



A Full Guide to Small Language Models (SLMs)


A Small Language Model (SLM) is a language model designed to perform a limited set of well-defined language tasks efficiently. Instead of aiming for broad language understanding, SLMs are trained and sized for specific functions such as classification, information extraction, summarization, or intent detection, where predictable and consistent outputs are required.
This challenge is emerging alongside rapid growth in AI investment. According to IDC, global spending on AI-centric systems is expected to exceed $300 billion by 2026, increasing pressure to adopt more efficient model approaches.
Small Language Models (SLMs) address this gap by focusing on specific language tasks with lower compute requirements and simpler deployment. They are built for scenarios where precision, cost control, and operational practicality matter more than broad, open-ended capabilities.
To understand why Small Language Models behave differently in production environments, it helps to look at how they are structured and optimized.
How Small Language Models Are Structured
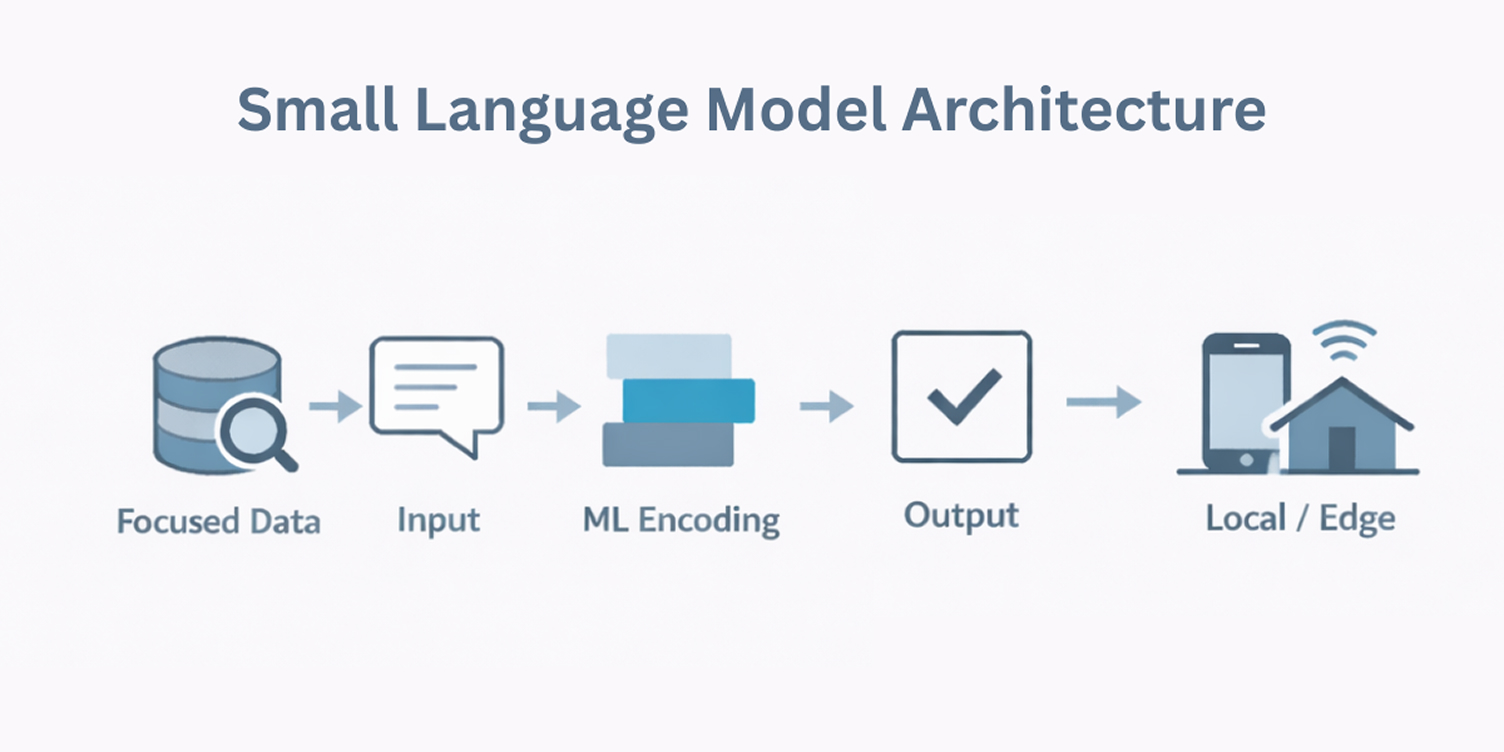
Small Language Models are built around the idea that most language tasks do not require a broad, general-purpose system. Instead, they are designed to handle a narrower set of responsibilities efficiently, with fewer resources and tighter control over behavior.
Rather than handling open-ended prompts, SLMs focus on a narrow set of inputs and outputs. This task-first design allows them to deliver reliable results without the scale or infrastructure required by larger models.
What this looks like in practice:
Smaller model size
SLMs are designed from the start to stay compact, with model size aligned to a specific task or domain. This intentional sizing reduces latency and makes performance easier to manage when workloads are predictable and repeated.
Retains useful language behavior
Many SLMs are developed by learning from the behavior of larger models during training. This allows them to capture practical language patterns through ML encoding, without inheriting the runtime cost of large systems.
Removing unnecessary complexity
SLMs are optimized to eliminate parts of the model that add little value for the target task. This allows them to run faster while maintaining acceptable accuracy for specific use cases.
Using focused, high-quality data
Rather than keeping every possible capability, SLMs are refined to remove parts of the model that add little value for the intended use case. This results in faster execution and more stable behavior in production environments.
Designed to run closer to the user
Because of their lower resource needs, SLMs can operate on local systems or edge devices. This supports scenarios where offline access, data control, or reduced infrastructure dependency is important.
Together, these choices explain how Small Language Models work in practice. They trade breadth for efficiency, making them well suited for language tasks that are clearly defined and repeated within real systems.
Why Small Language Models Are Used in Production AI
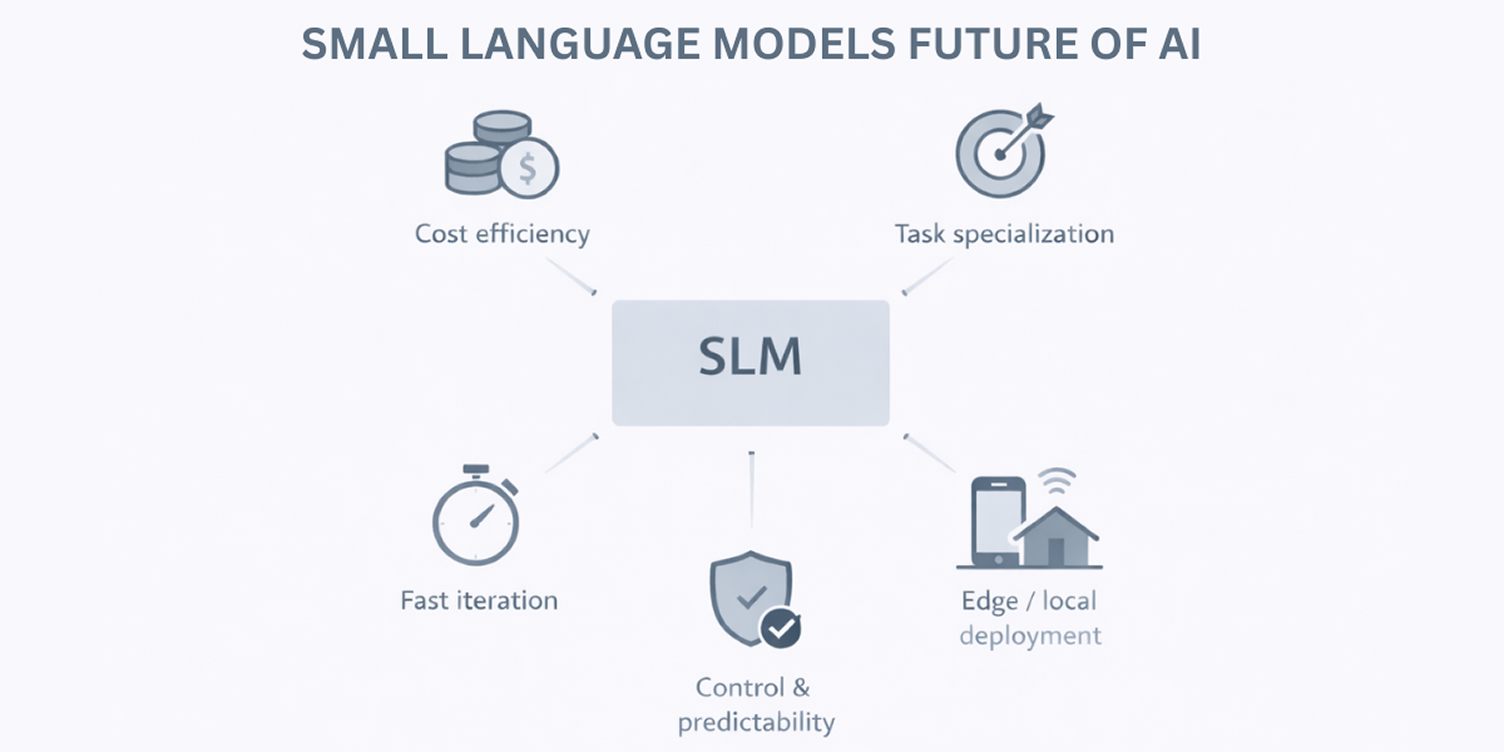
Decisions around language models are increasingly shaped by cost, control, and operational fit. This section explains why Small Language Models are becoming the preferred choice for most real-world language tasks, while larger models are reserved for narrower, high-complexity scenarios.
Several practical forces are driving this shift.
Economics is forcing right-sized models
Training and running very large language models has become difficult to justify for everyday workloads. According to a Global Survey on AI adoption, more than 50% of organizations cite cost and infrastructure requirements as major barriers to scaling AI initiatives.
Smaller models reduce both training and inference costs, making it feasible to apply language AI across more workflows rather than limiting it to a few high-value use cases.
Specialization now beats general intelligence
In most applied settings, language tasks are domain-specific. When trained on focused data such as support tickets, legal text, or internal documentation, Small Language Models often perform more consistently than general-purpose models on those exact tasks. Their narrower scope reduces unexpected outputs in structured use cases.
Faster iteration cycles improve system fit
Smaller models can be retrained or adjusted more quickly as requirements change, which is critical in systems where language behavior evolves with product logic. Their limited scope and lower training overhead allow teams to iterate safely and refine outputs without long retraining cycles. This keeps language systems aligned with real usage over time, especially when using efficient model adaptation techniques.
Edge and local deployment are becoming unavoidable
As language capabilities move closer to devices and internal platforms, models must operate reliably outside centralized data centers. Small Language Models support this shift by running in environments with tighter compute or connectivity constraints.
Control and predictability matter more than breadth
In many enterprise contexts, predictable behavior outweighs open-ended reasoning. Smaller models operate within clearer boundaries, making them easier to govern, audit, and align with internal policies, especially when handling sensitive or regulated data in modern gen AI design.
Taken together, these factors explain why Small Language Models are increasingly viewed as the practical foundation for applied language AI. They align with how language systems are actually used frequently, repeatedly, and under real operational constraints.
Why Model Size Becomes a Practical Decision
Large Language Models (LLMs) are pretrained on broad text corpora and designed to handle a wide range of language tasks without upfront task specialization. Their generalization capability makes them useful in exploratory or open-ended workflows where flexibility and cross-domain reasoning are priorities.
In practice, factors such as latency requirements, infrastructure limits, cost at scale, and deployment environment begin to influence model selection. These constraints often surface only after language models are integrated into live workflows, where predictability and operational stability matter.
This is where differences in model size become meaningful. Understanding how smaller and larger language models behave under production constraints helps teams make informed architectural decisions.
The following comparison shows how model size affects key operational characteristics in production environments.
Small Language Models vs Large Language Models
For most production language workloads, Small Language Models offer a more practical balance of efficiency, control, and reliability. Large Language Models remain valuable for complex or open-ended tasks, but they are not the default choice in everyday systems.
Model Selection Guide

Selecting the right language model depends less on model size alone and more on how well the model aligns with the task scope, system constraints, and operational goals of an application.
The following considerations can help guide model selection in practical environments.
Choose a Small Language Model (SLM) when:
- The task is well-defined and repeatable (e.g., classification, summarization, extraction).
- Low-latency inference is required for user-facing or real-time systems.
- Deployment needs include edge, on-premise, or private infrastructure.
- Predictable and consistent outputs are more important than creative or exploratory responses.
- Cost efficiency and resource usage are critical at scale.
Choose a Large Language Model (LLM) when:
- The application requires broad language understanding across multiple domains.
- Tasks involve open-ended reasoning or generation with variable inputs.
- Flexibility is prioritized over optimization in early-stage development.
- Centralized cloud deployment is acceptable for the workload.
Hybrid Approaches in Practice
In many production systems, SLMs and LLMs are used together. A common pattern is to:
- Use SLMs for high-volume, structured tasks
- Escalate to LLMs for complex or ambiguous cases
This approach balances efficiency with capability while keeping operational costs under control.
As language models are integrated into production systems, technical factors such as latency, energy usage, and deployment flexibility begin to directly influence architectural decisions. These considerations often determine whether a model can be embedded into real-time workflows, deployed closer to users, or operated within infrastructure constraints.
In practice, these technical implications shape how language models are applied across different environments. The following use cases illustrate how Small Language Models are used in scenarios where efficiency, predictability, and deployment control are critical.
Common Use Cases of Small Language Models
Small Language Models are typically applied where language processing needs to happen frequently, quickly, and within clear boundaries. These use cases reflect how SLMs are actually deployed today across products, internal systems, and device-level applications.
On-device and offline language processing
SLMs are well-suited for environments where constant internet access is not guaranteed. They are used to power features such as voice commands, text translation, and local automation directly on devices like smartphones, laptops, and embedded systems.
Running models locally reduces dependency on cloud infrastructure and keeps sensitive data on the device.
High-volume customer support workflows
Many organizations use SLMs to handle routine support interactions, including account help, order updates, and common product questions. These models are effective for Tier-1 queries where responses follow known patterns, enabling fast replies while keeping operational costs predictable.
Industry-specific language assistants
SLMs are increasingly embedded into tools tailored for specific sectors, where domain familiarity matters more than broad language ability.
- Healthcare: Summarizing clinical notes, organizing patient records, and supporting documentation tasks while keeping data within controlled environments.
- Finance and legal: Reviewing documents for specific clauses, supporting compliance checks, and analyzing structured financial text.
- Manufacturing and operations: Standardizing logs, processing machine reports, and supporting maintenance workflows with consistent language outputs.
Developer and engineering support tools
Smaller language models are often used locally to assist with coding-related tasks such as generating boilerplate code, analyzing logs, or creating test cases. Their ability to run in controlled environments makes them suitable for teams working with sensitive codebases.
Workflow automation and task routing
In larger systems, SLMs frequently act as specialized components that handle tasks like intent detection, text classification, or data extraction. These models process routine steps efficiently and pass only complex cases to more capable systems when needed.
Data preparation and analysis support
SLMs are commonly used to clean, structure, and analyze text data. This includes extracting key fields from documents, detecting sentiment in feedback, or preparing unstructured text for downstream analytics and reporting.
Top Small Language Models in 2026
Industries Using Small Language Models

Beyond individual implementations, Small Language Models are now being adopted across a range of industries with varying operational requirements. This section matters because it shows how SLMs fit into real industry environments without the overhead of large, general-purpose models.
Healthcare and clinical operations
SLMs are used inside healthcare systems to support documentation-heavy processes. This includes structuring clinician notes, organizing patient records, and assisting with transcription review. Their limited scope and controlled deployment make them suitable for environments with strict data-handling requirements.
Financial services and compliance-driven sectors
In finance and legal environments, SLMs are commonly applied to review structured documents such as contracts, policies, and regulatory filings. They help flag predefined clauses, normalize language across documents, and support compliance workflows that rely on consistent interpretation rather than open-ended reasoning.
Manufacturing, logistics, and operations
Operational teams use SLMs to process machine reports, incident logs, and standardized operational data. These models help convert unstructured text into structured inputs that downstream systems can act on, supporting monitoring and maintenance processes.
Retail and customer-facing platforms
Retail organizations embed SLMs into internal systems that manage product catalogs, customer feedback, and support workflows. Rather than powering conversational assistants, these models often operate behind the scenes, routing requests, tagging content, or analyzing trends at scale.
Software and enterprise IT
Within software products and internal tools, SLMs support tasks such as issue triaging, documentation analysis, configuration validation, and system monitoring. Their role is often invisible to end users but critical to maintaining consistent, responsive workflows.
Education and research environments
Educational platforms and research tools use SLMs for content organization, summarization, and structured analysis within defined subject areas. Smaller models allow these systems to operate efficiently without the overhead of large-scale infrastructure.
Across these industries, Small Language Models are typically introduced as part of existing systems rather than as standalone AI layers. They are used to handle specific language responsibilities within larger workflows, which allows teams to add language intelligence without changing how their systems are structured or operated.
Misconceptions About Small Language Models
After reviewing how Small Language Models are applied across industries, it’s worth addressing a few common misconceptions that often arise when comparing them with larger language models.
Task importance
Small Language Models are often assumed to be suitable only for minor tasks. In production systems, they frequently handle high-frequency language operations such as classification, routing, validation, and structured extraction. These tasks sit inside critical workflows and require consistent, predictable output rather than broad generative capability.
Reliability at scale
It is commonly assumed that smaller models struggle as request volume grows. In practice, reliability depends more on task alignment than model size. When inputs are constrained and outputs are clearly defined, Small Language Models can maintain stable behavior across large volumes of requests.
Cost-driven choice
Small Language Models are sometimes viewed as a compromise chosen mainly to reduce infrastructure cost. While efficiency matters, teams often prioritize latency control, simpler deployment, and easier monitoring when selecting SLMs for production workloads.
System flexibility
There is a perception that using Small Language Models limits future system evolution. In many architectures, SLMs handle well-defined language functions by default, while larger models are introduced only for scenarios that require broader reasoning, allowing systems to evolve incrementally.
Long-term viability
Small Language Models are sometimes treated as a temporary solution. Their continued use reflects a broader shift toward selecting models based on workload characteristics and system constraints, rather than defaulting to maximum model size.
Final Thoughts
Small Language Models have moved from being viewed as lightweight alternatives to large models to being used as intentional components in production systems. Their adoption is driven less by experimentation and more by the need to support language tasks that are scoped, repeatable, and embedded within existing software workflows.
Across practical deployments, SLMs are chosen not for their generality, but for their predictable behavior, manageable resource footprint, and ease of integration. These characteristics make them suitable for language functionality that must operate reliably at scale, under defined constraints, and alongside other system services.
The broader takeaway from this guide is that language model selection is increasingly shaped by system design considerations rather than model size alone. In this context, Small Language Models represent a stable and deliberate choice for teams building production-grade language capabilities where control and efficiency matter.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us