



Top 5 Pre trained Models in NLP



The world of Natural Language Processing (NLP) has been transformed by pre-trained models. From chatbots and voice assistants to content search and summarization tools, these models power much of the AI we interact with daily. But not all models are built for the same tasks.
Pre-trained models eliminate the need for training from scratch, saving both time and compute resources.
These models are trained on large corpora of text data and can be fine-tuned on specific downstream tasks like sentiment analysis, summarization, translation, and more.
In this guide, we break down the top pre-trained NLP models, compare their use cases, and help you decide which is the best fit for your AI application
What Are Pre-Trained NLP Models?
Pre-trained models are deep learning architectures trained on massive datasets before being fine-tuned for specific tasks.
Think of them as AI engines that already understand grammar, syntax, and meaning before you even start using them.
They help reduce training time and data requirements while improving performance in tasks like
- Sentiment analysis
- Text classification
- Chatbot training
- Document summarization
- Question answering
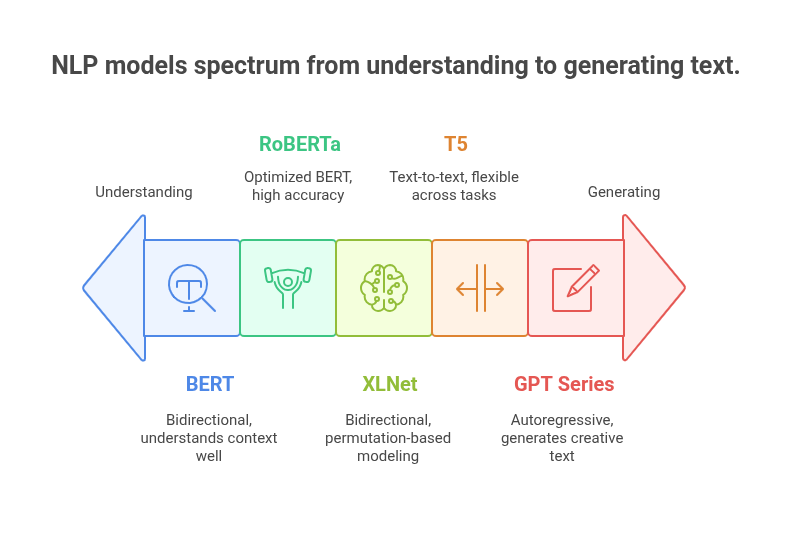
Comparing NLP Models
BERT (Bidirectional Encoder Representations from Transformers)
Developed by: Google AI Language
Released: 2018
GitHub: BERT GitHub Repo
Key Paper: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
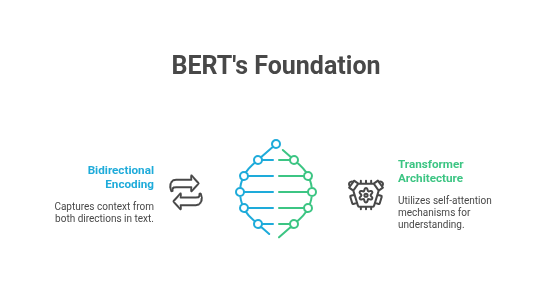
What is BERT?
BERT was the first truly bidirectional transformer model, and it changed everything. Prior to BERT, models like GPT-1 processed text either left-to-right or right-to-left.
This unidirectionality limited the contextual understanding of a word in a sentence. BERT introduced Masked Language Modeling (MLM), which allows the model to learn context from both directions simultaneously.
How Does It Work?
BERT uses two main objectives during pretraining:
- Masked Language Modeling (MLM): Randomly masks tokens in the input and trains the model to predict them.
- Next Sentence Prediction (NSP): Trains the model to understand sentence relationships, key for QA and inference.
Key Features:
- Based on Transformer architecture.
- Trained on large corpora like Wikipedia and BookCorpus.
- Supports fine-tuning on specific downstream tasks (e.g., sentiment analysis, NER).
- Outperformed existing benchmarks on GLUE, SQuAD, and more.
Common Use Cases:
- Google Search (since 2019) now uses BERT for better understanding of queries.
- Named Entity Recognition (NER) in legal and financial documents.
- Text classification tasks like spam detection or emotion recognition.
Limitations
- Heavy compute requirements for training and even inference.
- Designed for relatively short texts (512 tokens).
Variants
- TinyBERT, MobileBERT, and DistilBERT are optimized for mobile and edge use.
- Multilingual BERT (mBERT)—trained on over 100 languages.
GPT (Generative Pre-trained Transformer) Series
Developed by: OpenAI
Released: GPT (2018), GPT-2 (2019), GPT-3 (2020), GPT-4 (2023), GPT-4o (2024)
API Access: OpenAI Platform
GPT-3 Paper: Language Models are Few-Shot Learners
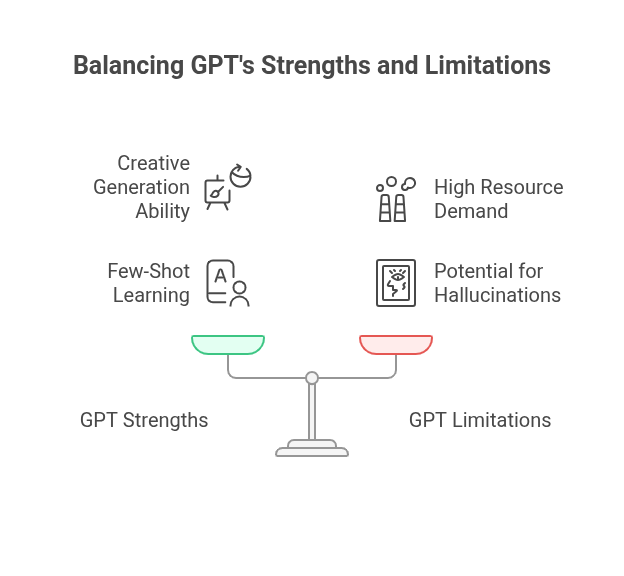
What Makes GPT Special?
While BERT focused on understanding language, GPT focused on generating it. GPT uses a decoder-only Transformer architecture to predict the next word in a sequence, making it an autoregressive model. This approach is perfect for free-form text generation, code completion, and dialogue systems.
Evolution of GPT Models
- GPT-2 shocked the world with its ability to write essays and articles.
- GPT-3 (175 billion parameters) introduced few-shot and zero-shot learning.
- GPT-4 and GPT-4o brought multimodal capabilities, combining text, vision, and speech in one model.
Key Features:
- Autoregressive language model (predicts the next word).
- GPT-3 and later models support few-shot, zero-shot, and chain-of-thought reasoning.
- Can handle multi-modal inputs (e.g., GPT-4o handles text, audio, and images).
Common Use Cases:
- Chatbots and virtual assistants
- Code generation (e.g., GitHub Copilot)
- Text summarization and creative writing
Limitations:
- Large models require significant resources to host and fine-tune.
- May produce hallucinations or biased content if not properly aligned.
RoBERTa (Optimized BERT Approach)
Developed by: Facebook AI (Meta AI)
Released: 2019
GitHub:RoBERTa on HuggingFace
Key Paper: RoBERTa: A Robustly Optimized BERT Pretraining Approach
Why RoBERTa?
RoBERTa is essentially BERT on steroids. Researchers at Facebook AI discovered that BERT was undertrained, so they retrained it using better methods:
- Removed NSP (which may not be that useful).
- Increased batch size and training time.
- Used more data (CommonCrawl news, OpenWebText, etc.).
Improvements Over BERT
- No NSP task.
- Trained with longer sequences (up to 512 tokens).
- Larger batch sizes and learning rates.
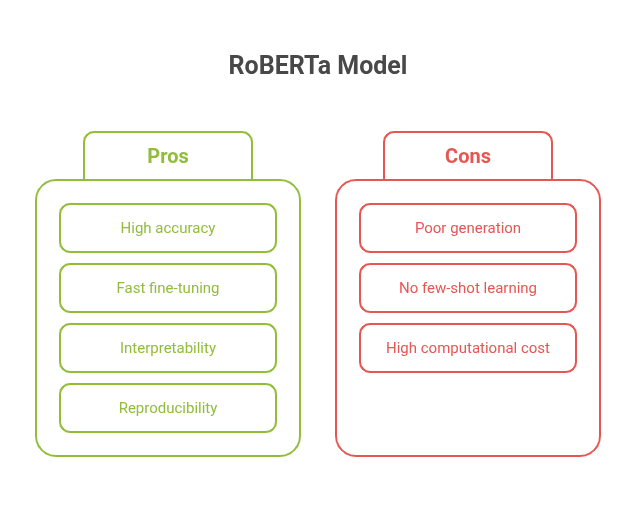
Key Features
- Optimized pretraining of BERT architecture.
- Trained on more data (e.g., CommonCrawl).
- Often outperforms BERT in classification and QA benchmarks.
Common Use Cases
- Text classification
- Sentiment analysis
- Legal and medical document understanding (when fine-tuned)
Limitations
- Like BERT, it doesn’t handle generation tasks well.
- Lacks GPT’s few-shot learning abilities.
T5 (Text-To-Text Transfer Transformer)
Developed by: Google Research
Released: 2020
Paper: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
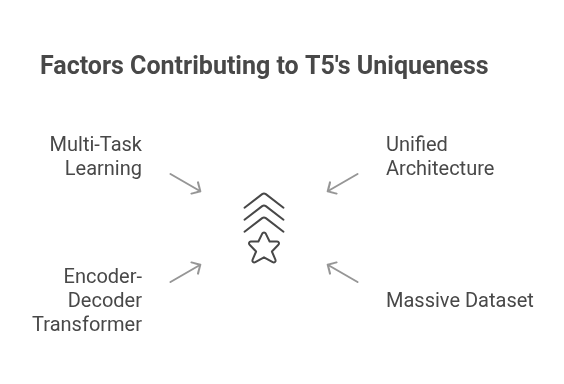
What Makes T5 Unique?
T5 treats every NLP task as a text-to-text problem. This means that both inputs and outputs are text strings. Whether it's translation, summarization, or classification, T5 frames it as
<task>: <input> → <output>
This unified architecture simplifies multi-task learning and makes the model flexible across diverse applications.
Key Features:
- Encoder-decoder transformer architecture.
- Trained on a diverse dataset called C4 (Colossal Clean Crawled Corpus).
- Excellent performance on summarization and question-answering tasks.
Common Use Cases:
- Machine translation
- Text summarization
- Question answering
Limitations
- Slower than decoder-only models (like GPT) during inference.
- Larger models like T5-11B require serious GPU/TPU resources.
XLNet
Developed by: Google/CMU
Released: 2019
Paper: XLNet: Generalized Autoregressive Pretraining
Why XLNet?
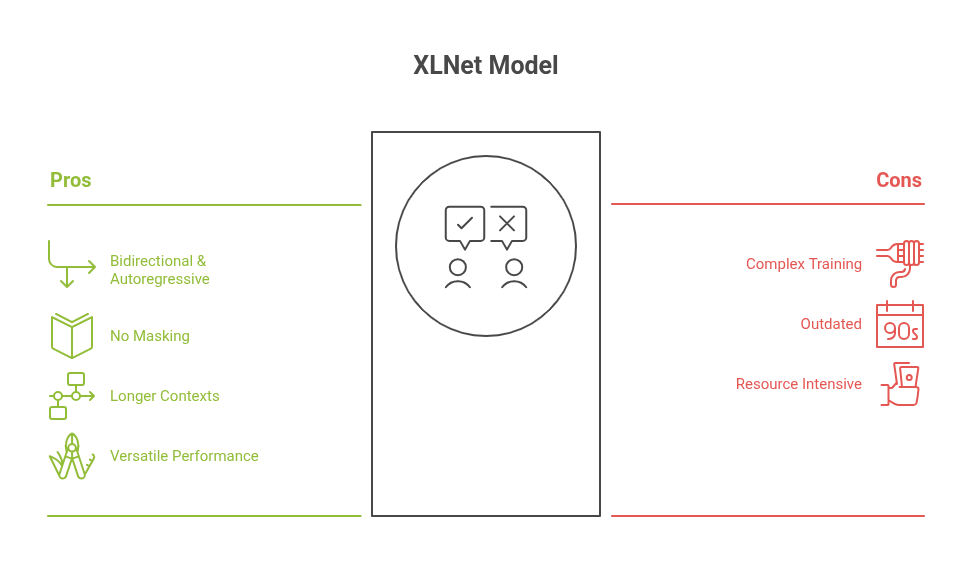
XLNet aims to get the best of both worlds: the bidirectionality of BERT and the autoregressive modeling of GPT. Instead of masking tokens like BERT, XLNet uses permutation-based language modeling, predicting tokens in all possible orders.
Key Features:
- Handles longer context compared to BERT.
- More flexible word order modeling.
- Outperforms BERT in several downstream benchmarks.
Common Use Cases:
- Document classification
- Sentiment analysis
- QA systems with long passages
Limitations
- More complex and harder to train than BERT.
- Slightly outdated with newer transformer variants now available.
Honorable Mentions
While the models above are leaders in their own right, a few more deserve a shoutout:
- DistilBERT: A lighter, faster version of BERT, great for production environments
- ALBERT: A lite BERT that uses parameter sharing to reduce size without losing much performance.
- Flan-T5: A fine-tuned version of T5 for instruction-following tasks.
- ERNIE, ELECTRA, and DeBERTa are popular models in China, healthcare, and enterprise NLP applications.
How to Choose the Right Pre-Trained Model?
When choosing an NLP model, consider the following:
Final Thoughts
The pace of progress in NLP is nothing short of astonishing. Models like BERT, GPT, T5, and others have democratized access to advanced AI, letting anyone build powerful language applications. These models aren’t just academic experiments — they’re powering apps you use every day: Gmail, Google Search, Siri, ChatGPT, and more.
As compute becomes more accessible and model efficiency improves, we’ll likely see even more versatile, compact, and intelligent models that bridge language, vision, and audio seamlessly — and pre-trained models will remain at the heart of this revolution.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us