



How to Build an AI Model from Scratch: Tools, Steps, and Examples



An AI program is a software that utilizes data and algorithms to make decisions or predictions without being specifically programmed to do so. At the core of the AI program is an AI model, which learns from the data it is given and is capable of performing tasks such as classification, prediction, or even the creation of content.
This blog aims to cover the entire development process of AI, so you will have a clear understanding of how an AI application is developed, what it requires to develop an AI application, and how each part of an AI application functions.
Understanding Types of AI Models and Approaches
Before building an AI system, it is important to understand the different types of models and approaches available. Each approach is designed to handle specific kinds of problems, data, and levels of complexity. Having a clear understanding of these categories makes it easier to see how AI systems are structured and how different components fit together.
AI models can be viewed in two ways: first, how they learn from data, and second, what tasks they perform. When you look at both sides together, you get a better idea of how AI systems are made in the real world.
Learning-Based Approaches
These approaches define how a model learns from data and improves its performance over time.
Supervised Learning
When the dataset has both inputs and known outputs, supervised learning is used. The model learns by comparing its guesses to real-world results and gets better at making them over time.
The model is better at finding patterns that connect inputs to expected outcomes because the learning process is based on labelled data. This makes it a beneficial choice for situations where past data already shows correct results and can be used to make predictions about the future.
Unsupervised Learning
Unsupervised learning is used when the data does not include predefined outputs. The model doesn't use correct answers to guide it; instead, it looks at the data on its own to identify patterns, similarities, and structures.
It puts together related data points or draws attention to strange behaviour based on how the data is set up. This method is especially advantageous for finding hidden connections, sorting through big datasets, and getting insights when there are no labels.
Model Complexity
This layer explains how advanced a system needs to be based on the nature of the problem and the type of data involved.
Machine Learning
Machine learning represents a broad category of models that learn from data to make predictions or decisions without relying on explicitly defined rules. These models analyze relationships between variables and improve their performance as they are exposed to more data.
This makes them effective for a wide range of structured and semi-structured problems where patterns exist but are not easily defined manually.
Deep Learning
Deep learning builds on machine learning by using multi-layered neural networks to process more complex and high-dimensional data. Each layer captures different levels of detail, allowing the model to recognize patterns that are difficult for traditional methods to detect.
This makes deep learning particularly effective for tasks involving images, audio, and large volumes of text, where understanding context and subtle variations is important.
However, this added capability also comes with higher data and computational requirements.
Application-Based Models
These models are defined by the type of data they process and the outcomes they are designed to produce.
Natural Language Processing (NLP)
NLP is all about making it possible for systems to understand, interpret, and create human language. It works by turning speech or text into large language model embeddings, allowing models to understand context, intent, and meaning more effectively. Pre-trained models are also used to handle language tasks more effectively.
This lets us make systems that can talk to people, look at text data, and do language-based tasks automatically in a way that makes sense and feels natural.
Computer Vision
Computer vision is a field that deals with understanding pictures and videos. These models learn by looking for patterns in pixel-level data and slowly getting better at recognising edges, shapes, and objects.
Over time, they learn how to figure out what's in a picture and how the different parts of it fit together. This lets systems look at and smartly understand visual information.
Generative AI
Generative AI focuses on creating new content rather than analysing existing data. These models learn the structure and distribution of data and use that understanding to generate outputs that follow similar patterns.
This can include text, images, audio, or code. The ability to produce new, contextually relevant content makes this approach particularly useful in scenarios where creation and automation are required.
How These Approaches Work Together
In real-world applications, these approaches are rarely used in isolation. Most AI agent firms combine multiple techniques to handle different aspects of a problem, with each component contributing a specific capability based on its role and complexity.
At a basic level, simpler machine learning models are often used to handle structured data and make quick decisions based on rules.
As the task becomes more complicated, especially when working with unstructured data like text, images, or audio, more advanced models like deep learning are used to find deeper patterns and connections.
This layered approach keeps systems running smoothly while only adding complexity where it makes sense.
For instance, machine learning models in an e-commerce recommendation system might look at how users act and what they buy to find patterns. Deep learning models, on the other hand, can look at more complicated signals, like how users browse or how similar products are.
Generative models can also be used to make product descriptions or recommendations more personal in some cases. The system becomes more accurate, flexible, and able to provide a better user experience when these methods are used together.
How to Select the Right Approach

Choosing the right model depends on the problem you are solving, the type of data you have, and how accurate the system needs to be. Instead of starting with a specific technology, it is more effective to first understand the nature of the task and then align the approach accordingly.
1. Data Availability and Structure
When your data includes clearly defined inputs and expected outputs, supervised learning offers a straightforward and reliable path. The model learns from past examples and can apply that learning consistently to new data.
If your data lacks predefined labels and you want to find patterns or group similar data points, unsupervised learning is more useful. It helps organise and make sense of data without needing prior guidance.
The quality of your data plays a major role in how well the model performs. Even if the data is labelled, issues such as missing values, inconsistencies, or bias can affect the results. In many cases, improving the data leads to better outcomes than changing the model itself.
2. Complexity of the Problem
For many business problems, machine learning provides a good balance between performance and effort. It works well when the data is structured, and the patterns are not overly complex.
As the problem becomes more complex, such as working with images, audio, or large amounts of text, deep learning becomes more suitable. It can capture more detailed patterns, but it also requires more data, time, and computational resources.
3. Speed and System Requirements
Some systems need to respond instantly, while others can process data over time. If quick responses are important, the model needs to be efficient and fast. For tasks that run in the background, more complex models can be used even if they take longer to process.
As the system grows and handles more users or data, it’s important to consider how easily the model can handle increased load. This includes factors like performance, cost, and how the system will be maintained over time.
4. Nature of the Task
The type of task also plays a key role in selecting the right approach.
If the system needs to understand or work with language, Natural Language Processing becomes essential. When working with images or videos, computer vision is required to interpret visual information.
If the goal is to create new content rather than analyze existing data, generative AI provides the ability to produce outputs based on learned patterns.
5. Accuracy and Interpretability
Different use cases require different levels of accuracy. Some systems can tolerate small errors, while others require highly reliable outputs.
In certain cases, it is also important to understand how the model arrives at its decisions. Simpler models are often easier to interpret, while more complex models may provide better performance but less transparency. This trade-off can influence the final choice depending on the use case.
6. Using Multiple Approaches Together
In many live applications, a single approach is not enough. Different parts of a system may require different techniques working together.
Combining approaches allows the system to handle complexity more effectively, using simpler models where possible and more advanced models where needed. This leads to better performance while keeping the system practical and efficient.
When the approach is chosen carefully, the rest of the development process becomes more structured and predictable. This not only improves performance but also ensures the system can adapt and scale as requirements evolve.
Choosing Between Pretrained and Custom AI Models
One of the first decisions in building an AI system is whether to use a pretrained model or develop a custom model. This choice directly impacts development time, cost, flexibility, and how well the system performs for your specific use case.
Pretrained models are AI models that are already trained on large datasets and can be used directly through APIs or libraries. They are chosen when the goal is to build quickly without handling data collection, training, or infrastructure.
Custom models are built from scratch using your own data and are designed for specific problems. They are chosen when more control, better accuracy, or domain-specific behavior is required.
Understanding the difference between these two approaches helps in choosing the right direction from the start, reducing unnecessary work, and aligning the solution with the problem based on available data, development time, and the level of control required over the model.
Understanding the Trade-offs
Pretrained models are suitable when the goal is to build quickly, and the problem is common. They make things easier to use because you don't have to manage data, training, or infrastructure. But they don't offer much flexibility and might not work well for tasks that are very specific or focused on a certain area.
Custom models take more work, time, and resources, but they provide control over how the model works. They are better for problems where accuracy and performance in a specific field are important. The choice depends on whether speed and ease of use or control and accuracy are more important.
Ultimately, the decision is not just about technology but about priorities. If the problem is common and speed matters, pretrained models are often the right choice. If the problem is unique and requires precision, investing in a custom model becomes more valuable.
How to build an AI model a step by step process
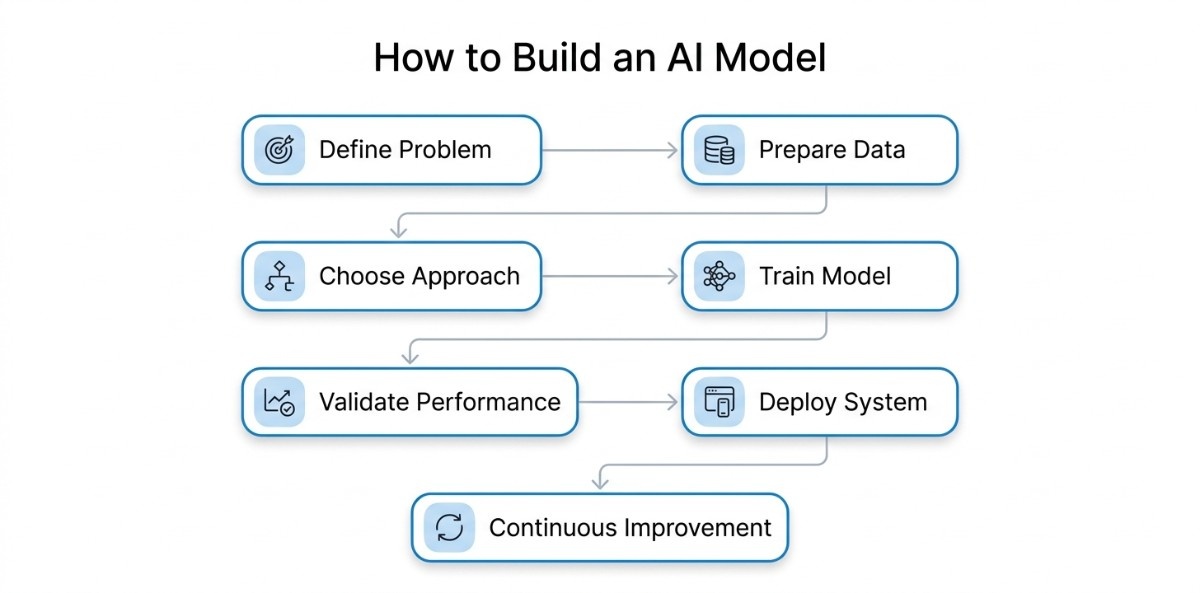
AI development follows a process where each stage is built towards a working system. When approached in the right order, it becomes easier to create solutions that are both accurate and practical.
Step 1: Define the Problem
The process starts with clearly defining what the AI program is expected to do. This means identifying a specific task and avoiding vague goals.
At this stage, the inputs and outputs are also defined. The system will receive user queries as input and return relevant answers as output, which creates a clear structure for how the system will function.
This clarity becomes the foundation for everything that follows. When the problem is well defined, each next step naturally aligns with it, and the effort stays focused on solving the right task.
Step 2: Gather and Prepare the Right Data
With a clear problem in place, the next step is to work with data that reflects that problem in real-world scenarios.
For a system like this, relevant data includes FAQs, support tickets, past conversations, and product documentation. These sources capture how users ask questions and how answers are typically provided, which is essential for training the system.
However, this data cannot be used in its raw form. It needs to be cleaned, structured, and made consistent so the model can learn effectively. Irrelevant entries are removed, duplicates are handled, and the content is organized in a way that reflects real usage patterns.
The dataset is then divided into training, validation, and testing sets, ensuring that the system can be evaluated on new inputs rather than relying only on familiar data.
Step 3: Choose an Approach That Fits
Once the data is prepared, the focus shifts to deciding how the system will be built using that data.
For this use case, starting with a pretrained language model is a practical choice because it already understands general language patterns. This allows the system to respond effectively from the beginning while still allowing customization based on the prepared data.
The decision here is not about choosing the most complex solution but about selecting an approach that fits the problem, the available data, and the level of control required.
With both the problem and data clearly defined, this step provides direction for how the system will be developed.
Step 4: Train the Model with Real Data
The model is exposed to structured data and starts identifying patterns in how queries are asked and how responses are formed. Over multiple iterations, it improves its ability to generate relevant answers.
As the model learns, it becomes important to observe how it is responding. If the data contains inconsistencies or gaps, those issues start to appear in the output. This is why the earlier steps, especially data preparation, play such a critical role in shaping the results.
The goal is not just to learn patterns but to generalize them so the system can respond accurately to new queries.
Step 5: Validate How the Model Performs in Practice
Once training is complete, the next step is to evaluate how well the system performs beyond the data it has already seen.
The model is tested using new queries, including variations in phrasing, to check whether it understands intent rather than simply recalling patterns.
Through repeated testing, it becomes clear whether the system is consistent and reliable. If it performs well across different scenarios, it indicates that the training has been effective. If not, it highlights areas that may need improvement.
This stage ensures that the system is not only trained but also dependable before it is used in real world conditions.
Step 6: Turn the Model into a Usable System
With a validated model in place, the next step is to integrate it into a system where users can interact with it.
When a user sends a message, it is processed by the backend, passed to the model, and the response is returned to the interface. This transforms the model into a functional application.
As the system is deployed, it begins operating under real world conditions where inputs vary, and user behavior introduces new patterns. This makes reliability, response time, and consistency critical.
The focus is on ensuring that the system performs smoothly and delivers a consistent experience.
Step 7: Continuously Improve Based on Real Usage
After deployment, the system enters an ongoing phase of improvement driven by real user interactions.
As new queries emerge and user behavior evolves, the system may begin to lose accuracy over time. To address this, new data is collected, analyzed, and used to retrain the model.
This creates a continuous cycle of learning, testing, and improvement, allowing the system to stay relevant and effective. Rather than remaining static, the system evolves with usage and becomes more accurate over time.
How These Steps Work in a Real Scenario
To understand how these steps translate into a working system, consider a business building a chatbot to handle customer queries. The process begins by clearly defining the objective, rather than creating a generic chatbot, the team focuses on answering product-related questions using existing support content.
This clarity sets direction, ensuring the system is built to solve a specific problem with well-defined inputs and outputs.
The team collects useful information from FAQs, support tickets, past conversations, and product documentation to reach their goal. After that, the data is cleaned up and organised so that it accurately shows how people ask questions and how answers should be given.
They pick a pretrained language model and improve it with their own data, which helps the system understand both general language and questions that are specific to their field better.
The model is then trained to learn patterns from the data and tested with new queries to ensure it can handle variations and respond reliably. Once the performance is consistent, the system is integrated into the application, making it accessible to users in real time.
As interactions grow, new data is collected and used to continuously improve the model, ensuring the chatbot becomes more accurate and better aligned with user needs over time.
Deciding Between Building AI In-House or Outsourcing
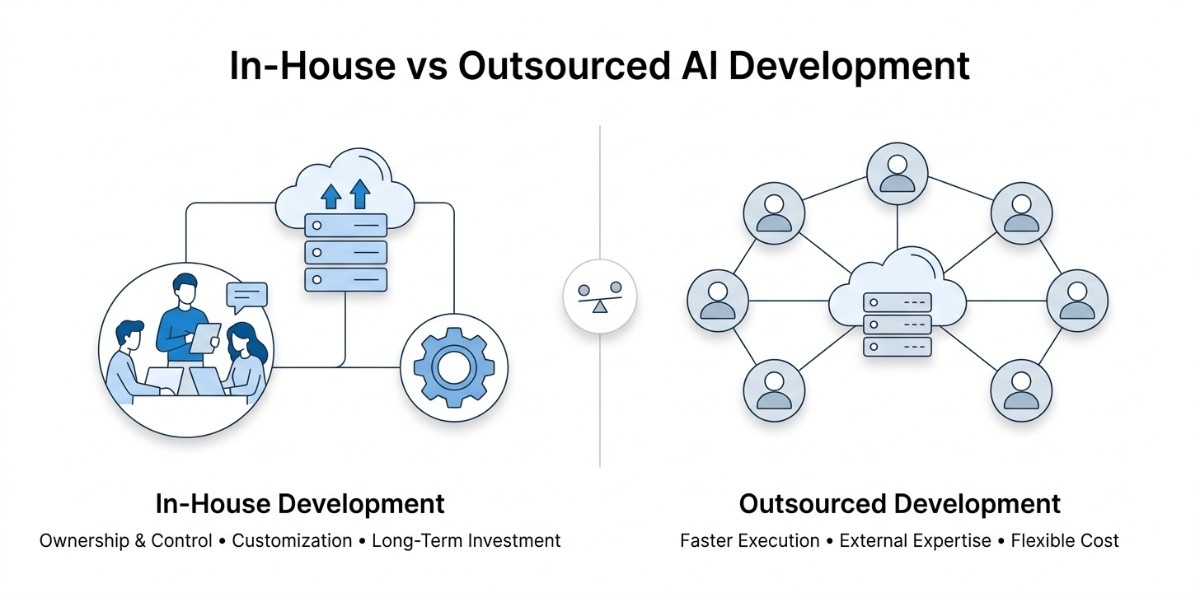
Choosing how to build an AI system is as important as choosing the model itself. The decision between in-house and outsourced development affects not only execution but also long-term flexibility, cost, and performance.
In-House Development
Ownership and Control
Building in-house means your team manages everything from data preparation to model development, deployment, and ongoing improvements. This gives you full control over how the system is designed, how data is handled, and how the solution evolves.
It also allows deeper customisation, especially when the AI system needs to be tightly integrated with internal tools, workflows, or proprietary data.
In contrast, this level of control is harder to achieve when relying on external teams, where decisions are often shared or coordinated.
Cost and Time Efficiency
This level of ownership comes with higher responsibility. It requires hiring or upskilling specialists in areas like data engineering, machine learning, and infrastructure, along with setting up the right development environment.
The investment is ongoing, covering not just development but also maintenance, monitoring, and improvements. Development timelines are typically longer, as building internal capability takes time before results are visible.
Compared to outsourcing, this approach demands more upfront effort and a longer time to reach production.
Best Fit for
In-house development is more suitable for mid to large organizations where AI solutions are a core part of the product or long-term strategy.
It works well when there is an existing technical foundation and a need for strong data control, customization, and deep system integration. Smaller teams or early-stage projects may find this approach resource-intensive.
Overall, in-house development is best suited for organizations that prioritize long-term ownership, control, and deep integration and are prepared to invest in building and maintaining internal expertise.
Outsourced Development
Access to Expertise and Speed
Outsourced development focuses on leveraging external expertise to design, build, and deploy AI systems. Instead of building a team from scratch, you work with professionals who already have experience across tools, models, and real-world implementations.
This allows projects to move faster, as teams can start execution immediately. Compared to in-house development, this approach reduces the time needed to reach a working solution.
Cost and Execution Efficiency
From a cost perspective, outsourcing shifts the investment from long-term hiring and infrastructure to more flexible, project-based spending. The additional advantage of outsourcing is that it's easy to manage budgets, especially in the early stages.
It also reduces the overhead of maintaining a full-time AI team. While there may be less direct control over day-to-day execution, the process is often more streamlined due to established workflows and experience.
Best Fit for
Outsourcing is well-suited for startups, small to mid-sized businesses, or teams exploring AI without wanting to build a full internal capability immediately.
It is also useful when specific expertise is needed for a defined project or when internal resources are limited.
Overall, outsourced development is best suited for situations where speed, flexibility, and access to specialized expertise are more important than building internal capabilities from the start.
Balanced Approach
With a balanced approach, you can keep control where it counts while still getting things done quickly with the help of outside experts. Internal teams work on figuring out what the problem is, using data, and setting the overall direction.
External teams take care of development, optimisation, or scaling. This setup helps you avoid the delays and extra work that come with building everything from scratch while still being able to see how the system is changing.
This approach is especially useful when you want to balance speed with long-term ownership, making it easier to deliver results now while still building for the future.

What Technologies Are Used to Build AI Models
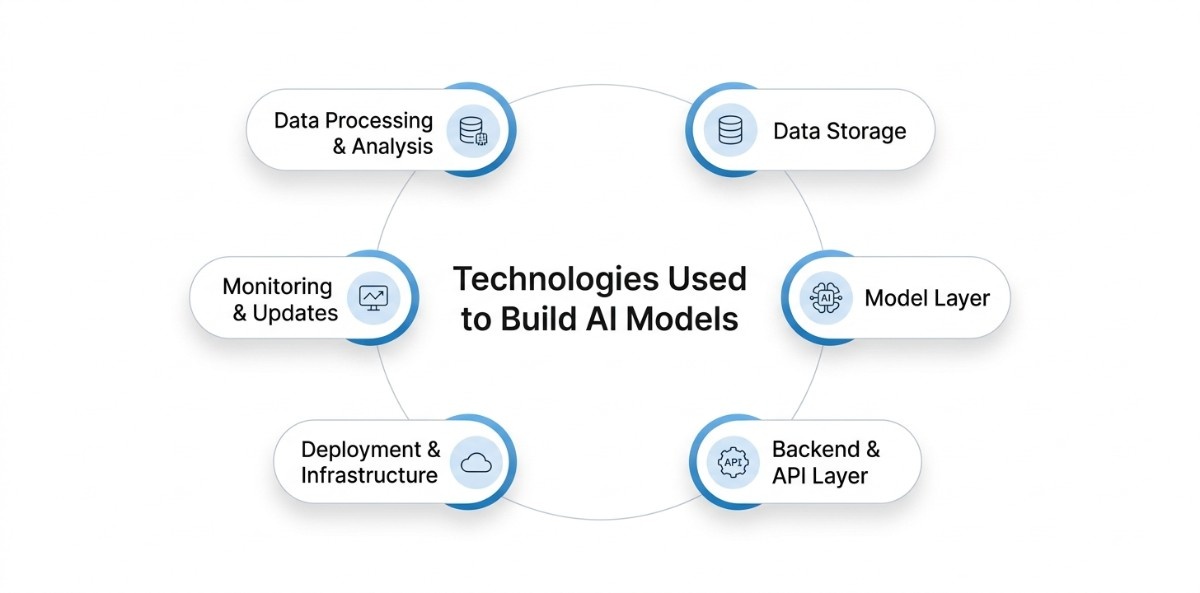
An AI system is built using a set of core layers that handle how data is prepared, how the model runs, and how the system is deployed and maintained. Each layer includes specific tools and components that are commonly used across most AI applications.
Data Processing and Analysis
This layer prepares raw data so it can be used for training and prediction. It includes tools like Pandas and NumPy for handling structured data and performing numerical operations.
It involves cleaning data, which means getting rid of mistakes and duplicates, putting it in a consistent format, and choosing features that will help the model learn well.
It also involves looking at the dataset to observe patterns, distributions, and possible problems, like missing values or imbalances, that could hurt the model's performance.
Data Storage
This layer manages how data is stored and retrieved during both training and real-time usage. Common systems include SQL/NoSQL databases for structured data and vector databases like Pinecone or Weaviate for embedding-based retrieval.
It ensures that large volumes of data can be accessed efficiently without slowing down the system. It also supports use cases where the model needs to retrieve relevant information quickly, such as in recommendation systems or search-based applications.
Model Layer
This is the core layer where the trained AI model operates. It uses frameworks like TensorFlow or PyTorch to process input data and generate outputs such as predictions or classifications.
It handles the execution of the trained model and applies learned patterns to new data. It also includes managing model versions and ensuring that the correct model is used during inference.
Backend and API Layer
This layer connects the AI model to the application. It is typically built using backend frameworks like FastAPI, Flask, or Node.js and exposes the model through APIs.
It handles incoming requests, processes input data, and sends it to the model for inference. It guarantees the return of responses in a structured format suitable for frontend applications or other systems.
Deployment and Infrastructure
This layer provides the environment where the AI system runs. It includes cloud platforms like AWS, Google Cloud, or Azure, along with container tools like Docker.
It makes sure that the model can handle real-world use, like a lot of requests from different users and heavy workloads. It also takes care of the system resources needed to run the model, like processing power, storage, and networking.
Monitoring and Updates
This layer is all about keeping an eye on how well the model works after it has been put into use. MLflow and Prometheus are two tools that keep an eye on the accuracy, performance, and usage patterns of a system.
It helps find problems, like when performance drops or data patterns change over time. It also lets you update and retrain the model with new data to keep it accurate and useful.
Best Tools & Platforms for AI Development
Selecting the right AI tools and platforms depends on what you are building, how much control you need, and how the system will be used. AI development is not based on a single tool but a combination of technologies that handle data, model building, and real-world integration.
Programming Languages
AI development involves more than one language, as different parts of the system require different capabilities such as model building, data handling, and application integration.
Python
Python is the core language used in AI because it supports the complete development flow, from handling raw data to training and deploying models. It reduces the complexity of working with algorithms and allows faster experimentation when testing different approaches.
It is widely adopted because most of the AI libraries and frameworks are built around it, making it easier to work across different stages without switching tools.
In practical use, Python is responsible for writing the entire pipeline. It is used to process data, define models, run training, evaluate results, and connect the trained model to applications.
It also supports building scripts for automation, handling data pipelines, and integrating models into backend systems.
JavaScript
JavaScript is important when AI needs to be integrated into web-based applications where users interact directly with the system. It allows real-time interaction and helps bring AI features into user interfaces.
It is especially useful when responses need to be displayed instantly and when applications require continuous user interaction.
It is used to capture user input, send it to backend systems or APIs, and display model outputs in a structured and usable format. It also plays a role in managing application behavior, updating UI based on model responses, and ensuring smooth interaction between the user and the AI system.
Java
Java is used in AI systems that are part of larger applications, especially in enterprise environments where stability and long-term operation are required. It helps integrate AI into existing backend systems and supports applications that need to run continuously with consistent performance.
It is used to manage backend services, handle data flow across systems, and ensure that AI components work reliably within larger software architectures. It also supports building scalable systems where AI models are integrated with other services such as databases, APIs, and business logic layers.
R
R is used in AI primarily for statistical analysis and data exploration, especially when working with datasets that require deeper analysis before model building.
It is preferred in cases where understanding data distributions, relationships, and patterns is important before applying machine learning models.
It is used to perform statistical modeling, data visualization, and exploratory data analysis, which helps in identifying trends, correlations, and anomalies in the data.
Other languages such as C++ and Julia are also used in specific cases, especially where performance or numerical computation is critical, but Python remains the central choice in most AI workflows.
Machine Learning & Deep Learning Frameworks
AI models are built using different frameworks depending on the type of problem, data, and level of control required during development.
TensorFlow
TensorFlow is used when building models that need to handle large-scale data and be deployed in real-world applications.
It is preferred in cases where consistency, performance, and long-term usage are important, especially when models are expected to run continuously in production systems.
It is used to define model architectures, manage training processes on large datasets, and optimize models for deployment.
It also supports converting trained models into formats that can be integrated into applications and handle real-time or batch predictions.
PyTorch
PyTorch is chosen when flexibility and control during model development are important. It allows developers to modify models while they are being trained, which makes it easier to test different approaches and improve results. This makes it especially useful during experimentation and early stage development.
It is used to build custom models, train them step by step, and debug issues during training.
It allows developers to inspect how the model is learning and make adjustments, which helps in refining performance before deployment.
Scikit-learn
Scikit-learn is used for solving problems that involve structured data where simpler models are effective. It is preferred when the goal is to build models quickly and get clear results without the need for deep learning techniques.
Scikit-learn is used to apply algorithms such as classification, regression, and clustering, and to evaluate model performance using built-in methods.
It is also commonly used to create baseline models, which help in understanding the problem before moving to more complex solutions.
Keras
Keras is used to simplify the process of building and training models, especially when developers want a more readable and straightforward approach.
It is useful when quick development is required without handling complex configurations.
It is used to define model layers, run training processes, and evaluate performance with minimal code. Keras allows developers to build models faster while still supporting more advanced configurations when needed.
Other frameworks, such as XGBoost and LightGBM, are also popular for certain tasks, like modelling structured data, but TensorFlow and PyTorch are still the most popular frameworks for most AI applications.
NLP & Generative AI Frameworks
These frameworks are used when working with text, language, and content generation tasks. They provide access to models that can understand, process, and generate human language.
Hugging Face (Transformers)
Hugging Face is used for language-based tasks because it provides access to pretrained models that already understand patterns in text. This makes it useful when building applications that involve processing or generating language without starting from scratch.
It is commonly chosen when working with tasks that require flexibility and the ability to adapt models to specific datasets.
It is used to load pretrained models, fine-tune them on custom data, and perform tasks such as text classification, summarization, translation, and generation.
It also supports working with different model architectures, allowing developers to experiment and improve results based on the problem.
OpenAI APIs
OpenAI APIs are useful when there is a need to integrate advanced language capabilities quickly without managing the complexity of training and infrastructure.
They are preferred when the focus is on building applications rather than developing models from the ground up.
They are used to process user input, generate responses, and support features such as chat systems, content generation, and automation.
Integration is handled through API calls, which makes it easier to connect these capabilities to existing applications.
LangChain
LangChain in AI works by generating a response that involves multiple steps, such as retrieving data, processing it, and then generating an output. It is useful when building systems that require structured workflows rather than a single model response.
It is used to manage sequences of operations, connect models with external data sources, and control how outputs are generated.
This helps in building applications where context, memory, and step-by-step processing are required for better results.
Other tools, such as Cohere and Anthropic APIs, are also used in similar scenarios, but Hugging Face and OpenAI remain the most commonly used starting points for most applications.
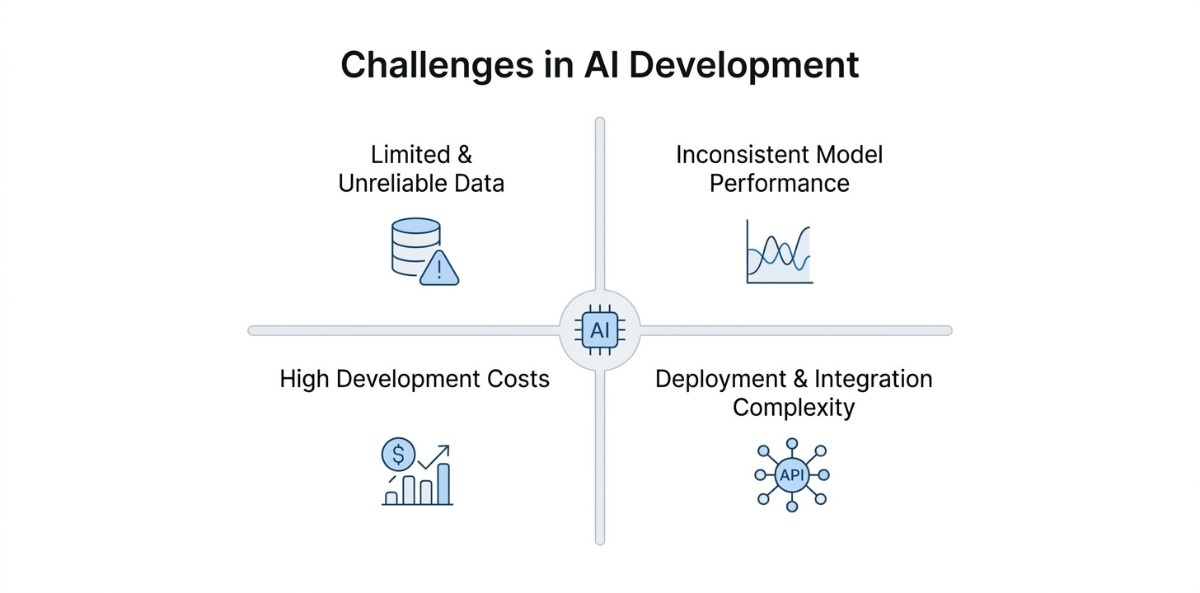
Challenges in AI Development
Building an AI system involves more than just training a model; understanding these common challenges can help you avoid delays and build more reliable systems.
1. Limited and Unreliable Data
The problem with many AI-related tasks is that the data needed is incomplete, not structured, or not properly labeled. Without the right data, even a well-designed model will not perform well.
To solve this problem, many AI-related tasks gather data from different sources, improve data collection methods, and spend time cleaning and labeling the data.
For example, the AI-related task of creating a recommendation system cannot work properly if user behavior data is not properly collected.
2. Inconsistent Model Performance
An AI model may perform well during the development phase, but when the model is exposed to real-world data, the performance may not be as expected. This is often due to the model learning data that does not generalize well.
This can be achieved by using more effective validation techniques and testing the model with different datasets. Regular software and QA testing and evaluation also help maintain the consistency and performance of the model.
For example, a fraud detection model may not perform well if the data used during the development of the model is old, as the model may not have learnt the latest fraud schemes. Hence, the need to update the model with the latest data.
3. High Development and Running Costs
Developing AI systems requires skilled professionals, computing resources, and time, which can increase costs quickly, especially for complex projects.
Costs can be managed by starting with smaller models, using pretrained solutions where possible, and scaling only when needed.
Planning budgets and resource allocation early also makes a difference, as factors like investment and funding directly influence how AI projects are developed and scaled.
For example, instead of building a language model from scratch, many teams use existing APIs to create an AI application at a lower initial cost.
4. Complexity in Deployment and Integration
Even if the model has been created, integrating it into an actual application may be challenging, as it needs to be compatible with existing systems, be able to handle user requests, and be able to run in various environments.
This challenge, in turn, can be addressed through the use of APIs, cloud technology, and the right backend systems that enable proper communication.
A chatbot, for example, would require the integration of the frontend interface with the backend, and the AI model through APIs in order to be able to process user requests and provide quick responses.
Real-World AI Use Cases Across Industries
Real-life examples help relate theory with practice. If you are exploring how to build an AI application, these examples illustrate the application of AI in the real world.
Detecting Diseases Using Medical Data
AI is used in healthcare to analyze medical images and patient data to support early diagnosis. It helps identify patterns in scans and reports, allowing doctors to detect diseases faster and with higher consistency.
In 2026, AI models have shown strong performance in medical imaging, with systems achieving up to 94% accuracy in detecting breast cancer, in some cases outperforming radiologists.
Identifying Fraud in Financial Transactions
AI is used in finance to monitor transactions in real time and detect unusual patterns that may indicate fraud. These systems analyze large volumes of data and continuously adapt to new fraud behaviors.
Recent data shows that 78% of banks are using AI for security and fraud prevention, highlighting how widely AI is applied in financial systems today.
Personalizing Product Recommendations
AI recommendation systems analyze user behavior such as browsing, clicks, and purchase history to suggest relevant products. This improves user experience and increases conversion rates.
A strong example is Netflix, where its recommendation system helps save over $1 billion per year by improving user retention through personalized content suggestions.
Automating Support and User Interactions
AI is widely used in SaaS products to handle customer support, automate repetitive tasks, and improve response time. Chatbots and virtual assistants can manage common queries instantly, allowing teams to focus on more complex issues and improving overall efficiency.
Recent data shows that 92% of customers report positive experiences with AI chatbots, and many companies are using them to handle a large portion of support interactions. In some cases, businesses report that up to 90% of routine queries are resolved without human involvement, which significantly reduces response time and operational workload.
Best Practices for Building AI Applications
Below are a few practical approaches that can help avoid unnecessary complexity and improve results. These practices are based on how real AI systems are developed and improved over time.
Start with a Small and Clear Use Case
Instead of trying to build a complete system at once, it is better to start with a focused problem and build a small system. This ensures that the idea works before investing too much time and effort into it.
For example, rather than attempting to build an AI system, it is better to start with a small feature, such as a chatbot or a recommendation system, and build upon it once it is useful.
Prioritize High-Quality Data
The quality of data is more significant for a machine learning system than the complexity of models. High-quality data is more essential to obtain better results with fewer corrections required later.
In general, a considerable amount of time is spent on improving the quality of the data by correcting errors, labeling, etc., before training models.
Use Existing Models Before Building from Scratch
Building models from scratch is time-consuming and often unnecessary for common use cases. Pretrained models or existing APIs can effectively solve many problems.
For example, if we want to perform tasks like text generation or image recognition, we can utilize the existing tools that are readily available, as this helps us focus on building the application itself.
Plan for Growth and Future Needs
An important consideration is that sometimes an AI system may be required to handle more data and users in the future. Therefore, it is important that the system is designed in such a way that it is flexible and can be scaled up in the future.
One way of doing this is to start with a simple system that can be easily extended in the future without requiring significant modifications.
Conclusion
Building an AI system becomes much easier when the steps involved are well understood, from the definition of the problem to the data, and then the model selection, training, and deployment. Most importantly, one does not have to make everything from scratch, as there are already existing tools that can be used in the development of the AI system. Starting with a small case also helps in the development of the AI system over time.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us