlow for distributed training.
- Using techniques like model pruning, quantization, or knowledge distillation to reduce model size without sacrificing performance.
- Employing cloud-based platforms with scalable GPU/TPU resources.
2. Data Privacy and Security
The Challenge: Training LLMs often involves using vast datasets, some of which may include sensitive or proprietary information. Ensuring that the data used for training and the outputs generated by the model comply with privacy laws and security standards is critical.
Key Issues:
- Regulatory Compliance: Adhering to data protection laws such as GDPR, HIPAA, or CCPA.
- Sensitive Information: Preventing models from memorizing and leaking private data.
- Adversarial Attacks: Protecting models from being exploited to produce harmful or biased outputs.
Possible Solutions:
- Implementing differential privacy techniques to anonymize data used during training.
- Regularly auditing models to ensure they don’t retain sensitive information.
- Using secure storage and encryption for datasets and model artifacts.
3. Cost Management
The Challenge: Training and deploying LLMs are expensive. From the hardware required for training to the ongoing costs of running inference at scale, the financial burden can be prohibitive for many organizations.
Key Issues:
- Training Costs: High compute requirements can make training an LLM cost millions of dollars.
- Deployment Costs: Inference, particularly at scale, requires continuous computational resources, leading to high operational expenses.
- Infrastructure Investment: Setting up on-premises hardware or paying for cloud resources adds to the overall cost.
Possible Solutions:
- Utilizing pre-trained models and fine-tuning them instead of training from scratch.
- Optimizing inference with techniques like caching, batching, and serverless architecture.
- Monitoring and scaling resource usage based on actual demand to avoid unnecessary expenses.
Building an LLMOps Pipeline
An effective LLMOps pipeline ensures the smooth lifecycle management of large language models (LLMs), from preparing data to deploying and maintaining the model in production. Here's a breakdown of the key stages in building such a pipeline:
1. Data Preparation and Preprocessing
What It Involves: The foundation of any LLM is the data it’s trained on. Preparing and preprocessing this data ensures the model learns accurately and effectively.
Steps:
- Data Collection: Gather diverse, high-quality datasets relevant to the target use case.
- Data Cleaning: Remove errors, duplicates, and inconsistencies from the data.
- Preprocessing: Tokenize text, normalize language (e.g., handling casing, punctuation), and format it for the LLM architecture.
- Data Augmentation: Enhance the dataset with techniques like paraphrasing or back-translation to improve robustness.
Challenges:
- Ensuring data quality and eliminating bias.
- Managing large datasets efficiently.
- Complying with privacy regulations.
2. Model Training and Fine-Tuning
What It Involves: Training involves building the model from scratch or using a pre-trained model, while fine-tuning adapts the model to specific tasks or domains.
Steps:
- Training Setup: Define model architecture, training objectives, and hyperparameters.
- Distributed Training: Use multi-node setups with GPUs/TPUs for scalability.
- Fine-Tuning: Leverage pre-trained models and retrain them with task-specific data.
- Validation: Evaluate the model on test data to ensure it meets performance benchmarks.
Challenges:
- High computational resource demands.
- Risk of overfitting during fine-tuning.
- Optimizing training time and cost.
3. Model Serving and Deployment
What It Involves: Once the model is trained and fine-tuned, it needs to be deployed to serve predictions efficiently in real-world applications.
Steps:
- Model Serialization: Save the trained model in a format optimized for serving, such as ONNX or TensorFlow SavedModel.
- Serving Infrastructure: Use platforms like TensorFlow Serving, TorchServe, or cloud-based services to host the model.
- Latency Optimization: Implement batching, caching, and quantization to improve inference speed.
- Scalability: Ensure the system can handle fluctuating workloads using auto-scaling.
Challenges:
- Balancing latency and resource usage.
- Ensuring fault tolerance and high availability.
- Protecting the model from unauthorized access.
4. Continuous Monitoring and Updates
What It Involves: Monitoring the model in production ensures it continues to perform as expected over time. Regular updates keep the model aligned with new data and requirements.
Steps:
- Performance Tracking: Monitor key metrics like accuracy, latency, and throughput.
- Drift Detection: Identify data or concept drift that may degrade model performance.
- Feedback Loop: Collect user feedback and use it to refine the model.
- Retraining and Updates: Periodically update the model with fresh data to maintain relevance.
Challenges:
- Detecting subtle changes in data patterns.
- Automating the retraining process.
- Balancing update frequency with operational stability.
Popular Tools for LLMOps
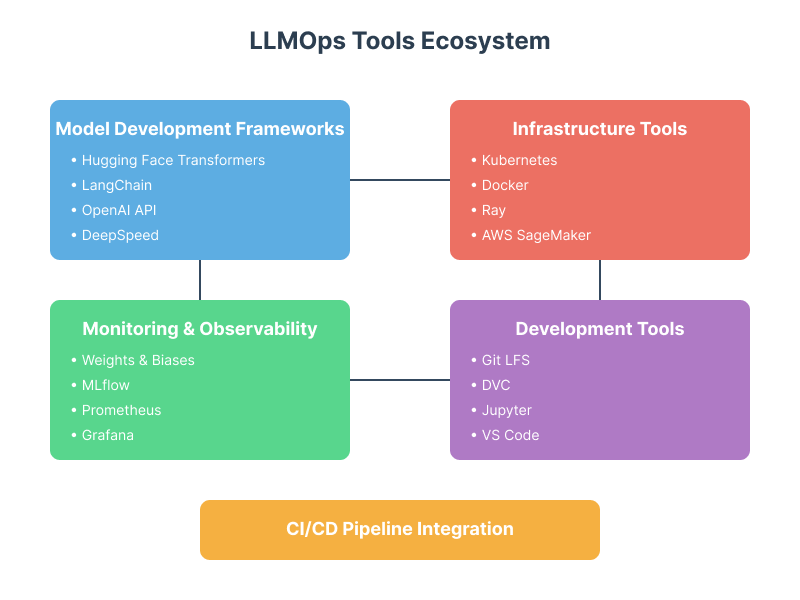
Building and managing large language models (LLMs) requires a combination of specialized frameworks and robust infrastructure tools. These tools simplify processes like training, fine-tuning, deploying, and scaling LLMs, making them essential components of LLMOps. Here’s a look at some of the most popular tools in the ecosystem:
Frameworks for LLMOps
Hugging Face
- What It Is: A leading platform for working with pre-trained models and fine-tuning them for specific tasks.
- Key Features:
- Why Use It: Hugging Face simplifies the process of fine-tuning and deploying LLMs, making it ideal for beginners and professionals alike.
LangChain
- What It Is: A framework for building applications powered by LLMs, with a focus on combining them with external data and workflows.
- Key Features:
- Why Use It: LangChain is perfect for creating advanced applications like chatbots and document analysis systems that rely on LLMs.
OpenAI APIs
- What It Is: APIs provided by OpenAI to access models like GPT-3, GPT-4, and Codex.
- Key Features:
- Why Use It: OpenAI APIs remove the need for local infrastructure, offering scalable solutions for deploying LLMs quickly.
Infrastructure Tools for LLMOps
Kubernetes
- What It Is: An open-source system for automating deployment, scaling, and management of containerized applications.
- Key Features:
- Why Use It: Kubernetes is ideal for deploying and scaling LLMs in production environments, especially when dealing with high traffic.
Docker
- What It Is: A platform for developing, shipping, and running applications in isolated containers.
- Key Features:
- Why Use It: Docker ensures consistency across development and production environments, making it easier to deploy and maintain LLMs.
Ray
- What It Is: A distributed computing framework for scaling Python workloads, including ML training and inference.
- Key Features:
- Why Use It: Ray is designed for scaling LLM workloads efficiently, making it a go-to tool for training and serving large models.
Real-World Applications of LLMOps
LLMOps is revolutionizing how large language models (LLMs) are applied in real-world scenarios. By streamlining the development, deployment, and management of LLMs, LLMOps enables diverse and impactful applications. Here are some notable examples:
1. Chatbots and Virtual Assistants
- How They Work: LLMs power conversational agents like chatbots and virtual assistants, enabling them to understand and generate human-like text.
- Applications:
- Role of LLMOps: LLMOps ensures efficient fine-tuning of LLMs for specific industries and manages real-time inference to maintain responsiveness.
2. Content Generation
- How They Work: LLMs can generate articles, marketing copy, product descriptions, and even code snippets with minimal human input.
- Applications:
- Role of LLMOps: LLMOps helps manage workflows for training LLMs on specific writing styles or brand guidelines, optimizing their output for quality and consistency.
3. Sentiment Analysis
- How It Works: LLMs analyze text to determine the sentiment (positive, neutral, or negative) expressed by users.
- Applications:
- Role of LLMOps: LLMOps ensures models are updated regularly with new data to improve accuracy and stay relevant to changing trends in user sentiment.
Future of LLMOps
As the field of LLMOps evolves, several exciting trends and innovations are shaping its future. Here are some key developments to watch:
1. Scaling LLMs for Efficiency
- Trend: Developing strategies to reduce the computational demands of LLMs without sacrificing performance.
- Innovations:
2. Ethical AI Practices
- Trend: Increasing focus on ensuring LLMs are fair, unbiased, and responsible in their outputs.
- Innovations:
3. Real-Time Adaptation
- Trend: Enabling LLMs to adapt to new data and tasks without extensive retraining.
- Innovations:
4. Integration with Emerging Technologies
- Trend: Combining LLMOps with advancements in other fields to unlock new possibilities.
- Innovations:
5. Democratization of LLMs
- Trend: Making LLMs accessible to smaller organizations and individual developers.
Comparing LLMOps and MLOps
Both LLMOps (Large Language Model Operations) and MLOps (Machine Learning Operations) focus on streamlining the lifecycle management of machine learning models, but they cater to different needs. While MLOps provides a general framework for managing all types of ML models, LLMOps extends these principles to address the unique challenges posed by large language models (LLMs).Here’s a comparison of the key similarities and differences between the two practices:
Conclusion
LLMOps is an essential extension of MLOps, tailored specifically to manage the unique challenges of large language models. From efficient training and fine-tuning to scalable deployment and continuous monitoring, LLMOps provides the tools and practices needed to unlock the full potential of LLMs while addressing their complexity.
This article highlights how LLMOps simplifies working with LLMs, ensuring better performance, scalability, and ethical use. By understanding and implementing LLMOps, you can effectively leverage large language models for real-world applications like chatbots, content generation, and sentiment analysis.
How This Benefits You:
- For Beginners: Learn how to manage and deploy LLMs efficiently.
- For Practitioners: Gain insights into tools and best practices for handling large-scale models.
- For Businesses: Understand how to integrate LLMs into your workflows to drive innovation and efficiency.
With LLMOps, you can confidently manage the lifecycle of large language models, ensuring they deliver maximum value in a cost-effective and ethical way.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us