



Upstream vs Downstream in Microservices: The Complete Guide to Service Dependencies



Upstream service is a service that provides data or functionality to other services. It acts as the source in the data flow. For example, a UserService that supplies user records to an OrderService is upstream.
Downstream service is a service that consumes data or functionality from another service. It acts as the receiver in the data flow. For example, the OrderService that calls UserService to fetch user data is downstream.
Data and requests typically flow from upstream to downstream. The direction can sometimes feel confusing, depending on whether you are thinking in terms of control flow or data flow.
In a simple three-service chain, it looks like the UserService acts as the upstream service because it provides data, the OrderService sits in the middle and functions as both upstream and downstream depending on the interaction, and the NotificationService acts as the downstream service because it consumes data.
Understanding Upstream and Downstream Services
In real-world systems, upstream and downstream are not just labels; they describe how services relate to each other. The confusion begins because different teams interpret this relationship in different ways. What looks like a simple directional concept quickly becomes ambiguous when you shift perspective from how data moves to how requests are made.
Two Ways to Understand the Same Relationship
At its core, the confusion comes from viewing the same service interaction through two lenses: data flow and request flow. Both describe the same connection between services, but they define direction differently, which leads to inconsistent terminology across teams.
In the data-flow perspective, UserService is upstream because it's the source of user data. In the request-flow perspective, OrderService is upstream because it's the one making the call. The same two services, two different labels depending on who you ask.
How the Same Services Change Roles Based on Perspective
To understand this better, consider how two services interact and how their relationship shifts depending on how you look at it.
For instance, where an OrderService needs user data and calls a UserService. From a data flow perspective, the UserService sits upstream because it is the source of the data, while the OrderService is downstream because it consumes that data.
However, if you switch to a request flow perspective, the relationship appears reversed. The OrderService becomes upstream because it initiates the call, and the UserService becomes downstream because it responds to it.
This is where most teams run into trouble. The relationship between services has not changed, but the interpretation of direction has. Without a shared understanding, conversations become inconsistent, and decisions can be misaligned.
To avoid ongoing confusion, it is important to define how your team understands the relationship between services and use that definition consistently. In most microservices architectures, the data-flow perspective is more intuitive and useful. It clearly represents dependencies, where one service provides functionality and another relies on it.
Upstream vs Downstream in Microservices
Understanding the basic definition is useful, but it’s not enough when you’re designing real systems. In microservices architecture, upstream and downstream relationships directly affect how services depend on each other, how failures spread, and how safely you can deploy changes. This section goes beyond simple definitions and breaks down how these roles impact.
One point that trips up engineers: most real microservices are both upstream and downstream simultaneously. The OrderService is downstream from UserService and InventoryService, and upstream to PaymentService and NotificationService. Your architecture diagram isn't a line — it's a graph.
Upstream and Downstream in DDD Context Mapping
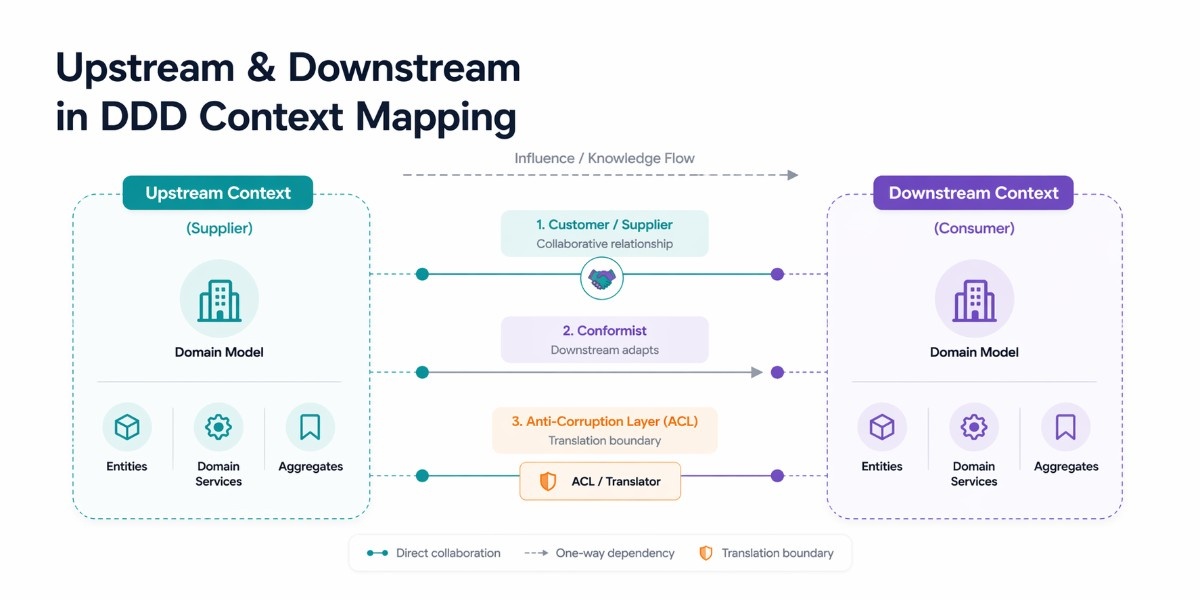
In Domain-Driven Design (DDD), upstream and downstream have a precise technical meaning that goes beyond just data flow. They describe the team relationship and power dynamic between two bounded contexts. Understanding this is crucial if you're designing service boundaries based on DDD principles.
At the core of this idea is the concept of a bounded context. A bounded context is a logical boundary around a domain model. When two bounded contexts interact, one is typically upstream (it sets the rules, the model, the API, the contract) and the other is downstream (it adapts to whatever the upstream provides).
The upstream team doesn't need to care about what the downstream team does with the data. The downstream team, on the other hand, has to deal with whatever the upstream gives them.
This is where the meaning of upstream and downstream becomes more nuanced. Instead of simply describing which service calls another, these terms describe which domain influences another.
Key Integration Patterns in DDD
DDD introduces specific patterns to manage upstream and downstream relationships effectively. These patterns define how tightly or loosely systems should be coupled.
Customer / Supplier (collaborative relationship)
Customer / Supplier Collaborative relationship. The upstream (Supplier) and downstream (Customer) teams actively collaborate. The downstream team's requirements influence the upstream team's roadmap.
This is the healthiest pattern and works well when both teams are in the same organization and have regular communication. Example: a PaymentService (supplier) exposes endpoints that the OrderServicethe OrderService
Conformist (downstream submits to upstream)
The downstream team has no negotiating power with the upstream team. They simply conform to whatever model the upstream publishes, even if it's inconvenient.
This happens often with third-party APIs or internal legacy systems where the upstream team has no incentive to accommodate downstream needs. Example: an internal reporting service consuming data from an ERP system it cannot influence.
Anti-Corruption Layer (ACL) (Protective translation layer)
When the upstream model is messy, legacy, or simply incompatible with your domain model, the downstream team builds a translation layer that converts the upstream's model into their own clean domain model.
The ACL sits between the two services and prevents the upstream's complexity from leaking into your codebase. This is the pattern to use when you're integrating with a legacy system or a third-party API.
Anti-Corruption Layer in Practice
// Upstream (legacy CRM) returns a messy model
interface LegacyCRMCustomer {
cust_id: string;
cust_nm_first: string;
cust_nm_last: string;
email_addr_1: string;
active_flag: 0 | 1;
}
// Your clean downstream domain model
interface Customer {
id: string;
name: { first: string; last: string };
email: string;
isActive: boolean;
}
// The Anti-Corruption Layer — translates between the two worlds
class CustomerACL {
fromLegacyCRM(raw: LegacyCRMCustomer): Customer {
return {
id: raw.cust_id,
name: {
first: raw.cust_nm_first,
last: raw.cust_nm_last,
},
email: raw.email_addr_1,
isActive: raw.active_flag === 1,
};
}
}
// Your service only ever sees the clean Customer model
class OrderService {
constructor(
private crmClient: LegacyCRMClient,
private acl: CustomerACL
) {}
async getCustomerForOrder(customerId: string): Promise<Customer> {
const rawData = await this.crmClient.fetchCustomer(customerId);
return this.acl.fromLegacyCRM(rawData); // Clean model, no legacy leakage
}
}How Upstream and Downstream Services Communicate in Microservices
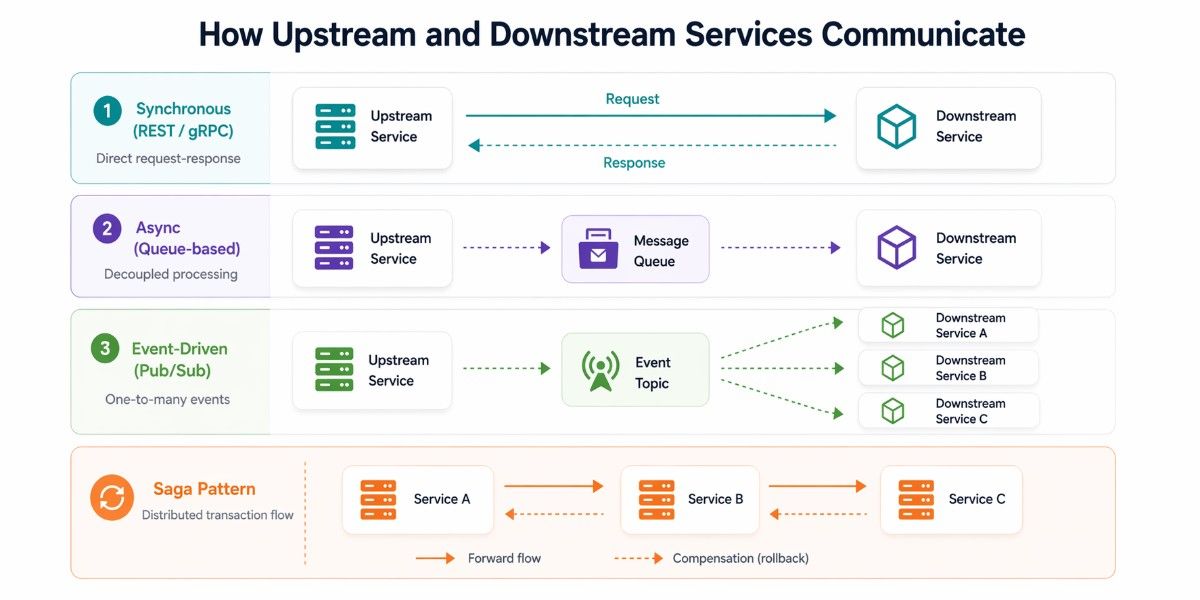
Upstream and downstream relationships become truly meaningful when you look at how services communicate. The pattern you choose, synchronous, asynchronous, or orchestrated, directly affects latency, reliability, and how failures propagate across your system. In practice, most microservices architectures use a mix of these patterns, depending on the use case and performance requirements.
Synchronous Communication (REST / gRPC)
In synchronous communication, an upstream service directly calls a downstream service and waits for a response. This is typically done using REST APIs or high-performance protocols like gRPC.
This pattern is simple and intuitive, but it introduces a critical constraint: latency adds up quickly across service chains.
If your total response time budget is 200ms and your service makes three sequential upstream calls, the math becomes tight:
Total budget = 200ms
Service A calls:
- Service B → 70ms
- Service C → 60ms
- Service D → 80ms
Total = 210ms ❌ (budget exceeded)Each additional synchronous call increases response time and failure risk. If one downstream service slows down or fails, the entire chain is affected, and this is where communication and resilience patterns start to matter as much as the architecture itself. This is why synchronous communication works best for short, critical paths with strict latency control.
// ❌ Sequential — consumes full latency budget of all three upstream calls
const user = await fetchUser(userId);
const inventory = await fetchInventory(productId);
const price = await fetchPrice(productId);
// ✅ Parallel — total latency = max(80, 120, 90) = 120ms, not 290ms
const [user, inventory, price] = await Promise.all([
fetchUser(userId),
fetchInventory(productId),
fetchPrice(productId),
]);Asynchronous Communication (Message Queues)
The upstream service sends a message to a queue (Kafka, RabbitMQ, AWS SQS) and moves on. The downstream service picks it up and processes it at its own pace. This breaks the temporal coupling entirely; the upstream doesn't care if the downstream is slow, restarting, or even down temporarily.
This pattern shines for operations where an immediate response isn't needed: sending a confirmation email after an order, updating an analytics database, or triggering a report generation. It falls short when you need the result of an upstream call to continue your own logic.
Event-Driven Communication (Pub/Sub)
Rather than one upstream talking to one downstream, the upstream publishes an event to a topic. Multiple downstream services subscribe and react independently. This is the most decoupled pattern and the one that scales the best; the upstream doesn't know or care who is consuming its events.
// Upstream: OrderService publishes an event — doesn't know who listens
await kafka.publish('order.placed', {
orderId: order.id,
userId: order.userId,
totalAmount: order.total,
items: order.items,
timestamp: new Date().toISOString(),
});
// Downstream A: NotificationService subscribes independently
kafka.subscribe('order.placed', async (event) => {
await emailService.sendOrderConfirmation(event.userId, event.orderId);
});
// Downstream B: InventoryService also subscribes independently
kafka.subscribe('order.placed', async (event) => {
await inventoryService.reserveItems(event.items, event.orderId);
});
// Downstream C: AnalyticsService — doesn't affect order flow at all
kafka.subscribe('order.placed', async (event) => {
await analyticsDb.recordConversion(event);
});The Saga Pattern for Distributed Transactions
When a business operation spans multiple upstream and downstream services, you can't use a traditional database transaction.
The Saga pattern handles this by breaking the transaction into a sequence of local transactions, each publishing an event that triggers the next. If any step fails, compensating transactions run in reverse to undo the previous steps.
There are two Saga implementations: Choreography (services react to events, no central coordinator) and Orchestration (a central saga orchestrator tells each service what to do).
Choreography is more decoupled but harder to debug; orchestration is easier to trace but introduces a coordinator that can become a bottleneck.
Service Mesh
A service mesh like Istio or Linkerd sits between every upstream and downstream pair, handling retries, load balancing, mTLS encryption, and circuit breaking transparently, without touching application code.
Instead of each service implementing its own resilience logic, the sidecar proxy handles it. Envoy proxy (which powers Istio) is the dominant data-plane implementation in 2026.
DAPR (Distributed Application Runtime) is a newer option that provides similar capabilities as a sidecar, with the advantage of being infrastructure-agnostic; the same DAPR configuration works on Kubernetes, on AWS Lambda, or on bare metal.
SLA Calculation in Microservices and the Impact of Services
This is one of the most overlooked aspects of upstream and downstream relationships, and it usually becomes visible during SLA discussions or post-mortems. When your service makes synchronous calls to upstream services, its availability is no longer independent. Instead, it becomes tied to the reliability of every service it depends on. In simple terms, your SLA is only as strong as the weakest link in your dependency chain.
How SLA Cascading Works
This dependency can be understood through a simple idea: availability compounds across services rather than standing alone.
Atotal=A1×A2×A3×⋯×An
For example, if an OrderService with 99.9% availability depends on a UserService (99.9%) and a PaymentService (99.5%) through synchronous calls, the combined availability drops to around 99.3%. Even though each service appears reliable individually, its combined effect reduces the overall system reliability.
At first glance, the difference between 99.9% and 99.3% may seem small, but in practice it is significant. Over a year, 99.9% uptime allows for roughly 8 to 9 hours of downtime, while 99.3% results in more than 60 hours.
This gap becomes critical when SLAs are tied to business commitments. Without accounting for upstream dependencies, teams may unknowingly promise a level of reliability that the system cannot realistically achieve.
How Async Communication Changes the Equation
The situation improves when you introduce asynchronous communication. Instead of waiting for a direct response, a service can publish an event to systems like Apache Kafka.
In this model, downstream services process the event independently, which means their availability no longer directly impacts the upstream service. As a result, failures are isolated instead of cascading through the system, making the overall architecture more resilient.
Designing SLAs with Dependencies in Mind
Understanding this relationship should directly influence how SLAs are designed. Teams need to identify all synchronous upstream dependencies and evaluate their combined impact. If the resulting availability falls short of the target SLA, the system design must be adjusted.
This could involve reducing synchronous calls, introducing buffering or caching strategies, or setting realistic SLA expectations based on actual system behavior.
This perspective is equally important during incident analysis. When a failure occurs, the immediate reaction is often to focus on the affected service. However, the real issue often originates upstream and propagates through the system.
By tracing the dependency chain, teams can identify the root cause instead of just the visible symptom, leading to more effective fixes and better long-term reliability.
Handling Upstream Failures with Resilience Patterns in Microservices
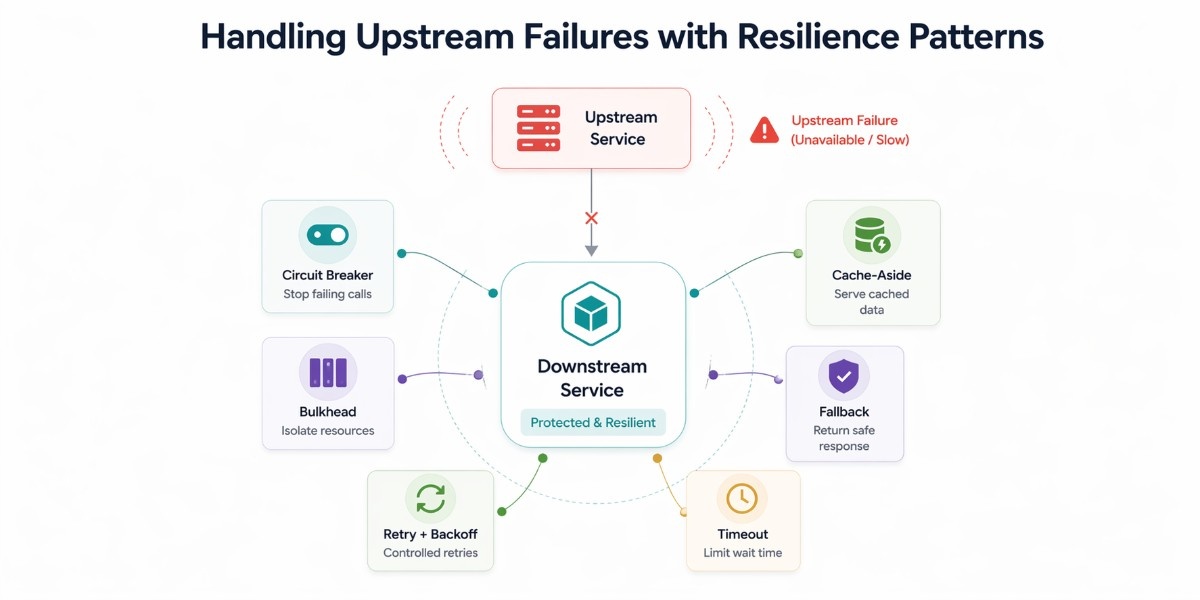
In a microservices system, failures rarely start where you see them. A downstream service depends on upstream services to complete its work, so when those upstream dependencies fail or slow down, the downstream must handle that situation deliberately. These patterns define how a downstream service should behave when its upstream fails, so that one issue does not turn into a system-wide outage.
Circuit Breaker
When an upstream service starts failing repeatedly, continuing to call it only increases latency and resource usage. A circuit breaker is a runtime protection mechanism implemented inside the downstream service (or via libraries/middleware) that temporarily stops calls to a failing upstream.
What this implementation does is track failures over time. Once failures cross a defined threshold, it “opens” the circuit and short-circuits future requests by returning a fallback instead of calling the upstream service.
Example (Node.js implementation):
class CircuitBreaker {
constructor(failureThreshold = 5, resetTimeout = 5000) {
this.failureCount = 0;
this.failureThreshold = failureThreshold;
this.state = "CLOSED";
this.resetTimeout = resetTimeout;
}
async call(fn, fallback) {
if (this.state === "OPEN") {
return fallback();
}
try {
const result = await fn();
this.failureCount = 0;
return result;
} catch (err) {
this.failureCount++;
if (this.failureCount >= this.failureThreshold) {
this.state = "OPEN";
setTimeout(() => (this.state = "HALF_OPEN"), this.resetTimeout);
}
return fallback();
}
}
}This code is not just a wrapper—it actively prevents repeated failures from hitting the upstream service, protecting both systems.
Bulkhead
If one upstream service becomes slow, it can consume all available threads or connections and impact unrelated features. The bulkhead pattern is a resource isolation strategy, typically implemented using separate connection pools or worker queues.
What this implementation does is ensure that each upstream dependency gets its own limited pool of resources, so failure in one does not affect others.
Example (Node.js using limited concurrency):
const pLimit = require("p-limit");
// Create separate pools
const paymentLimit = pLimit(5); // max 5 concurrent calls
async function callPaymentService() {
return paymentLimit(() => fetch("http://payment-service"));
}Here, even if the payment service becomes slow, it cannot exhaust all resources. Other upstream calls continue to function normally.
Retry with Backoff
Some upstream failures are temporary, such as network issues or brief spikes in load. The key rule: only apply retries to reads, never to writes, calling a payment gateway twice on failure is the kind of mistake this distinction exists to prevent.
Retry logic is an application-level strategy that attempts the same request again, but in a controlled way.
What this implementation does is retry failed requests with increasing delays, giving the upstream time to recover while avoiding overload.
Retry with Exponential Backoff and Jitter
async function withRetry<T>(
fn: () => Promise<T>,
maxAttempts = 4,
baseDelayMs = 100
): Promise<T> {
let lastError: Error;
for (let attempt = 0; attempt < maxAttempts; attempt++) {
try {
return await fn();
} catch (err) {
lastError = err as Error;
if (attempt < maxAttempts - 1) {
// Exponential backoff + jitter to avoid thundering herd
const delay =
baseDelayMs * Math.pow(2, attempt) +
Math.random() * 50;
await new Promise(r => setTimeout(r, delay));
}
}
}
throw lastError!;
}
// Usage — only retry idempotent upstream reads, never writes
const product = await withRetry(() =>
catalogService.getProduct(productId)
);Timeout
A slow upstream service can block your system just as much as a failing one. Timeouts are a critical control mechanism that defines how long the downstream service is willing to wait.
What this implementation does is enforce a strict time limit. If the upstream does not respond in time, the request is abandoned and handled as a failure.
Don't set a global timeout and call it done. Each upstream service has a different performance profile. Set timeouts individually, derived from each upstream's p99 latency plus a buffer.
// Per-upstream timeouts derived from observed p99 latency + 20% buffer
const TIMEOUTS = {
userService: 300, // p99: ~250ms
inventoryService: 500, // p99: ~420ms — slower due to DB joins
pricingService: 200, // p99: ~160ms — cached in Redis
paymentGateway: 5000, // p99: ~3500ms — external third-party
};
async function fetchWithTimeout<T>(
url: string,
timeoutMs: number
): Promise<T> {
const controller = new AbortController();
const timer = setTimeout(
() => controller.abort(),
timeoutMs
);
try {
const res = await fetch(url, { signal: controller.signal });
return await res.json();
} finally {
clearTimeout(timer);
}
}Fallback
When upstream services fail, the worst outcome is a complete error. Fallback strategies are business-level decisions implemented in the downstream service to return a usable response even when dependencies fail.
What this implementation does is provide alternative data, such as cached values or defaults, instead of failing the request.
Example (Node.js implementation):
async function getUserProfile(userId) {
try {
return await fetchUserFromService(userId);
} catch {
return cache.get(userId) || { name: "Guest", status: "limited" };
}
}This ensures the system continues to function, even if the response is slightly degraded.
Cache-Aside
Frequent calls to an upstream service can increase latency and make your system more vulnerable to failures. The cache-aside pattern is an application-level caching strategy where the downstream service first checks a cache before calling the upstream service.
What this implementation does is store upstream responses in a cache like Redis or Memcached. If the data is already available, the downstream service returns it immediately. If not, it fetches the data from the upstream service, stores it in the cache, and then returns the response.
This approach helps decouple the downstream from constant upstream dependency, reduces latency for frequently accessed data, and limits the blast radius when an upstream service is slow or temporarily unavailable.
Example (Node.js implementation):
async function getUser(userId) {
const cached = await redis.get(userId);
if (cached) {
return JSON.parse(cached);
}
const user = await fetchUserFromService(userId);
await redis.set(userId, JSON.stringify(user), "EX", 300); // cache for 5 mins
return user;
}In this flow, the upstream service is only called when necessary. During failures, the system can still serve stale or cached data, ensuring better availability and a smoother user experience.
How to Identify Upstream and Downstream Dependencies Using Observability
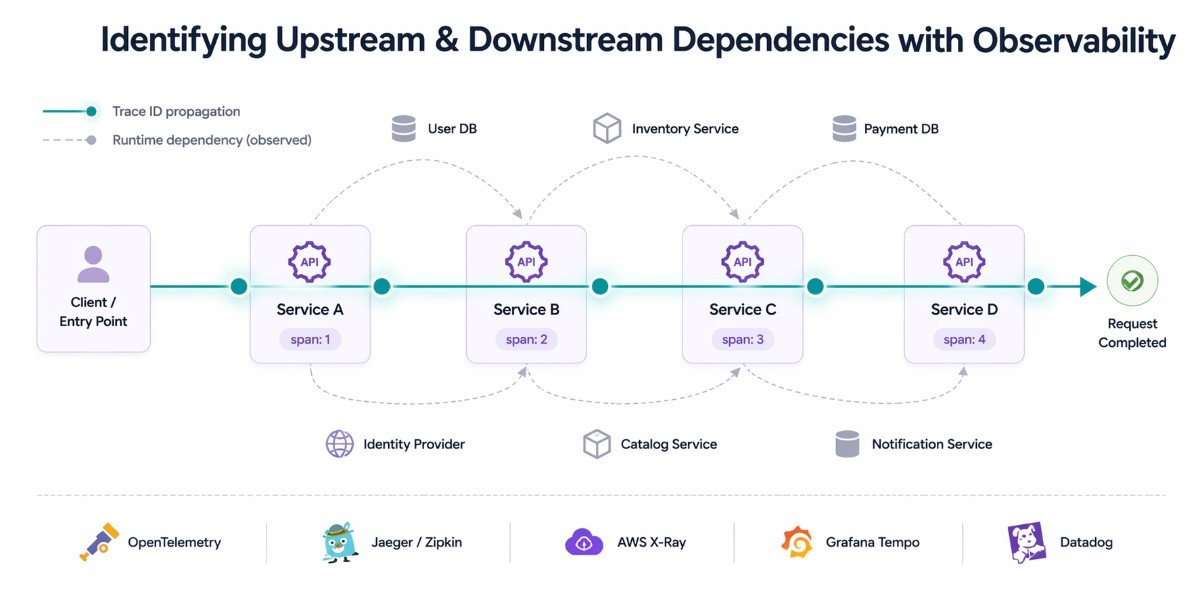
One of the hardest practical problems in a microservices system is not defining upstream and downstream; it’s discovering what actually depends on what in production. Once you have dozens of services, reading code or diagrams is no longer enough. Dependencies become dynamic, indirect, and sometimes undocumented. This is where observability, especially distributed tracing, becomes essential.
Distributed Tracing
Distributed tracing gives you a runtime view of service relationships. Every request is assigned a unique trace ID at the entry point, usually at the API Gateway, and that ID is propagated across every upstream call.
As the request flows through services, each service records its part of the journey as a span, capturing timing, metadata, and outcomes.
This creates a complete request tree that shows which services were called, in what order, how long each interaction took, and where failures or latency spikes occurred.
Instead of relying on assumptions or outdated diagrams, you get a precise and real-time view of how upstream and downstream services actually interact.
OpenTelemetry
OpenTelemetry has become the standard approach for instrumentation in modern systems. It provides a consistent way to generate traces, metrics, and logs across services without locking you into a specific vendor.
This means teams can instrument their services once and send the data to any observability backend, which is critical for long-term flexibility.
From an upstream and downstream perspective, OpenTelemetry ensures that trace context is propagated correctly across service boundaries.
Every upstream call carries the same trace ID, which allows you to reconstruct the full dependency chain. This makes it possible to understand not just individual service performance, but how services behave together as a system.
Jaeger
Jaeger is one of the most widely used open-source tracing systems, originally developed by Uber. It is particularly strong in visualizing request flows and providing clear insights into how services interact with each other.
One of its most valuable features is the ability to generate service dependency graphs directly from trace data. These graphs help teams understand real upstream and downstream relationships, which are often very different from what architecture diagrams suggest. This makes Jaeger especially useful for debugging and system analysis.
Zipkin
Zipkin is an earlier distributed tracing system that focuses on simplicity and ease of setup. It is often preferred in smaller environments or teams that want a lightweight solution without extensive configuration.
While it may not offer the same level of advanced features as newer tools, it still provides a clear view of request flows and service dependencies. For many teams, it serves as a good starting point for building observability into their systems.
AWS X-Ray
AWS X-Ray is designed for systems running on AWS and integrates deeply with the AWS ecosystem. It automatically traces requests across supported services and builds a visual map of service dependencies.
This makes it particularly useful for teams that are fully invested in AWS, as it reduces the effort required to instrument services and understand upstream/downstream relationships. The automatic mapping also helps quickly identify bottlenecks and failure points.
Grafana Tempo
Grafana Tempo focuses on scalable and cost-efficient trace storage. It is designed to work seamlessly with Grafana dashboards and integrates well with logs and metrics, creating a unified observability experience.
For larger systems, where trace volume can become significant, Tempo provides a practical way to store and query traces without high cost. This allows teams to maintain visibility into upstream and downstream interactions even at scale.
Datadog APM
Datadog APM provides a more comprehensive, commercial approach to observability. It includes automatic dependency mapping, detailed trace visualization, and built-in anomaly detection, which helps teams identify issues before they become critical.
From a practical standpoint, Datadog simplifies the process of understanding upstream and downstream relationships by presenting them in an intuitive and actionable way.
This is especially valuable for teams that want quick insights without managing multiple tools or building custom observability pipelines.
Instrumenting Upstream/Downstream Boundaries with OpenTelemetry
To make tracing useful, you need to instrument your services at upstream and downstream boundaries, meaning every external call should be traced. The following example shows how a service captures and propagates trace context when calling upstream services.
import { trace, context, propagation } from '@opentelemetry/api';
const tracer = trace.getTracer('order-service');
async function createOrder(userId: string, items: OrderItem[]) {
return tracer.startActiveSpan('order.create', async (span) => {
span.setAttributes({
'service.upstream': 'user-service,inventory-service',
'user.id': userId,
});
try {
const headers: Record<string, string> = {};
propagation.inject(context.active(), headers);
const [user, stock] = await Promise.all([
fetch(`http://user-service/users/${userId}`, { headers }),
fetch(`http://inventory-service/stock`, {
method: 'POST',
headers,
body: JSON.stringify({ items }),
}),
]);
span.setStatus({ code: 1 });
return await buildOrder(user, stock, items);
} catch (err) {
span.recordException(err as Error);
span.setStatus({ code: 2 });
throw err;
} finally {
span.end();
}
});
}This implementation creates a span for the operation, attaches metadata about upstream dependencies, and propagates the trace context through HTTP headers. As a result, every upstream call becomes part of a single trace, allowing you to visualize the entire dependency chain in tools like Jaeger or Grafana.
Generating Service Dependency Graphs
Once traces are collected, tools like Jaeger or Datadog automatically generate service dependency graphs. These graphs show how services interact in production, not just how they were designed.
They help identify hidden upstream dependencies, circular dependencies, and services that rely on too many upstream calls. Over time, this gives teams a clearer picture of the actual system structure.
Avoiding the “Blame the Upstream” Anti-Pattern
A common mistake in post-mortems is to blame the upstream service that failed. While upstream issues are often involved, this overlooks the responsibility of downstream services to handle failures properly.
A well-designed downstream service should remain stable even when upstream dependencies are slow or temporarily unavailable. Observability helps teams move beyond assumptions and focus on improving system resilience rather than assigning blame.
Observability turns upstream and downstream relationships into something visible and measurable. Instead of guessing dependencies, teams can see how their systems behave in real conditions. This leads to better design decisions, faster debugging, and more reliable systems overall.
API Gateway as the Boundary Between Services
The API Gateway is a central component in most microservices architectures, and its position in the upstream/downstream map is worth understanding precisely.
From an external client's perspective (mobile app, frontend, third-party), the API Gateway is the single upstream. The client doesn't know about UserService, OrderService, or any other internal service. It talks to the gateway, and the gateway handles everything.
From the perspective of your internal services, the API Gateway is a downstream caller that invokes their APIs. It sits between the external world and your service mesh.
What the API Gateway Does for Upstream/Downstream Management
Rate limiting
It protects upstream internal services from downstream abuse. If a client hammers your API, the gateway absorbs the load rather than passing it through to every internal service.
Authentication and authorization
The gateway layer removes the burden from individual upstream services. Each service doesn't need to implement its own auth the gateway verifies the token and passes a validated identity downstream.
Response aggregation (the Backend for Frontend pattern)
It lets the gateway call multiple upstream services and combine their responses into a single payload. The mobile app makes one request; the gateway fans out to UserService, OrderService, and RecommendationService in parallel and assembles the result.
Popular API Gateway
Kong (open-source, plugin-rich), AWS API Gateway (fully managed, integrates with Lambda), NGINX (high performance, configuration-based), Traefik (Kubernetes-native, automatic service discovery), and Envoy (typically deployed as a sidecar or in Istio).
Contract Testing Between Upstream and Downstream Services
Integration tests that spin up real instances of every upstream service are slow, brittle, and expensive. Contract testing is the practical alternative: the downstream service defines exactly what it needs from the upstream (the contract), and the upstream verifies it can satisfy that contract, without either side needing the other to be running.
How Consumer-Driven Contract Testing Works
Pact is the most widely used tool for this. Here's the flow:
1. Consumer (downstream) writes a test
The OrderService writes a test that defines exactly what response it expects from UserService. Pact records this as a "pact file", the contract.
2. Contract is published to a broker
The pact file is published to Pact Broker (or PactFlow). The upstream UserService team can now see exactly what downstream services expect from them.
3. Provider (upstream) runs verification
UserService runs a verification test against the pact file. If its actual responses match the contract, the test passes. If a new code change would break the contract, the test fails before deployment.
4. Can I deploy? Check runs in CI/CD
Before any upstream deployment, a "can I deploy?" check verifies that the new version still satisfies all downstream contracts. Breaking changes are caught in the pipeline, not in production.
import { PactV3, MatchersV3 } from '@pact-foundation/pact';
const { like, string, integer } = MatchersV3;
const provider = new PactV3({
consumer: 'OrderService',
provider: 'UserService',
dir: './pacts',
});
describe('OrderService → UserService contract', () => {
it('gets user details for order creation', () => {
return provider
.given('user 42 exists and is active')
.uponReceiving('a request for user 42')
.withRequest({ method: 'GET', path: '/users/42' })
.willRespondWith({
status: 200,
body: like({ // 'like' means shape matches, not exact value
id: integer(),
name: string(),
email: string(),
isActive: true,
}),
})
.executeTest(async (mockProvider) => {
const client = new UserServiceClient(mockProvider.url);
const user = await client.getUser('42');
expect(user.isActive).toBe(true);
});
});
});Schema Registries for Event-Driven Contracts
For event-driven upstream/downstream relationships (Kafka, RabbitMQ), Pact works, but schema registries are often a better fit. Confluent Schema Registry stores the Avro, Protobuf, or JSON Schema of every event your upstream publishes.
Downstream consumers validate incoming events against the schema at runtime. If an upstream team changes the event schema in a breaking way, the registry detects the incompatibility before the change reaches consumers.
.svg&w=256&q=75)
Practical Examples of Upstream and Downstream in Real Systems
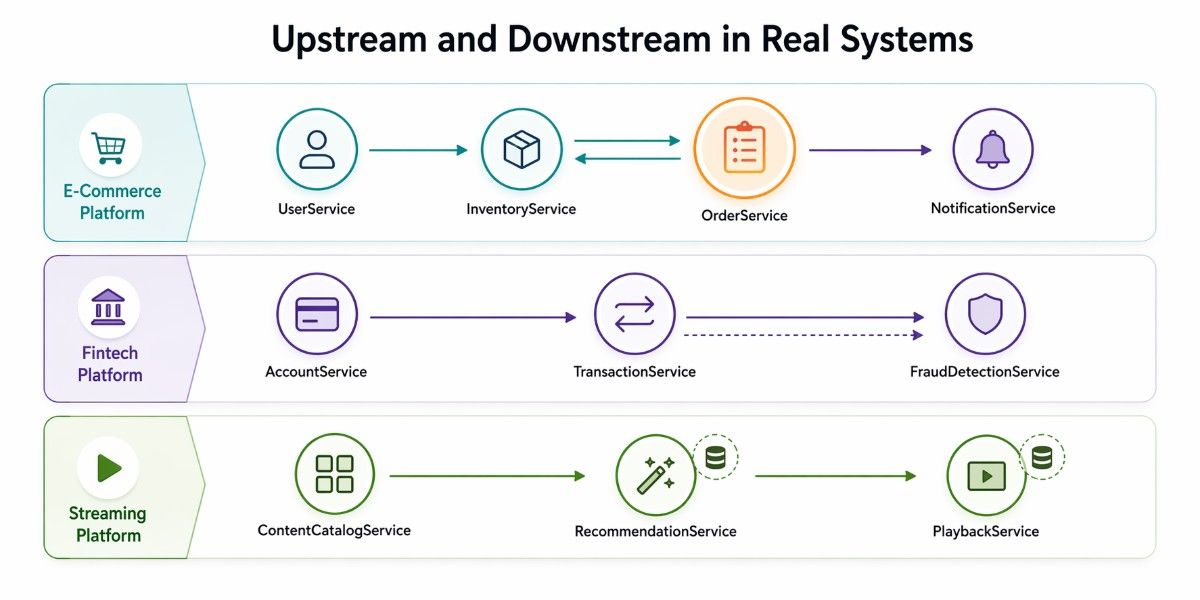
Understanding upstream and downstream becomes much clearer when you see how these relationships work in real systems. In practice, services rarely sit in isolation.
Most of them are part of a chain where they are upstream to some services and downstream to others at the same time. The following walkthroughs show how these relationships operate across different domains and how failures propagate through the system.
E-Commerce Platform
UserService (pure upstream)
Provides user authentication and profile data to every other service. No upstream dependencies of its own. Its SLA ceiling applies to every downstream that calls it synchronously.
Changes to its API require notifying all downstream teams. This service should be the most stable, most well-documented, and most heavily monitored service in the system.
InventoryService (both)
Upstream to OrderService (provides stock availability) and downstream to a SupplierService or WarehouseService that feeds it restocking data. When designing its SLA, account for both its upstream dependencies and the downstream services that depend on it.
OrderService (both)
Downstream to UserService and InventoryService, upstream to PaymentService, ShippingService, and NotificationService. This is the most complex service from a dependency management perspective.
A failure here has a maximum blast radius, which is why understanding the full service structure of an e-commerce system helps clarify where these boundaries need the most attention. It should implement circuit breakers on all upstream calls, and downstream services should handle their failures gracefully.
NotificationService (pure downstream)
Consumes events from multiple upstream services. Its failure doesn't affect order placement; it's a non-critical consumer. This is the right candidate for full async, event-driven integration. If it's down, messages queue up in Kafka and are processed when it recovers.
Fintech Platform
AccountService
It is the foundational upstream. Every other service needs account data. Its availability is critical; if it goes down, users can't log in, can't transact, can't do anything. This service warrants a higher SLA target than everything else and should have read replicas to protect against overload.
TransactionService
It sits in the middle. It reads from AccountService (upstream) and writes to both FraudDetectionService and ComplianceReportingService (downstream).
Here, async is the right choice for downstream publishing; the transaction completes immediately, and fraud analysis runs asynchronously. If fraud is detected, a compensating event fires to reverse the transaction.
FraudDetectionService
This service is a pure downstream consumer. It analyzes transaction patterns using ML models and publishes fraud signals. It has no upstream services that care about its output in real time.
The key design choice here: if fraud detection is slow, it should never block the transaction itself. Events decouple this relationship perfectly.
Streaming Platform
ContentCatalogService
ContentCatalog is the upstream anchor. It provides metadata about every piece of content on the platform. Latency here directly impacts startup time for every downstream service.
Heavy caching (Redis, CDN) is critical. Any content metadata change should be published as an event so downstream caches can invalidate correctly.
RecommendationService
It is a fascinating middle service: downstream from both ContentCatalogService and UserPreferenceService, upstream to the frontend APIs and client apps. It runs ML inference, which can be slow.
This is a candidate for the Cache-Aside pattern, precompute recommendations periodically, and serve from cache rather than running inference on every request.
PlaybackService
This is the performance-critical downstream. When a user presses play, every upstream millisecond counts. This service should cache content metadata aggressively, use circuit breakers on all upstream calls, and have well-tested fallback paths (serve the last known good metadata if ContentCatalogService is slow).
Key Takeaways
Upstream services provide data; downstream services consume it. The relationship is relative; most services are both simultaneously. Teams often use "upstream" to mean opposite things. Agree on a definition and document it in an ADR before using these terms in architecture discussions.
In DDD, upstream/downstream describes team power dynamics, not just data flow. The Anti-Corruption Layer protects downstream services from upstream model pollution. Synchronous upstream dependencies cap your SLA: composite availability = product of all individual availabilities. Async decoupling breaks this chain.
Downstream services own their own resilience: circuit breakers, fallbacks, timeouts, and retries are the downstream team's responsibility, not the upstream's. OpenTelemetry + Jaeger/Grafana Tempo gives you a real-time view of upstream/downstream relationships that no architecture diagram can match.
Consumer-driven contract testing (Pact) catches upstream breaking changes before they reach production. It's the most practical solution to API compatibility at scale.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us