



Intro to Ray : The swiss knife of distributed computing


Introduction
If you've ever tried to scale up a Python project that does some kind of heavy lifting—maybe training a machine learning model, crunching through data, or running a simulation—you've probably hit that frustrating wall where your laptop says "nope." It gets hot, fans go crazy, and then your script just crawls. And sure, you could move everything to the cloud or spin up a cluster—but suddenly, you're knee-deep in Docker files, Kubernetes configs, or some obscure parallelization library that works great... if you have a PhD in distributed systems.
That's where Ray comes in.
Ray doesn’t try to be flashy. It doesn’t try to replace all your tools or force you into some new way of thinking. What it does is make distributed computing feel like you're still just writing regular Python code—but with way more horsepower under the hood.
.png)
What Even Is Ray?
Ray is an open-source framework that helps Python developers scale their code beyond a single machine. It started at UC Berkeley’s RISELab and has grown into a pretty active ecosystem. You might hear it mentioned alongside big names like OpenAI, Uber, or Shopify—companies that use Ray to power serious workloads without babysitting servers all day.
The cool part? It doesn’t matter whether you’re working on a MacBook or managing a cloud cluster—Ray gives you tools that make spinning up parallel and distributed tasks almost too simple. We're talking:
- Running functions in parallel with just a decorator.
- Sharing memory between tasks and actors.
- Spreading work across a bunch of machines without needing to understand message passing, cluster management, or job queues.
If you’ve heard the term “Swiss knife of distributed computing,” this is what folks mean. It’s not just one thing—it’s a bunch of tiny useful things all rolled into one toolkit.
First Impressions: What Makes Ray Different?
One of Ray’s biggest strengths is that it doesn’t require you to buy into a massive ecosystem just to get started. You don’t need to ditch Pandas or Scikit-learn or PyTorch. You just... import Ray and keep writing Python.
Let’s say you have a function that takes a few seconds to run, and you want to call it 10 times. With regular Python, you'd just loop over it. But that’s gonna take a while. With Ray, you do this:
import ray
ray.init()
@ray.remote
def my_function(x):
return x * 2
futures = [my_function.remote(i) for i in range(10)]
results = ray.get(futures)That's it. That .remote decorator is the magic. Your code looks and feels like plain Python, but now those function calls are running in parallel, whether it’s on your laptop’s cores or across a fleet of cloud VMs.
No fiddling with threads. No complex job queues. Just a little sprinkle of Ray.
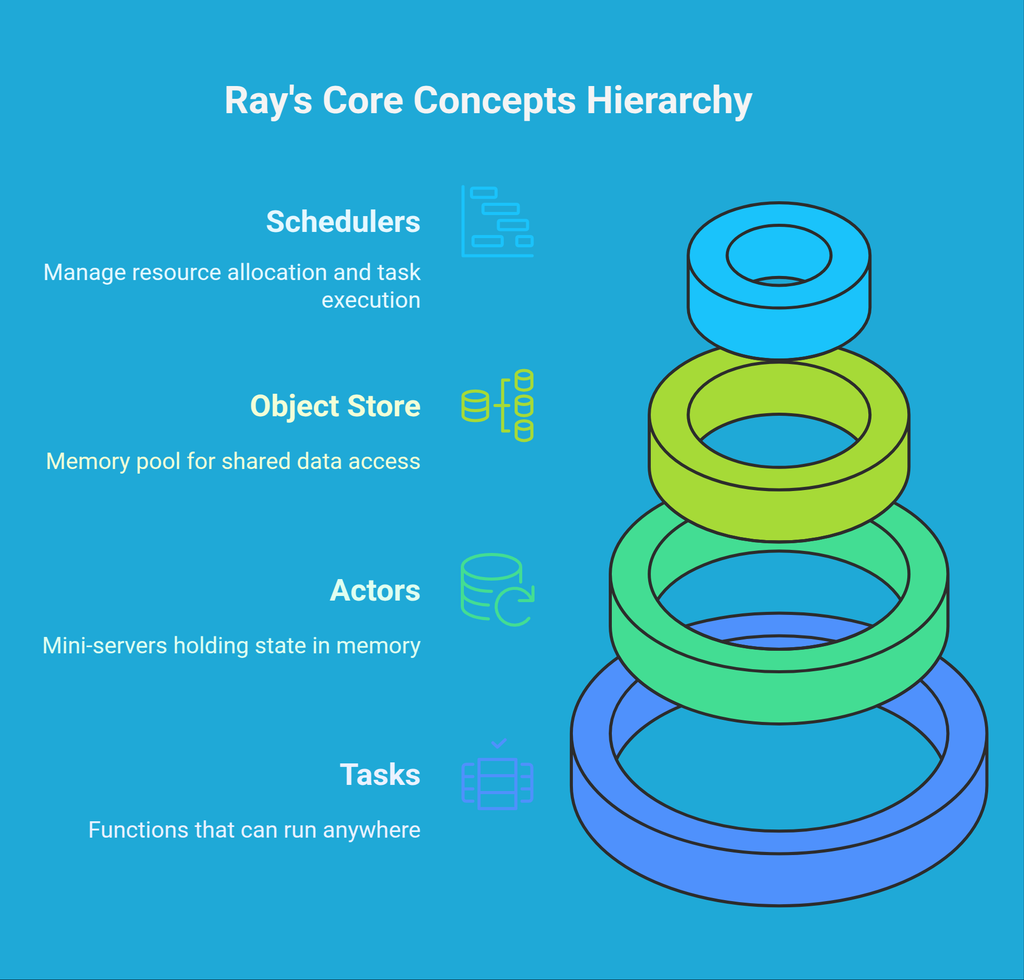
Ray’s Core Concepts
1. Tasks
Think of tasks as regular functions, but they can run somewhere else. Like, on another CPU core, another machine, or even another cloud server. You don’t really care where—they just run.
2. Actors
Actors are like mini-servers in your code. Imagine you want to keep some state—like a counter or a trained model—between function calls. Instead of reloading or recalculating every time, you use an actor. It sticks around and holds that state in memory for you.
3. Objects and Object Store
When you return values from tasks or actors, they go into Ray's object store. It’s kind of like a memory pool that everyone can access without copying stuff around. If you’re working with large datasets, this is huge—it avoids a lot of the usual memory shuffling that slows things down.
4. Schedulers and Resources
Ray handles where things should run. It looks at what resources (like CPUs or GPUs) are available and decides how to spread your tasks around. You can even tell it to only run certain tasks on GPUs, or reserve memory for specific jobs.
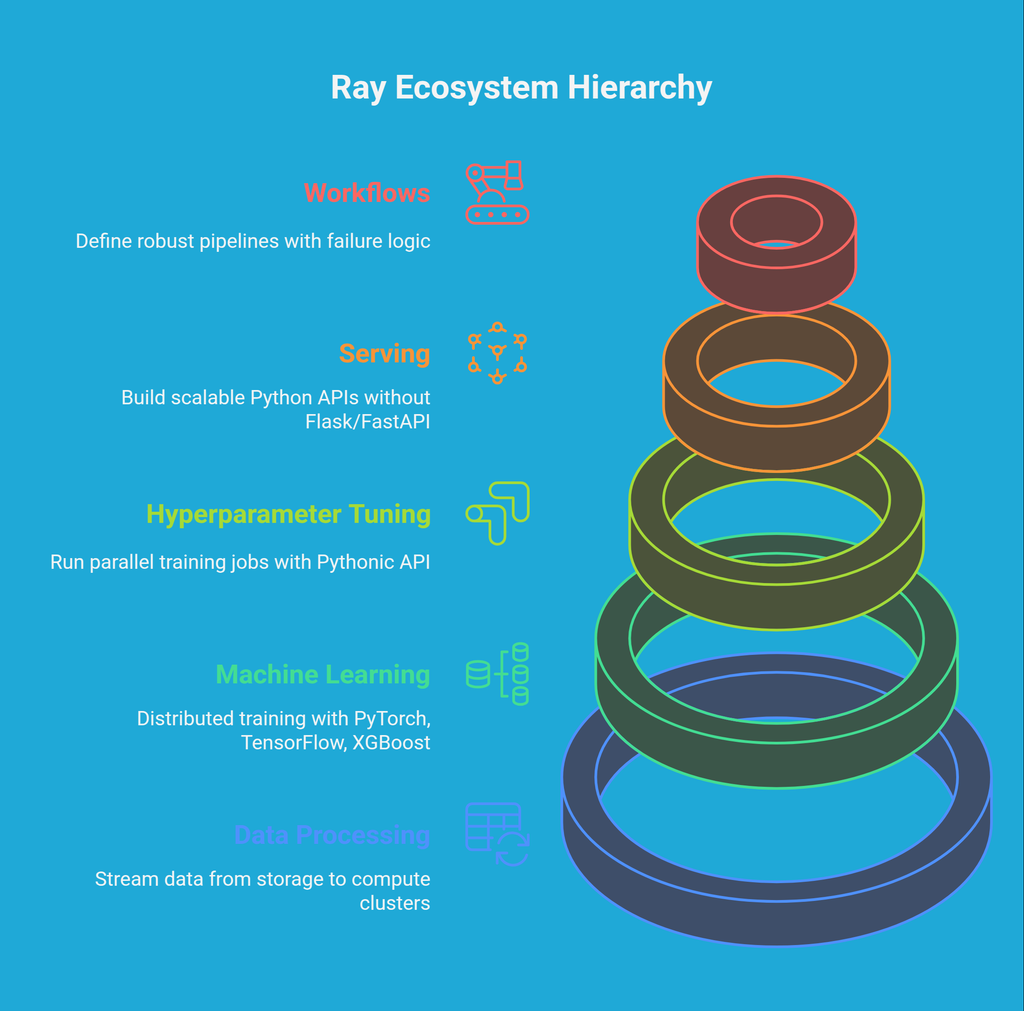
What Can You Build With Ray?
1. Machine Learning (Ray Train)
If you're training models and want to go beyond one GPU or one machine, Ray Train lets you do distributed training with frameworks like PyTorch, TensorFlow, or XGBoost. It handles all the gritty details like synchronization, fault recovery, and setup.
2. Hyperparameter Tuning (Ray Tune)
Tuning hyperparameters usually means writing a bunch of for-loops or using some outside tool. Ray Tune makes it dead simple to run 50+ training jobs in parallel, try out different parameter combinations, and log the results—all with a clean, Pythonic API.
3. Data Processing (Ray Data)
Need to process a big CSV, apply transformations, and feed it into a model? Ray Data gives you a pipeline that can stream data from storage into compute clusters, batch by batch.
4. Serving (Ray Serve)
Once you've got a trained model, you’ll probably want to serve it somewhere. Ray Serve helps you build fast, flexible Python APIs that scale across nodes without needing to run Flask or FastAPI on your own.
5. Workflows (Ray Workflows)
Long-running processes, retries, failures, checkpoints? If that’s your world, Ray Workflows gives you tools to define robust pipelines with logic for when things go sideways.
Ray in Action: A Few Real-Life Use Cases
Let’s ground this in some reality. Here’s how folks actually use Ray:
- Machine Learning Teams: Let’s say a team is building models for fraud detection. They want to train hundreds of model versions to test performance. Ray Tune + Ray Train lets them do this without building infrastructure from scratch.
- Bioinformatics Pipelines: Think genomic sequencing, protein folding, or medical image analysis—stuff that involves massive datasets and long processing times. Ray can split those jobs up across dozens of machines and stitch them back together.
- Simulation Engines: Whether it's simulating self-driving cars or financial systems, Ray makes it easy to run lots of simulations in parallel and keep the results organized.
- Video Processing: Converting, analyzing, or transforming thousands of videos? Ray helps by distributing the workload in a way that makes it manageable and fast.
Ray’s learning curve is pretty gentle, especially if you're already comfortable with Python. Here’s what we recommend to get rolling:
1. Install Ray:
pip install ray- Play With the Basics:
Start by using.remoteon simple functions and callingray.get()to collect the results. Try running tasks in parallel and see how it feels.
- Try Out Ray Tune or Serve:
Depending on your needs, experiment with one of the higher-level libraries. Ray Tune has great built-in examples for hyperparameter searches. - Check the Dashboard:
When you runray.init(), you’ll often get access to a local web dashboard. It shows what tasks are running, how resources are being used, and helps you debug things visually. - Use Ray on the Cloud:
Eventually, you’ll want to go beyond your laptop. Ray has built-in support for launching clusters on AWS, GCP, and Azure. You can write a config file and fire up a multi-node cluster without learning Kubernetes or writing YAML for days.
-3.png)
The Tradeoffs (Because Every Tool Has Some)
No tool is perfect, and Ray’s no exception. Here are a few things to keep in mind:
- Learning Curve for Advanced Stuff: While Ray’s basics are easy, some of the deeper features—like cluster autoscaling or actor fault-tolerance—can get complex fast.
- Monitoring and Debugging at Scale: The built-in dashboard helps a lot, but once you’re running jobs across 50 machines, you’ll still want solid logging and observability tools.
- Cluster Management Overhead: If you don’t use Ray’s built-in cloud tooling, you might need to set up your own VMs, which brings back some of the usual headaches.
Final Thoughts: Is Ray For You?
If your Python code is hitting performance limits, and you're tired of reinventing the wheel every time you try to parallelize or scale things, Ray’s probably worth a look. It doesn’t force you to become a distributed systems expert, but it does let you act like one—with way less pain.
You don’t need a massive team or months of infra planning. Whether you’re a solo developer experimenting with ML models or a small startup trying to crunch logs overnight, Ray lets you stay focused on your code—not on how to make it run on five machines at once.
It's a toolbox for folks who'd rather do than tune, and in that sense, it’s a breath of fresh air in the Python world.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us