



List Of Cloud-Native Architecture Patterns in Modern Systems



Cloud-native architecture refers to the method of developing software that is specifically designed to run on clouds, where an application is made of autonomous services, using automated pipelines, and at scale.
The approach presupposes regular change, distribution, and failure instead of long-life servers or tightly bound components, which is why architectural choices are central to the health of a system.
Based on the findings of the Cloud Native Computing Foundation (CNCF) Annual Cloud Native Survey, 82 percent of organizations operate Kubernetes in production, which confirms that cloud-native systems become mainstream, and architectural complexity has continued to be a challenge.
This breach demonstrates that large-scale implementation does not necessarily result in well-designed systems.
The page below is intended to be a reference point in understanding the patterns of cloud-native architecture.
It presents the fundamental patterns, the architectural issues that they are intended to solve, and a general usage in cloud-native systems, providing the reader with a good framework by which they can think about pattern-based design decisions.
What Forces Shape Cloud-Native Architecture
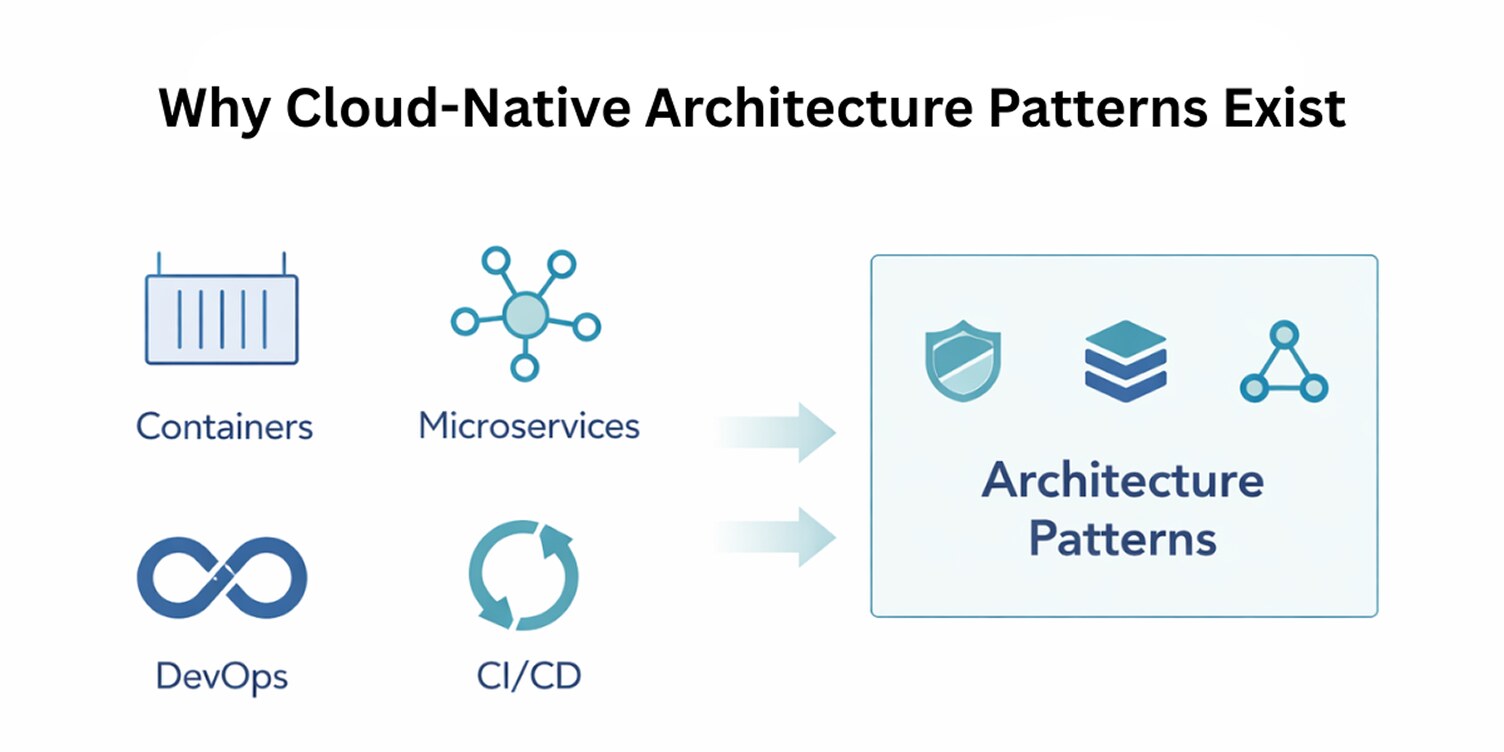
Cloud-native architecture refers to the state of the development and operation of modern applications, where the emphasis of the applications created is placed on building cloud environments instead of changing traditional systems to support cloud infrastructure.
In this context, containers, microservices, DevOps practices, and CI/CD pipelines serve as the forces determining the behavior of the system.
Containers
They render application instances disposable and replaceable and mandate architectures that presuppose restarting and redeploying as default, a transformation that is strongly associated with the way containerization transforms application deployment.
Microservices
Microservices bring distinct service definitions and autonomous change cycles that create greater coordination issues with respect to communication, data ownership, and transactions, resolved via typical microservices design patterns.
DevOps and CI/CD
They make the frequency of a system change shorter, so it cannot have delicate designs or human operators.
The reaction to these conditions is the use of cloud-native architecture patterns. They are there to cope with the design issues that these forces have introduced over and over again, offering known methods of how to organize services, deal with interactions, and deal with failure.
Such trends are important as they will transform repeated architecture issues into thoughtful, well-informed architectural decisions that will enable teams to create cloud-native systems, which are readable and maintainable as they become increasingly complex.
Common Cloud-Native Architecture Patterns Explained
Designing cloud-native systems ultimately comes down to a series of recurring architectural choices. When services are deployed independently and change frequently, the same architectural trade-offs surface across most cloud-native systems.
The patterns below capture those decisions in a structured form. Each pattern highlights a specific way architects address service boundaries, communication paths, data ownership, or failure behavior in cloud-native systems.
Sidecar Pattern
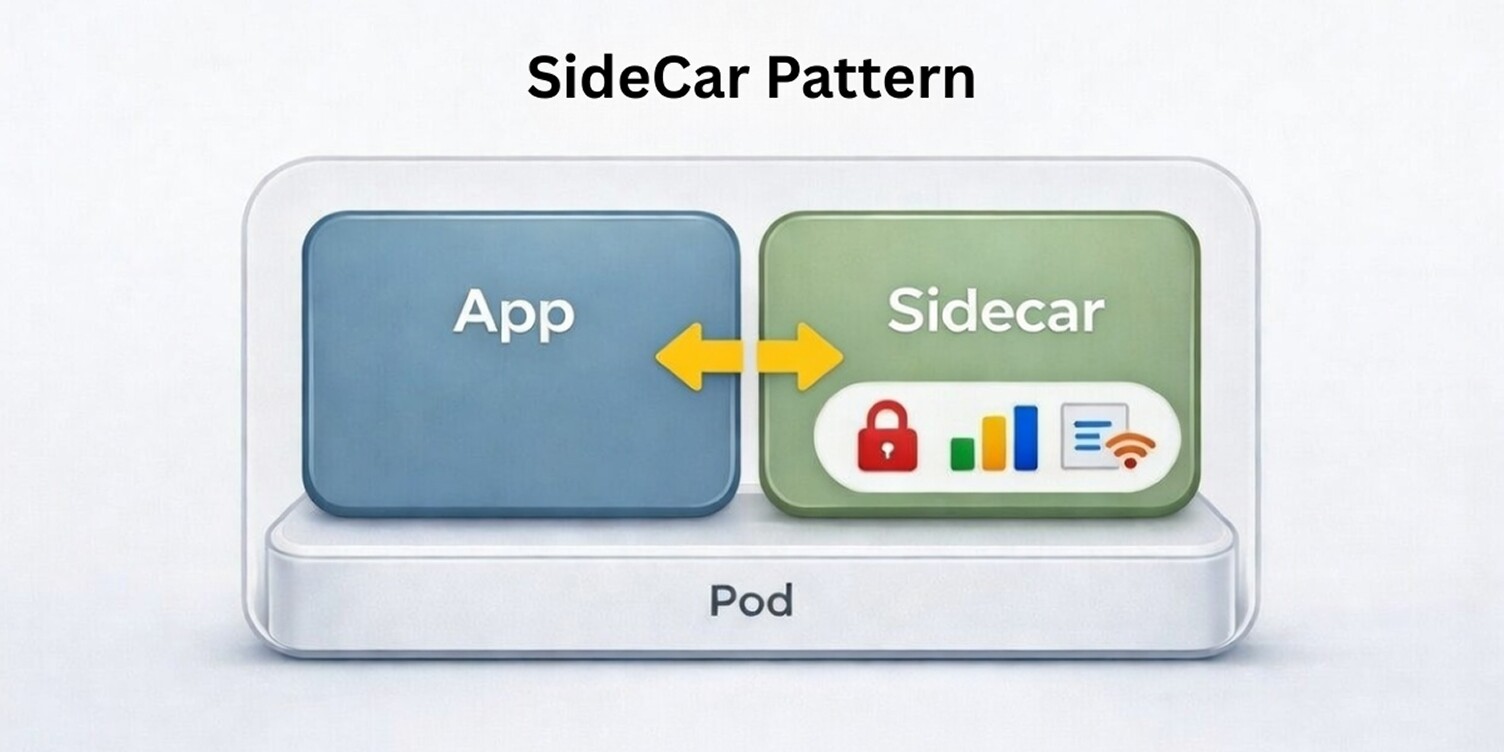
The Sidecar pattern addresses the need to attach supporting capabilities to a service without embedding them into application logic.
In cloud-native systems, concerns such as request mediation, telemetry collection, security enforcement, or configuration handling are required consistently across services but do not belong in the core domain code, which is a common consideration in microservices architecture patterns.
By running a companion component alongside the service and sharing its deployment lifecycle, the Sidecar pattern creates a clear separation between business functionality and operational behavior.
This separation is especially relevant in environments where services are deployed as replaceable units and must initialize, communicate, and shut down predictably without relying on static infrastructure.
Teams use the Sidecar pattern to enforce consistency across services, reduce cross-cutting logic inside applications, and evolve operational capabilities independently as system requirements change.
Ambassador Pattern
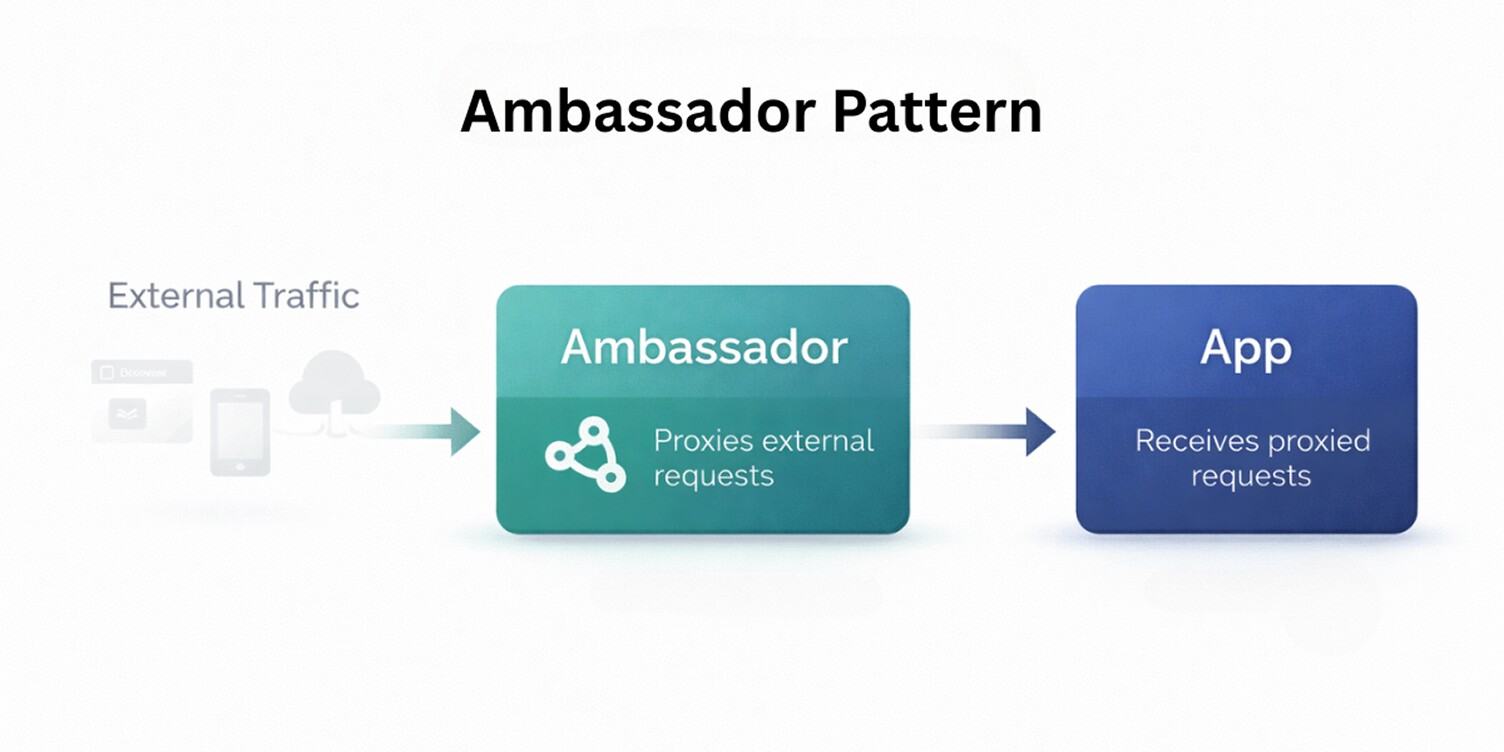
The Ambassador pattern addresses how services communicate with external systems without embedding networking or integration logic into application code.
In cloud-native architectures, services often depend on upstream APIs, databases, or third-party systems, and handling retries, routing, or protocol details inside each service quickly leads to duplication and inconsistency.
By introducing a dedicated proxy that runs alongside the service, the Ambassador pattern moves outbound communication concerns out of the application, simplifying distributed backend service interactions and reducing integration complexity.
The service talks to a local endpoint, while the ambassador manages routing and connection behavior. This keeps application code insulated from changes in network topology or external dependencies.
In practice, the Ambassador pattern helps keep communication logic predictable and easier to change as systems evolve, without forcing changes across every service that depends on external integrations.
Database per Service Pattern
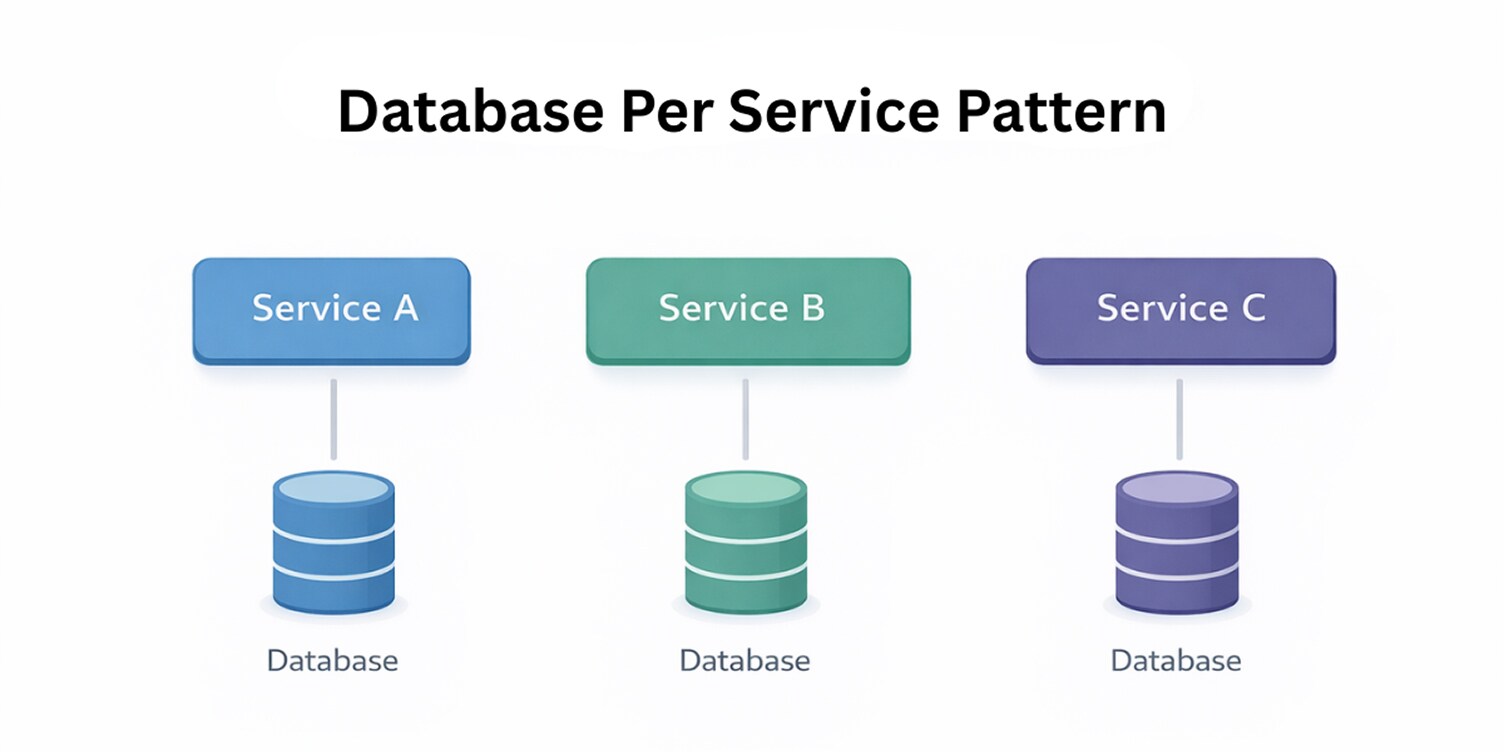
The Database per Service pattern addresses how data is owned and managed when applications are split into independent services.
In cloud-native systems, sharing a single database across services creates tight coupling, hidden dependencies, and coordination issues that undermine independent change. This pattern sits firmly in the design and data category of cloud-native architecture patterns.
By giving each service exclusive ownership of its data store, the pattern enforces clear boundaries between services. A service controls its schema, access rules, and data lifecycle, while other services interact with it only through well-defined interfaces.
This separation aligns with architectures where services are deployed and evolved independently, without relying on shared persistence layers.
In practice, the Database per Service pattern reduces cross-service dependencies and limits the blast radius of change. It supports independent development and deployment while making data ownership explicit, which is critical for maintaining clarity as cloud-native systems grow in size and complexity.
Backend for Frontend (BFF) Pattern
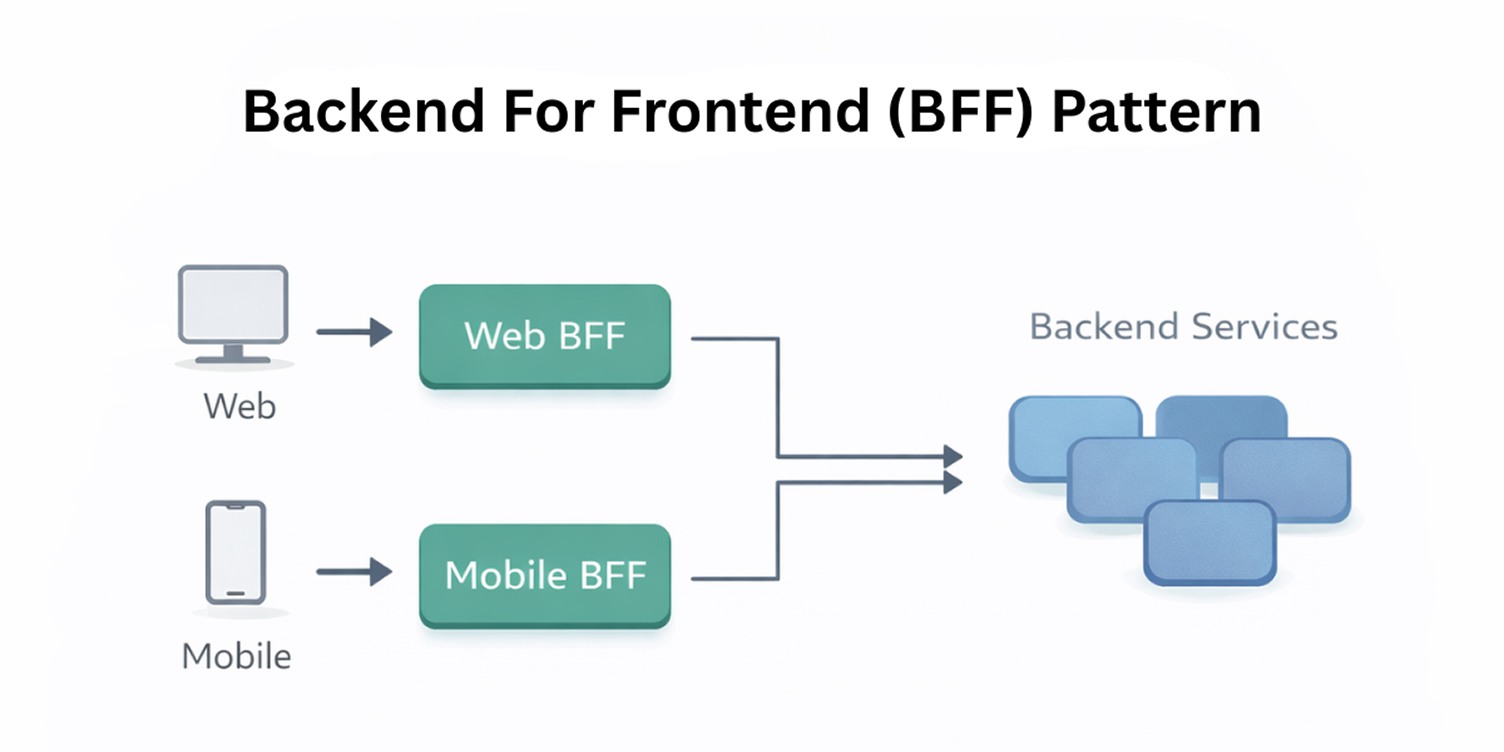
The Backend for Frontend pattern addresses the mismatch between shared backend services and the specific needs of different client applications. In cloud-native systems, a single backend API is often forced to serve web, mobile, and other clients with very different interaction patterns.
This usually results in overly generic endpoints, inefficient data access, and client-specific logic leaking into core services. The BFF pattern belongs to the communication and interface category of cloud-native architecture patterns.
A BFF introduces a thin, client-specific backend layer that sits between the client and internal services, complementing independent frontend architecture on the client side.
This layer shapes responses, coordinates calls to multiple services, and exposes an interface aligned with how a particular client actually consumes data. Core services remain focused on domain behavior, while client-specific concerns are handled at the edge.
In practice, the BFF pattern keeps internal service APIs stable while allowing client experiences to evolve independently. It reduces pressure on shared services to accommodate every client variation and makes client-driven changes easier to manage without rippling through the entire system.
CQRS Pattern
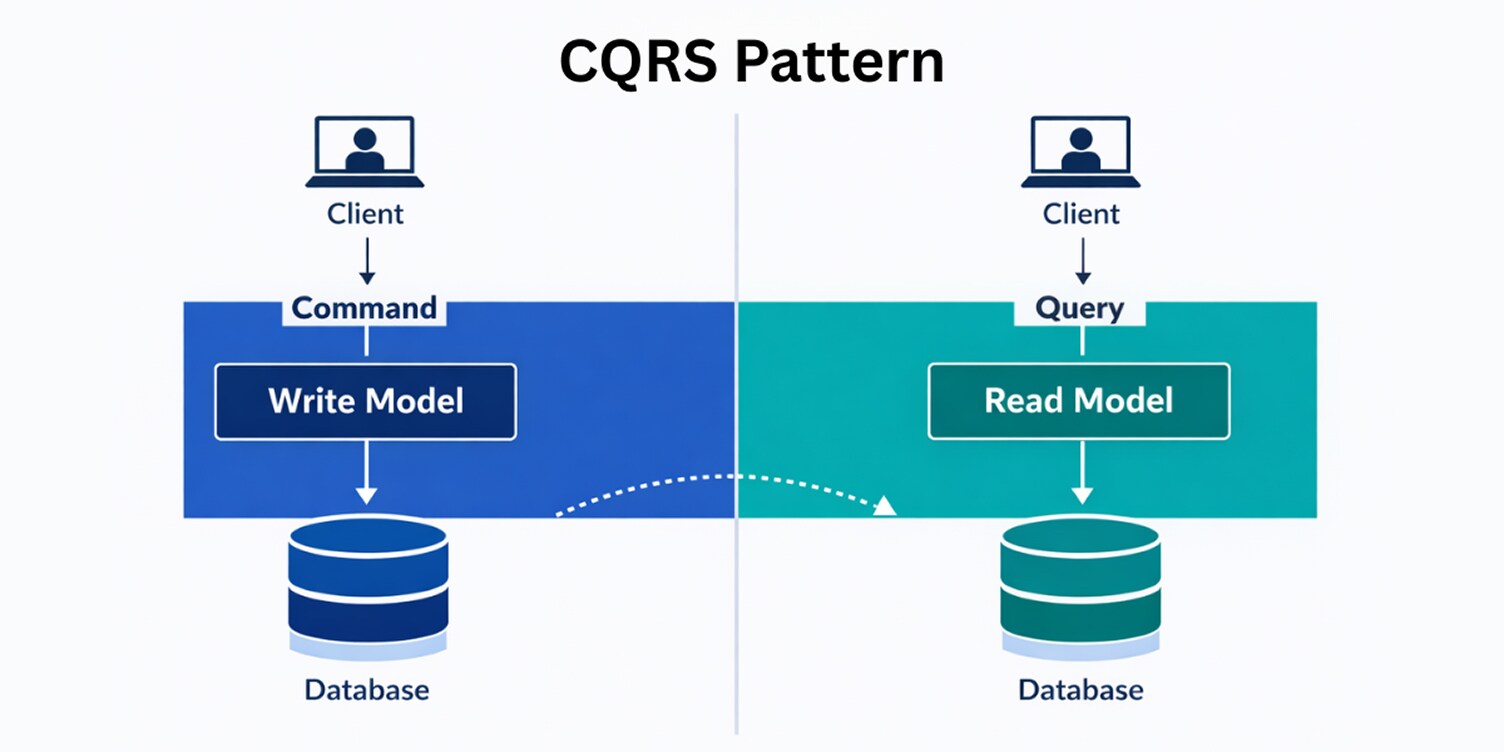
The CQRS pattern addresses the tension between read and write concerns in cloud-native systems. As applications grow, the same data model is often forced to serve transactional updates and complex query requirements, leading to models that are hard to evolve and expensive to change.
CQRS belongs to the design and data category of cloud-native architecture patterns.
CQRS separates the responsibility for handling commands (writes) from queries (reads), allowing each side to evolve independently. Write models can focus on enforcing business rules and consistency, while read models can be shaped to support efficient access patterns without affecting transactional logic.
This separation becomes important in systems where services are deployed independently and read workloads differ significantly from write workloads.
CQRS reduces coupling between business logic and data access by making read and write responsibilities explicit. This separation allows query requirements to change without reshaping transactional models and helps maintain clear boundaries in systems where services, data models, and release cycles evolve independently.
Event Sourcing Pattern
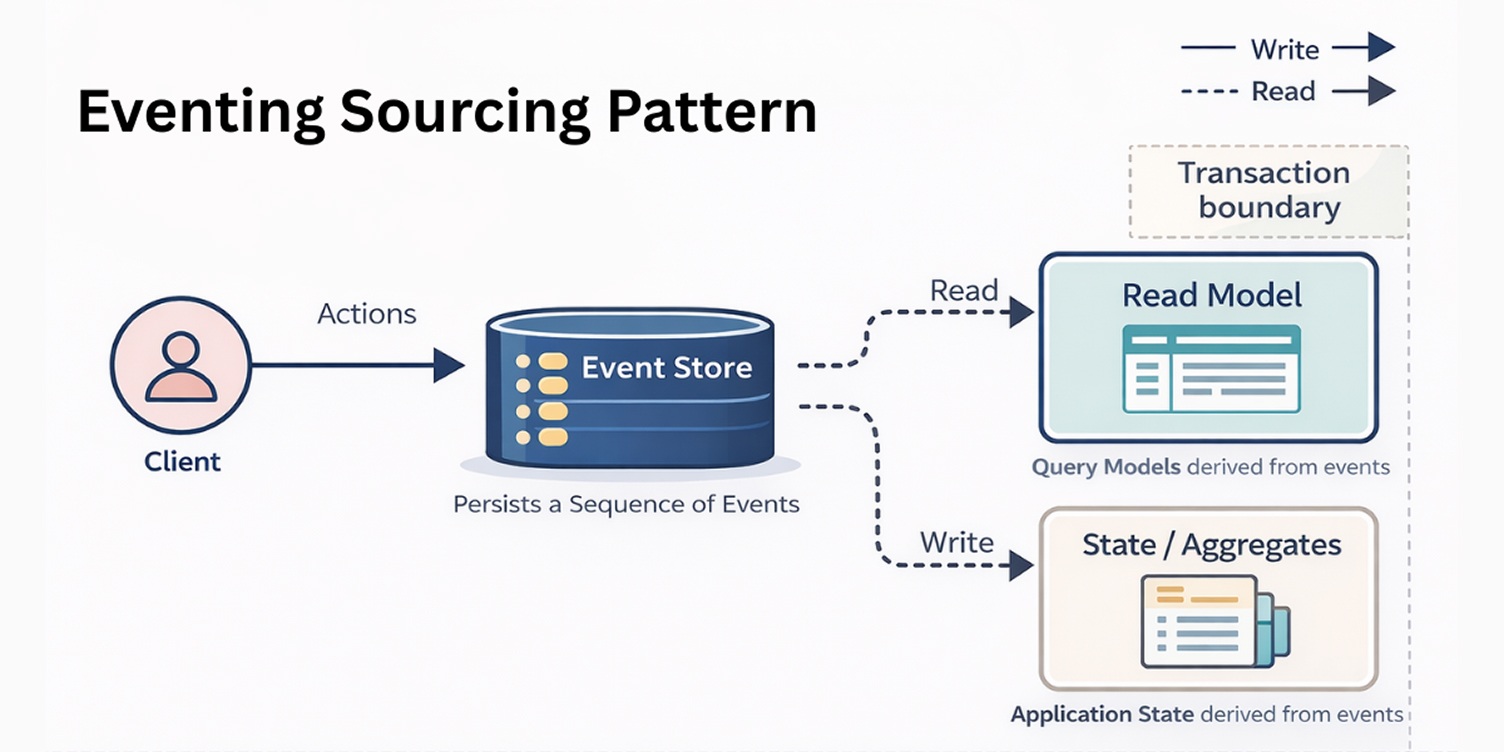
The Event Sourcing pattern addresses how state changes are captured and represented in cloud-native systems. In distributed architectures, relying only on the current state stored in a database can obscure how that state was reached, making debugging, auditing, and change analysis difficult.
Event Sourcing belongs to the design and data category of cloud-native architecture patterns.
Instead of persisting only the latest state, Event Sourcing records every meaningful change as an immutable event. The current state of a service is derived by replaying these events in order.
This approach aligns well with systems where services change independently, particularly in environments supported by microservices consulting support, and where understanding the sequence of actions matters as much as the outcome.
Event Sourcing makes system behavior explicit over time. It supports traceability and clearer reasoning about changes, while allowing data models to evolve without rewriting historical state, an important consideration in long-lived cloud-native systems with complex business flows.
Circuit Breaker Pattern
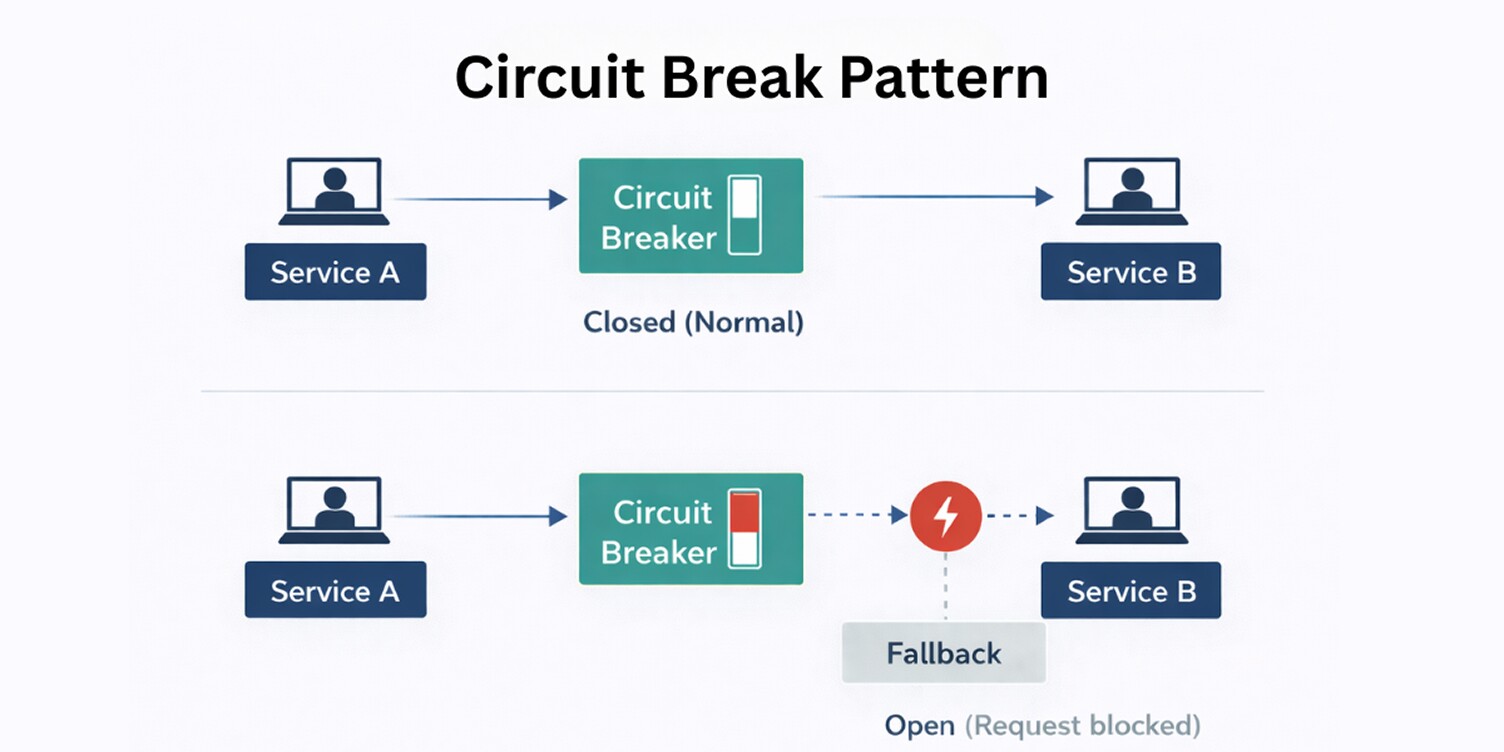
The Circuit Breaker pattern addresses how cloud-native systems handle repeated failures when services depend on one another.
In distributed architectures, a slow or failing service can quickly affect upstream services, leading to cascading failures and widespread disruption. This pattern belongs to the resilience category of cloud-native architecture patterns.
A circuit breaker monitors interactions between services and temporarily blocks requests when failures cross a defined threshold. Instead of continuing to send requests that are likely to fail, the system fails fast and allows the affected service time to recover.
This behavior prevents resource exhaustion and limits how far failures propagate across service boundaries, which becomes particularly important in performance testing for enterprise systems.
The Circuit Breaker pattern makes failure handling explicit and predictable. It helps systems remain responsive under stress, protects healthy services from being overwhelmed, and reinforces the expectation that failure is a normal condition in cloud-native environments rather than an exception to be ignored.
Bulkhead Pattern
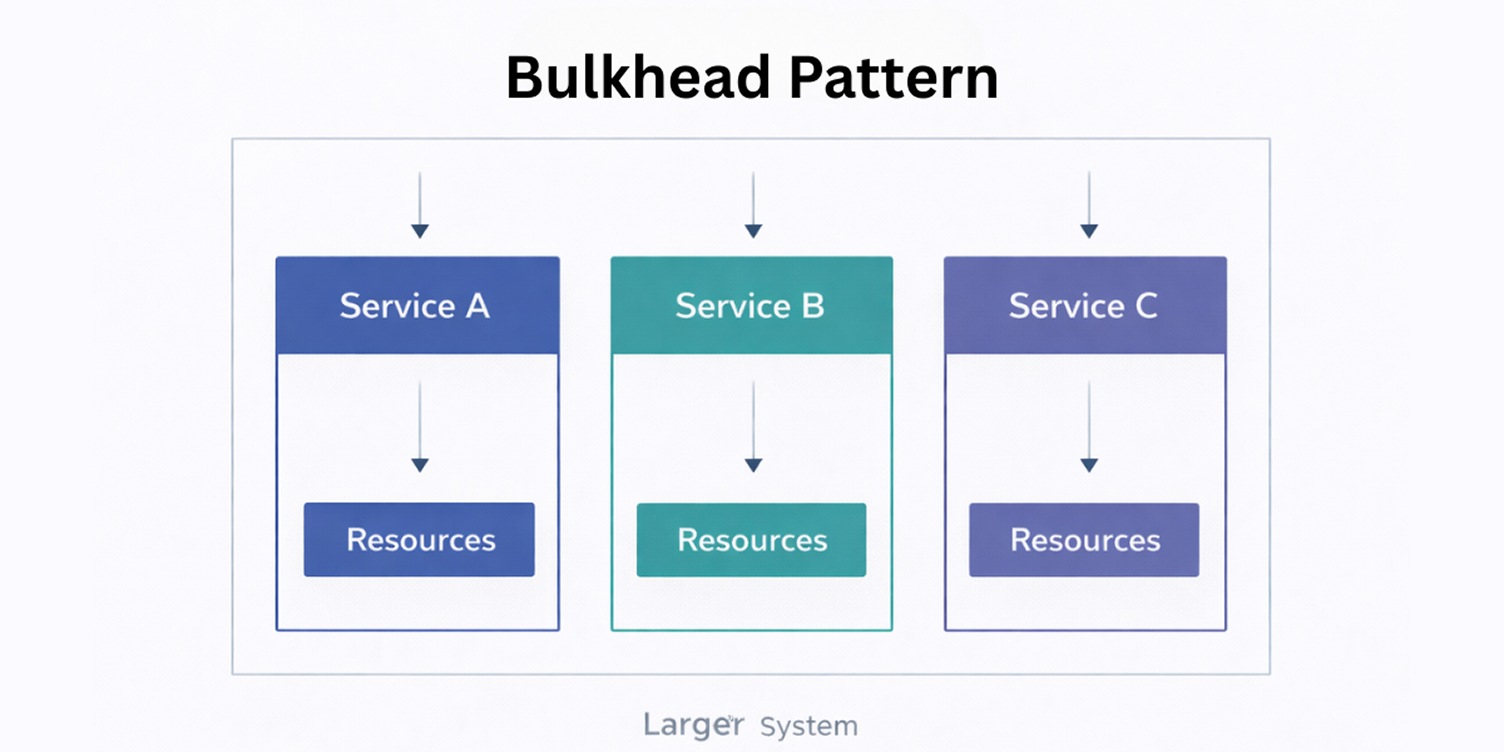
The Bulkhead pattern exists because shared resources are one of the fastest ways for failures to spread in cloud-native systems.
When unrelated requests compete for the same threads, connections, or compute capacity, a localized problem can degrade the entire application, even if most services are healthy.
Bulkheads introduce deliberate isolation at the architectural level. By separating resources along service or workload boundaries, the system prevents one failing or overloaded component from consuming capacity needed elsewhere.
This isolation is especially important in environments where services scale independently, and traffic patterns are uneven.
The Bulkhead pattern forces architects to treat capacity as a design concern rather than an operational afterthought. It reduces unintended coupling through shared resources and helps systems degrade in a controlled way instead of failing unpredictably under pressure.
Saga Pattern
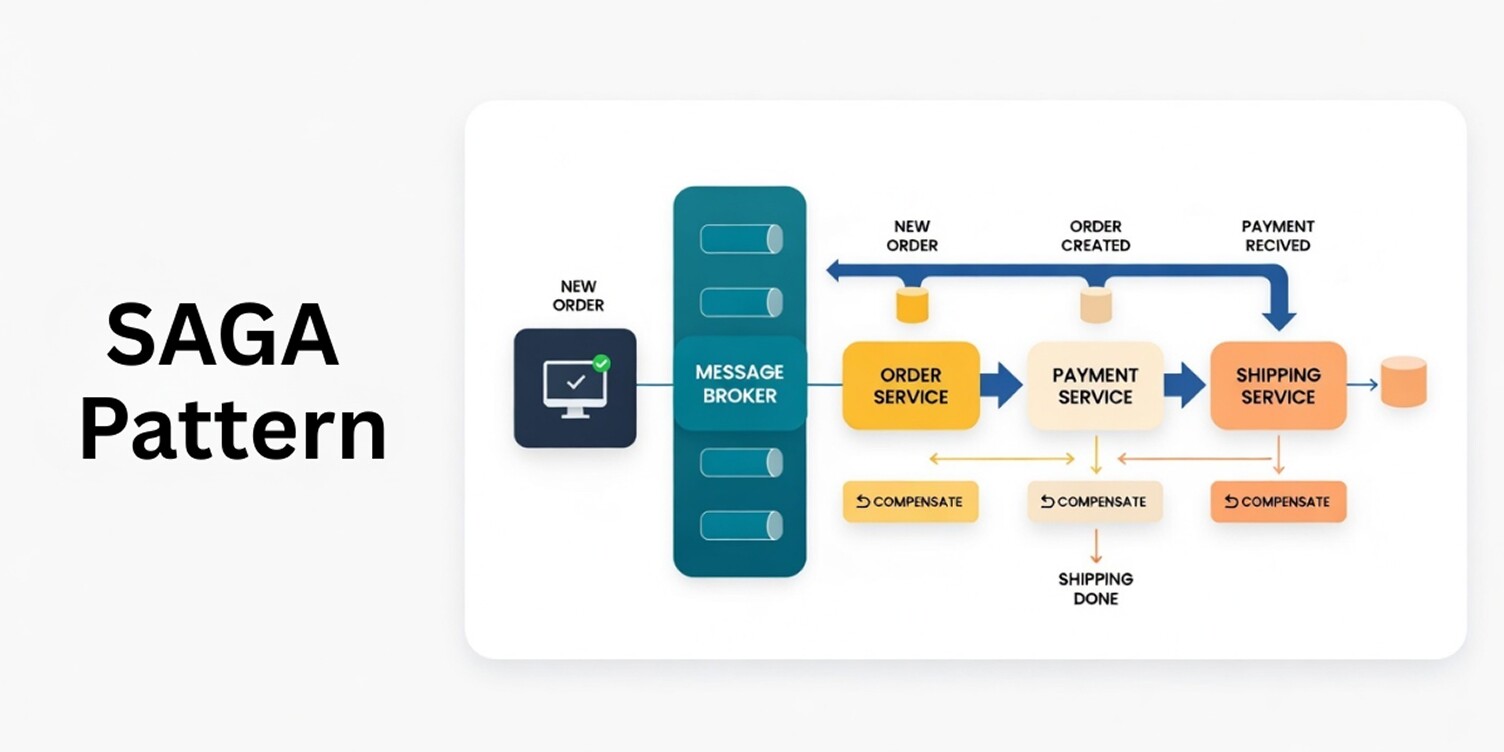
The Saga pattern addresses how multi-step operations are handled across independent services in cloud-native systems.
When workflows span multiple services, traditional transactional models break down because each service owns its data and operates independently, making reliable database solutions essential for managing data across services.
This pattern sits at the intersection of design and resilience, focusing on consistency without shared transactions.
A Saga breaks a long-running operation into a sequence of local actions, each managed by its owning service. When a step completes, the next action proceeds; when a step fails, compensating actions are triggered to undo the effects of earlier steps.
This approach respects service boundaries while providing a controlled way to handle partial failure in distributed workflows.
The Saga pattern makes failure handling an explicit part of system design. It allows services to remain autonomous while coordinating complex business flows, helping cloud-native systems remain predictable even when operations span multiple services and failure is unavoidable.
Each pattern reflects recurring architectural use cases that arise when distributed systems must manage service communication, data ownership, and failure handling under independent deployment.
Patterns and Their Common Tooling Ecosystem
While cloud-native architecture patterns are structural concepts rather than technologies, many cloud-native platforms and tools implement or support these patterns directly. The table below highlights common tooling ecosystems where these patterns are frequently applied.
Limitation of Cloud-Native Architecture Patterns
Cloud-native architecture patterns introduce structural changes to a system. They add new coordination paths, alter data ownership boundaries, and define explicit failure behavior. These transformations are deliberate, however augmenting the architectural surface area of the system.
The extra structure does not enhance clarity when there is no clearly defined service boundary, a clear understanding of dependencies, and apparent failure modes of the pattern being introduced. It doubles the degree of interaction, enlarges the volume of edge cases, and complicates the predictability of system behavior.
The breakdowns occur when the assumptions underlying a pattern do not match the system's actual state.
Pattern Failure Modes
Cloud-native architecture patterns introduce structural mechanisms into a system. They reshape service boundaries, alter coordination paths, and define explicit failure behavior.
When the structural conditions required by a pattern are not present, the added mechanism increases system complexity without improving control.
Premature Structural Complexity
Patterns introduced before the system shows measurable coordination, scaling, or failure pressure tend to add unnecessary structure.
Additional communication flows, state handling logic, and operational rules appear without resolving a concrete constraint. The result is an architecture that is heavier than its workload demands and harder to reason about.
Unstable Service and Data Boundaries
Patterns such as CQRS, Event Sourcing, and Saga assume clearly defined service responsibilities and explicit data ownership. When boundaries are still evolving or inconsistently enforced, coordination begins to spread across services through shared persistence concerns, implicit dependencies, or synchronized changes.
Instead of isolating change, the architecture distributes it, increasing coupling and making transactional behavior and failure handling harder to reason about.
Isolation Without Dependency Clarity
Resilience patterns like Circuit Breaker and Bulkhead are effective when dependency paths are already understood and intentionally bounded.
If service interactions are tightly coupled or poorly defined, runtime isolation does not correct structural coupling. Failures may appear contained while underlying interaction complexity remains unchanged.
Pattern Accumulation Over Time
Architectures can also degrade through gradual pattern accumulation. Each pattern introduces assumptions about communication, state management, or recovery behavior.
When these mechanisms stack without reassessment, the system becomes layered with structural decisions that outlive the constraints they were meant to address.
Effective Pattern Use in Cloud-Native Systems
Cloud-native architecture patterns deliver value when they respond to observable structural conditions rather than anticipated future needs. In distributed environments, patterns shape service boundaries, interaction paths, and failure behavior.
When these characteristics are already visible and measurable, patterns provide structure that stabilizes how the system operates and evolves under change.
Their effectiveness depends on alignment between the assumptions a pattern introduces and the system’s actual operating state.
Stable service ownership, predictable interaction flows, and clearly understood dependencies allow patterns to reinforce architectural clarity rather than add coordination overhead.
Patterns are most effective when they formalize behavior the system already exhibits, not when they impose structure the architecture has not yet required.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us