



Getting Started with Machine Learning in Javascript


Introduction to Machine Learning in JavaScript
Machine learning (ML) has long been associated with languages like Python, which makes sense because Python has so many libraries and a huge community behind it. But JavaScript is opening new doors for ML, bringing it right to the web and making it easier than ever for developers to integrate intelligent features directly into websites and apps. So, why consider JavaScript for ML, and what can it realistically achieve?
Why Use JavaScript for Machine Learning?
Let’s start with the obvious: JavaScript is everywhere. It’s the language of the web, which means every modern browser supports it, and it’s also available on web servers through environments like Node.js. This makes JavaScript particularly powerful for Machine learning when it comes to real-time interaction, data privacy, and accessibility. Here’s what I mean:
Real-Time Client-Side Processing: JavaScript can run models right in the browser! Imagine having your ML model process data in real time without needing a server. For example, a browser-based ML model could flag a suspicious chat message or categorize an image right when the user uploads it. Plus, keeping data local (on the client side) can be a big privacy win, as sensitive information doesn’t leave the user’s device.
- Cross-Platform Compatibility: JavaScript runs seamlessly on practically any device—smartphone, tablet, desktop—you name it. This is great because you don’t have to create device-specific versions of your ML model. Once the model works on one device, it’s ready for others.
- Easy Integration with Web Applications: Web apps today rely heavily on JavaScript for interactive features, and using JavaScript ML lets you add “smart” functionality right into your existing code. Think of simple chat filters, product recommendations, or even mood analysis based on text—all of these can be directly incorporated into a JavaScript-based web app without needing extra services or servers.
When JavaScript Works Better Than Python for ML
Now, I’m not saying JavaScript should replace Python for every ML task—Python’s still the go-to for heavy-duty models. But JavaScript makes a lot of sense when:
- The Model’s Lightweight and Fast: Small models with moderate processing requirements, like basic text analysis or content recommendations, work well in JavaScript. They don’t need the massive computing power that Python handles so well.
- Privacy Matters: Running models in the browser keeps data on the client’s device, which means data stays private. If you’re adding features like chat sentiment analysis or content moderation, this is a big plus.
- Interactivity Is Key: Real-time interactions, like flagging offensive messages in a game or filtering comments on social media, benefit from running directly in the user’s browser without a round-trip to the server.

Popular Libraries for Machine Learning in JavaScript
JavaScript might not have as many ML libraries as Python, but it does have some powerful options that make getting started with machine learning surprisingly accessible. Let’s look at a few of the most popular libraries that can help you add ML into your JavaScript projects.
TensorFlow.js
When people think about machine learning in JavaScript, TensorFlow.js often comes to mind first, and for good reason. TensorFlow.js is the JavaScript version of the popular TensorFlow library in Python, which means it’s built on a solid foundation and can handle both simple and complex ML tasks. You can use it to train and deploy models directly in the browser, which is a game-changer for real-time applications.
Why Use TensorFlow.js?
Flexibility: You can create models from scratch, use pre-trained models, or even convert existing TensorFlow models into JavaScript.
Client-Side and Server-Side: It works both in the browser and with Node.js on the server, making it versatile for different projects.
Huge Community and Support: Since TensorFlow has a huge user base, you’ll find plenty of documentation, tutorials, and community support.
If you’re looking to dive into more complex models, like deep neural networks, TensorFlow.js gives you that capability without needing to switch languages. It’s a great choice if you want to push the limits of what JavaScript can do with ML.
Brain.js
Now, if you’re looking for something lighter and easier to set up, Brain.js might be a great choice. Brain.js focuses on neural networks and keeps things simple, which makes it perfect for smaller projects or when you’re just starting with ML in JavaScript. While it doesn’t have all the bells and whistles of TensorFlow.js, Brain.js is incredibly intuitive and has a straightforward API that makes training models feel easy.
Why Use Brain.js?
Lightweight and Quick: Brain.js is much less resource-intensive, which makes it ideal for quick, small-scale ML tasks.
Good for Beginners: The library is user-friendly and great for learning about neural networks without a steep learning curve.
Ideal for Real-Time Interactions: Since it’s lightweight, it works well for simple tasks like content filtering, basic image recognition, or small recommendation systems.
For projects that don’t need high performance but benefit from easy setup and fast responses, Brain.js is a solid pick. Think about it like a starter library for basic neural networks in JavaScript.
Synaptic
For those who need a bit more customization, Synaptic offers a middle ground between TensorFlow.js and Brain.js. Synaptic is a library that’s entirely focused on building and training neural networks, but it gives you more control over how the networks are structured. If you’re interested in experimenting with network architecture, Synaptic’s flexibility might be exactly what you need.
Why Use Synaptic?
Customizable Networks: Synaptic gives you more control, letting you define layers and structure according to your project’s needs.
Good for Experiments: If you want to try out different architectures or layer types, Synaptic offers the flexibility to explore.
Simple Yet Powerful: Even though it’s customizable, Synaptic isn’t overwhelming; it strikes a good balance between control and simplicity.
Synaptic could be a good choice if you’re diving a bit deeper and want to understand neural network structures without leaving JavaScript.
ML5.js
If you’re a beginner and looking for an easy way to add machine learning to your project, ML5.js might be just what you need. Built on top of TensorFlow.js, ML5.js makes machine learning approachable for everyone. It has a high-level API that lets you perform common ML tasks without the steep learning curve that usually comes with them.
Why Use ML5.js?
Beginner-Friendly: ML5.js is all about accessibility. It has an intuitive API and makes machine learning feel a lot less intimidating.
Built on TensorFlow.js: Since it’s built on top of TensorFlow.js, you get the benefits of a robust foundation with a simpler interface.
Great for Prototyping: If you need to quickly test an idea or create a prototype with ML, ML5.js is perfect for fast results.
ML5.js is especially popular for creative projects, like interactive media or web art, and for adding basic ML features without getting too technical. It’s a great choice if you want to start experimenting with machine learning right away.
Building Your First ML Model with TensorFlow.js
we’ll create a machine learning model to predict student test scores based on the number of study hours using TensorFlow.js. This hands-on project will help you understand the fundamentals of machine learning while working with real data.
To follow along, download the Student Study Hours dataset from Kaggle here and save it as score.csv in your project directory.
Install Dependencies
Before we start coding, we need to install some essential libraries. We'll use TensorFlow.js for building our machine learning model and a CSV parsing library to read our dataset.
TensorFlow.js: This is the core library we’ll use for all our machine learning tasks in JavaScript. It allows us to build, train, and deploy machine learning models directly in Node.js.
CSV Parser: This library will help us read the CSV file containing our dataset, making it easy to extract the study hours and corresponding scores.
To install these libraries, run the following command in your terminal:
npm install @tensorflow/tfjs csv-parserCreate and Train the Model
Now that we have our dependencies installed, let’s write the code that will load the data, train our model, and make predictions based on different study hours. Below is the complete code:
const tf = require('@tensorflow/tfjs');
const fs = require('fs');
const csv = require('csv-parser');
async function trainGradePredictor(csvPath) {
// Load training data
const trainingData = {
hoursStudied: [],
scores: []
};
await new Promise((resolve, reject) => {
fs.createReadStream(csvPath)
.pipe(csv())
.on('data', (row) => {
trainingData.hoursStudied.push(parseFloat(row.Hours));
trainingData.scores.push(parseFloat(row.Scores));
})
.on('end', resolve)
.on('error', reject);
});
// initialize the model
const model = tf.sequential();
model.add(tf.layers.dense({ units: 1, inputShape: [1] }));
model.compile({
optimizer: 'sgd',
loss: 'meanSquaredError'
});
// training
const xs = tf.tensor1d(trainingData.hoursStudied);
const ys = tf.tensor1d(trainingData.scores);
await model.fit(xs, ys, { epochs: 200 });
// predection function
return function predictGrade(studyHours) {
const prediction = model.predict(tf.tensor2d([studyHours], [1, 1]));
return parseFloat(prediction.dataSync()[0].toFixed(2));
};
}
async function main() {
try {
const predictGrade = await trainGradePredictor('/home/code-b/Downloads/score.csv');
const test1 = predictGrade(6);
console.log('Predicted grade for 6 hours:', test1);
const test2 = predictGrade(8);
console.log('Predicted grade for 8 hours:', test2);
const test3 = predictGrade(3);
console.log('Predicted grade for 3 hours:', test3);
} catch (error) {
console.error('Error:', error);
}
}
main();How the Code Works
Data Loading: The code begins by reading the score.csv file, where we have stored our dataset. Using the csv-parser library, we extract the study hours and scores, storing them in arrays called hoursStudied and scores.
Model Definition: We define a simple linear regression model using TensorFlow.js. This model will learn the relationship between study hours and test scores. The inputShape: [1] specifies that our model will take a single input (the number of hours studied).
Model Training: The model is trained using the data we loaded earlier. We use the fit method to train our model for 200 epochs, meaning it will go through the entire dataset 200 times to learn the patterns.
Prediction: After training, we create a predictGrade function that takes the number of study hours as input and returns the predicted score. The model.predict method is used to make predictions based on new input data.
Testing and Evaluating the Models
Once you have built and trained your machine learning model, it's crucial to test and evaluate its performance. This ensures that your model can generalize well to new, unseen data. In this section, we’ll discuss various techniques to test and evaluate your model effectively.
Techniques for Testing and Evaluating Your Model
- Train-Test Split:
Divide your dataset into two parts: a training set and a testing set. The model is trained on the training set and evaluated on the testing set.
A common split is 80% for training and 20% for testing.
const splitIndex = Math.floor(trainingData.length * 0.8);
const trainData = trainingData.slice(0, splitIndex);
const testData = trainingData.slice(splitIndex);- Evaluation Metrics:
Choose appropriate metrics to evaluate your model. For regression problems, common metrics include:
Mean Absolute Error (MAE): The average of absolute errors between predicted and actual values.
Mean Squared Error (MSE): The average of squared differences between predicted and actual values.
R-squared: Indicates how well the data points fit the regression line.
function calculateMAE(actual, predicted) {
let totalError = 0;
for (let i = 0; i < actual.length; i++) {
totalError += Math.abs(actual[i] - predicted[i]);
}
return totalError / actual.length;
}- Cross-Validation:
Instead of a simple train-test split, cross-validation involves dividing the dataset into multiple subsets (folds) and training the model multiple times, each time using a different fold for testing and the others for training. This helps ensure that the model's performance is consistent across different subsets of the data.
A common approach is k-fold cross-validation, where the data is split into k subsets.
- Interpreting Results:
After testing your model, interpret the results in the context of your problem. Consider the implications of the performance metrics and whether they meet your project's requirements.
Discuss any discrepancies between predicted and actual values and potential reasons for those differences.
Example Evaluation Code
Here’s how you might implement testing and evaluation in your model:
const tf = require('@tensorflow/tfjs');
const fs = require('fs');
const csv = require('csv-parser');
function normalizeData(data) {
const hoursMin = Math.min(...data.hours);
const hoursMax = Math.max(...data.hours);
const scoresMin = Math.min(...data.scores);
const scoresMax = Math.max(...data.scores);
return {
normalizedData: {
hours: data.hours.map(h => (h - hoursMin) / (hoursMax - hoursMin)),
scores: data.scores.map(s => (s - scoresMin) / (scoresMax - scoresMin))
},
params: {
hoursMin, hoursMax, scoresMin, scoresMax
}
};
}
function denormalizePrediction(normalizedPred, scoresMin, scoresMax) {
return normalizedPred * (scoresMax - scoresMin) + scoresMin;
}
function calculateMetrics(actual, predicted) {
const n = actual.length;
const mae = actual.reduce((sum, val, i) => sum + Math.abs(val - predicted[i]), 0) / n;
const mse = actual.reduce((sum, val, i) => sum + Math.pow(val - predicted[i], 2), 0) / n;
const rmse = Math.sqrt(mse);
const meanActual = actual.reduce((sum, val) => sum + val, 0) / n;
const ssTotal = actual.reduce((sum, val) => sum + Math.pow(val - meanActual, 2), 0);
const ssResidual = actual.reduce((sum, val, i) => sum + Math.pow(val - predicted[i], 2), 0);
const rSquared = 1 - (ssResidual / ssTotal);
const mape = (actual.reduce((sum, val, i) => sum + Math.abs((val - predicted[i]) / val), 0) / n) * 100;
return {
mae: mae.toFixed(4),
mse: mse.toFixed(4),
rmse: rmse.toFixed(4),
rSquared: rSquared.toFixed(4),
mape: mape.toFixed(2) + '%'
};
}
function trainTestSplit(data, testSize = 0.2) {
const indices = Array.from(Array(data.hours.length).keys());
for (let i = indices.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[indices[i], indices[j]] = [indices[j], indices[i]];
}
const splitIndex = Math.floor(data.hours.length * (1 - testSize));
return {
train: {
hours: indices.slice(0, splitIndex).map(i => data.hours[i]),
scores: indices.slice(0, splitIndex).map(i => data.scores[i])
},
test: {
hours: indices.slice(splitIndex).map(i => data.hours[i]),
scores: indices.slice(splitIndex).map(i => data.scores[i])
}
};
}
async function trainGradePredictor(csvPath) {
const rawData = {
hours: [],
scores: []
};
await new Promise((resolve, reject) => {
fs.createReadStream(csvPath)
.pipe(csv())
.on('data', (row) => {
rawData.hours.push(parseFloat(row.Hours));
rawData.scores.push(parseFloat(row.Scores));
})
.on('end', resolve)
.on('error', reject);
});
const { train, test } = trainTestSplit(rawData, 0.2);
const { normalizedData: normalizedTrain, params } = normalizeData(train);
const { normalizedData: normalizedTest } = normalizeData(test);
const model = tf.sequential();
model.add(tf.layers.dense({
units: 16,
inputShape: [1],
activation: 'relu'
}));
model.add(tf.layers.dense({
units: 8,
activation: 'relu'
}));
model.add(tf.layers.dense({
units: 1
}));
model.compile({
optimizer: tf.train.adam(0.01),
loss: 'meanSquaredError',
});
const xsTrain = tf.tensor2d(normalizedTrain.hours, [normalizedTrain.hours.length, 1]);
const ysTrain = tf.tensor2d(normalizedTrain.scores, [normalizedTrain.scores.length, 1]);
console.log('\nTraining model...');
await model.fit(xsTrain, ysTrain, {
epochs: 500,
verbose: 0,
callbacks: {
onEpochEnd: (epoch, logs) => {
if (epoch % 100 === 0) {
console.log(`Epoch ${epoch}: loss = ${logs.loss.toFixed(4)}`);
}
}
}
});
const xsTest = tf.tensor2d(normalizedTest.hours, [normalizedTest.hours.length, 1]);
const normalizedPreds = model.predict(xsTest).dataSync();
const predictions = Array.from(normalizedPreds).map(pred =>
denormalizePrediction(pred, params.scoresMin, params.scoresMax)
);
const metrics = calculateMetrics(test.scores, predictions);
console.log('\nEvaluation Metrics on Test Set:');
console.log('--------------------------------');
console.log(`Mean Absolute Error (MAE): ${metrics.mae}`);
console.log(`Mean Squared Error (MSE): ${metrics.mse}`);
console.log(`Root Mean Squared Error (RMSE): ${metrics.rmse}`);
console.log(`R-squared (R²): ${metrics.rSquared}`);
console.log(`Mean Absolute Percentage Error (MAPE): ${metrics.mape}`);
const predictGrade = function(studyHours) {
const normalizedHours = (studyHours - params.hoursMin) / (params.hoursMax - params.hoursMin);
const normalizedPred = model.predict(tf.tensor2d([normalizedHours], [1, 1])).dataSync()[0];
return parseFloat(denormalizePrediction(normalizedPred, params.scoresMin, params.scoresMax).toFixed(2));
};
predictGrade.metrics = metrics;
predictGrade.testData = test;
return predictGrade;
}
async function main() {
try {
await trainGradePredictor('/home/code-b/Downloads/score.csv');
} catch (error) {
console.error('Error:', error);
}
}
main();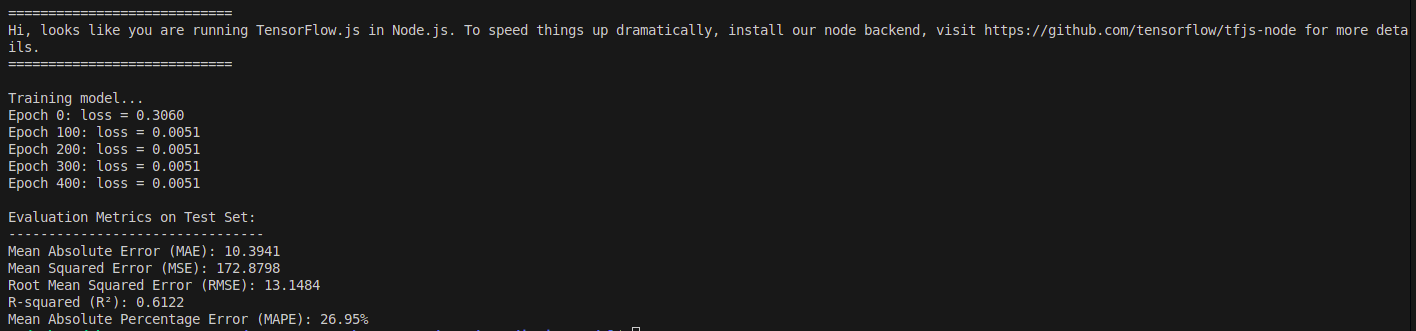
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us