



The Complete Guide to Microservices Design Patterns for Modern Software Architecture



Microservices architecture promises unprecedented agility, the ability to deploy, scale, and evolve parts of your system independently. But without a structured approach, teams often end up building what architects grimly call a "distributed monolith": all the operational complexity of microservices with none of the flexibility.
Design patterns are the antidote. They are proven, battle-tested solutions to the recurring architectural challenges that every distributed system encounters: How do services find each other? How do you keep data consistent when it lives in a dozen databases? What happens when one service goes down?
This structured approach is what drives real outcomes. Today, over 77% of organizations have adopted microservices, and 92% report positive results, including improved agility, resilience, and developer productivity.
A Structured Overview of Microservices Design Pattern Categories
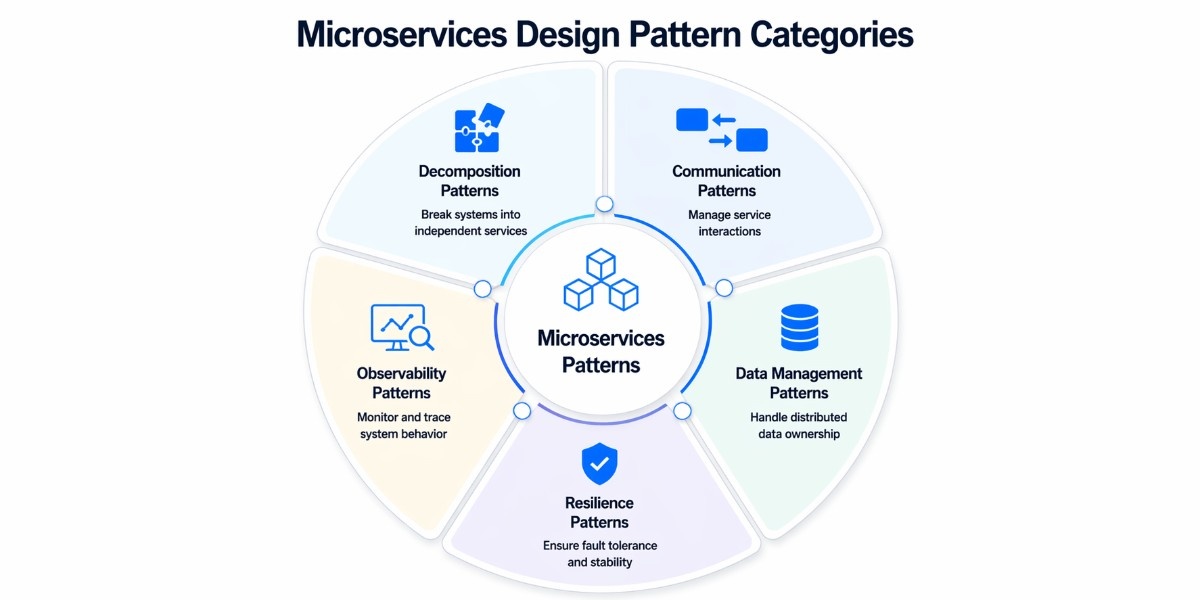
Microservices design patterns aren’t random techniques; they solve different types of problems. Categorizing them gives you a mental model for choosing the right approach instead of mixing patterns blindly.
At a high level, these patterns fall into five core categories:
Decomposition Patterns
These patterns define how to break a monolith into meaningful, independent services. Decomposition patterns guide how you split a system into smaller, independent services aligned with business capabilities or domains.
The goal is to reduce tight coupling and create services that can evolve independently. Poor decomposition is one of the main reasons teams end up with a distributed monolith.
Communication Patterns
These patterns define how microservices talk to each other efficiently and reliably. Once services are split, they need to communicate, either synchronously (via APIs) or asynchronously (via events and messaging). Communication patterns help manage how data flows between services while balancing performance, coupling, and reliability.
Data Management Patterns
These patterns define how services own, manage, and share data across the system. In microservices, each service should control its own data. These patterns address one of the hardest challenges in distributed systems: maintaining consistency without relying on a shared database. They help manage transactions, queries, and data duplication across services.
Resilience Patterns
These patterns define how systems handle failures and remain stable under stress. Failures are inevitable in distributed environments. Resilience patterns ensure that one failing service doesn’t cascade into system-wide outages. They focus on fault tolerance, graceful degradation, and maintaining availability.
Observability & Cross-cutting Patterns
These patterns define how to monitor, trace, and understand system behavior in production. As systems grow, visibility becomes critical. These patterns provide insights into how services behave through logging, tracing, monitoring, and infrastructure-level enhancements, making it easier to debug and maintain complex systems.
Why Categorization Matters Before Choosing Patterns
A common mistake teams make is jumping straight into implementing patterns without understanding the problem they’re trying to solve. This often leads to overengineering or applying the wrong solution.
By thinking in categories first, you can ask better questions:
Are we struggling with service boundaries? → Look at decomposition patterns
Are services tightly coupled through APIs? → Focus on communication patterns
Are we dealing with inconsistent data? → Explore data management patterns
Are failures cascading across services? → Apply resilience patterns
Are we unable to debug production issues? → Invest in observability patterns
This structured approach ensures you’re not just using patterns but the right ones for your system’s needs.
List of Best Microservices Design Patterns
Modern systems rely on a set of proven design patterns to handle complexity and perform effectively. This section highlights the key patterns you need to build and maintain a microservices architecture.
Decomposition Patterns
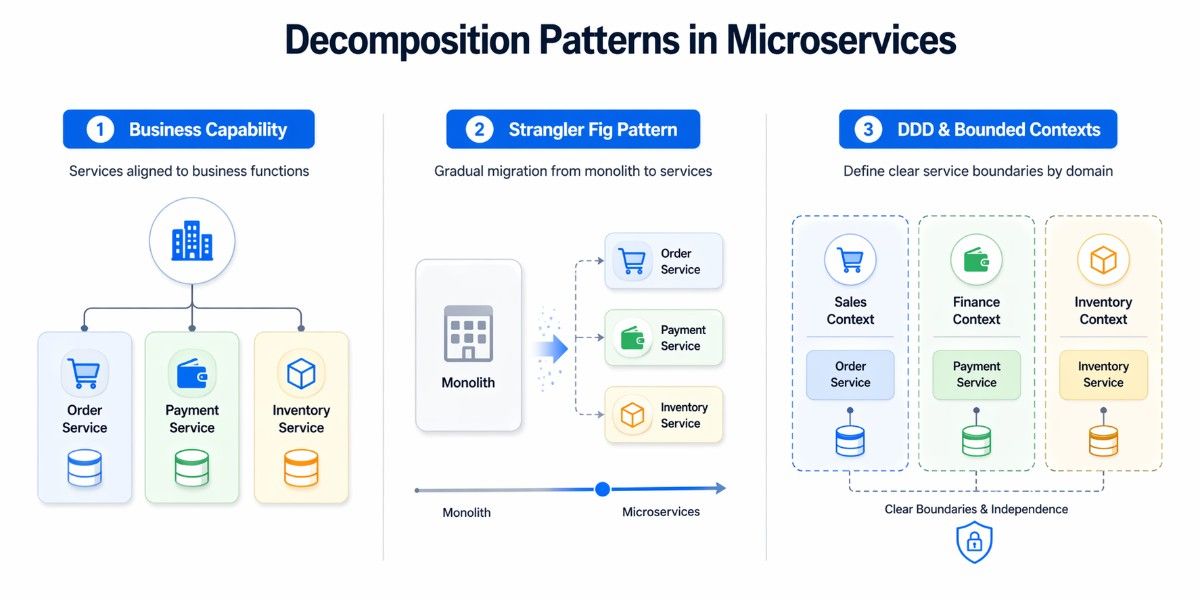
Decomposition patterns answer the most foundational question in microservices: how do you decide where one service ends and another begins? Get this wrong, and you'll either create a distributed monolith (services that are too tightly coupled) or a nanoservice nightmare (services that are too granular to be useful).
Decompose by Business Capability
Decomposing by business capability means structuring your services around what the business actually does. These patterns define how to break a system based on real business functions, not technical layers.
Instead of separating systems by technical concerns such as controllers, databases, or shared utilities, each service is built around a specific business function and contains everything required to operate that function independently.
In a practical scenario, consider how an e-commerce platform is structured. Rather than having a shared backend that handles orders, payments, and inventory within a single system, each of these becomes its own service.
The order service manages the entire lifecycle of an order, from creation to completion. The payment service handles transactions, refunds, and payment validation. The inventory service tracks stock levels and availability. Each of these services owns its logic, its data, and its responsibilities.
E-commerce System (Decomposed by Business Capability)
[ Order Service ] → Order lifecycle management
[ Payment Service ] → Payment processing
[ Inventory Service ] → Stock and availabilityThis approach works particularly well when the business domain is clearly defined and when teams can take ownership of specific capabilities. It allows services to scale independently based on demand; for example, scaling the payment service during high transaction periods without affecting other parts of the system.
More importantly, it reduces unnecessary communication between services. When all related logic is contained within a single boundary, the need for constant cross-service calls decreases, improving both performance and reliability.
Strangler Fig Pattern
Most organizations do not have the luxury of building microservices from scratch. They typically start with a monolithic application that has evolved and supports critical business operations. Replacing such a system in one go is risky and often impractical. The Strangler Fig pattern offers a more controlled and incremental approach.
The idea is to gradually extract functionality from the monolith and replace it with independent services. Instead of rewriting the entire system, you identify specific features or modules and rebuild them as standalone services.
Traffic is then routed to these new services, while the rest of the system continues to operate within the monolith. Over time, as more features are extracted, the monolith becomes smaller until it is eventually phased out completely.
Migration Flow Using Strangler Fig Pattern
Step 1: [ Monolith Application ]
Step 2: Extract Feature
[ Monolith ] → [ Product Service ]
Step 3: Route Requests
Users → Product Service (new)
Users → Monolith (remaining features)
Step 4: Repeat Until Monolith Is ReplacedThis approach is particularly valuable for enterprise systems where downtime is not acceptable and business continuity is critical. It allows teams to modernize their architecture while continuing to deliver features and maintain existing functionality.
A common example is an e-commerce system where the product catalog is extracted first, followed by order management and then payments. Each step reduces the dependency on the monolith and moves the system closer to a fully distributed architecture.
Domain-Driven Design (DDD) & Bounded Contexts
While decomposing by business capability provides a high-level direction, Domain-Driven Design (DDD) offers a more structured way to define service boundaries. It focuses on understanding the business domain deeply and using that understanding to shape the architecture.
One of the central concepts in DDD is the bounded context. A bounded context represents a specific area of the business where a particular model applies. Within this boundary, terms, rules, and data structures are consistent. Outside of it, they may differ.
For example, the concept of an “order” might exist in multiple parts of a system, but its meaning can vary. In the order management context, it represents the lifecycle of a purchase. In the payment context, it may represent a transaction reference.
In the inventory context, it might simply indicate a reservation of stock.
Bounded Contexts in an E-commerce System
[ Order Context ] → Order lifecycle and status
[ Payment Context ] → Transactions and billing
[ Inventory Context ] → Stock managementDDD also introduces the idea of aggregates, which are clusters of related entities treated as a single unit. Aggregates help maintain consistency within a bounded context and define clear rules for how data can be modified.
By aligning microservices with bounded contexts, teams can ensure that each service has a well-defined purpose and minimal overlap with others. This reduces confusion, prevents duplication of logic, and limits the need for excessive communication between services.
In practice, this often translates to designing one microservice per bounded context, allowing each service to evolve independently while still fitting into the larger system.
Communication Patterns
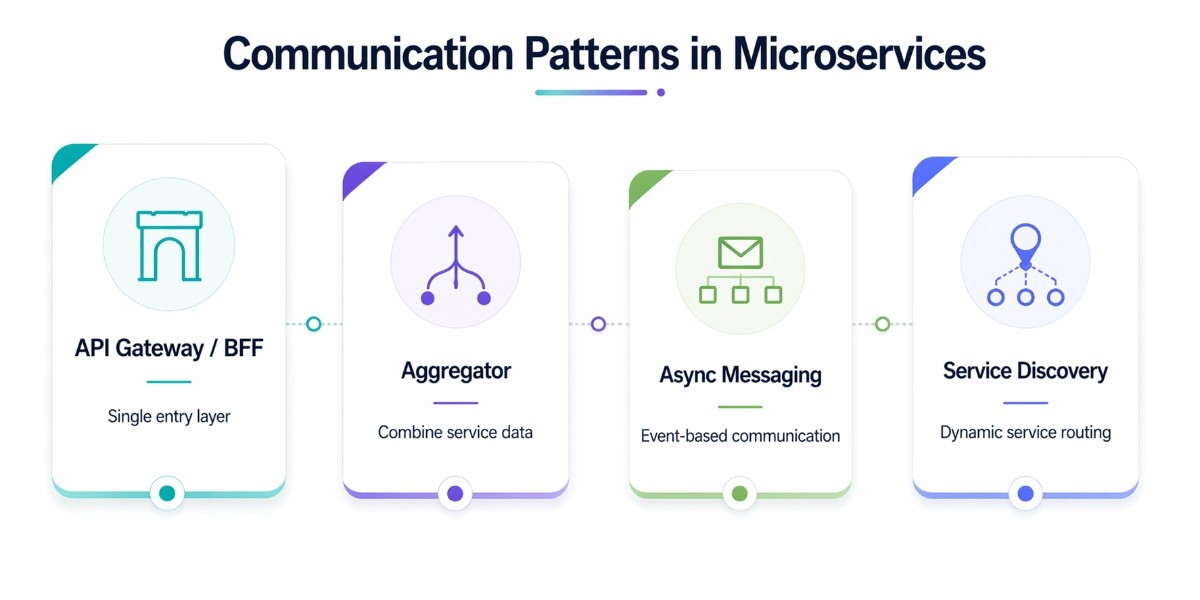
Once services are properly decomposed, the next challenge is how they communicate. In a microservices architecture, every interaction happens over the network, which introduces latency, partial failures, and coordination complexity. The way services interact directly impacts system performance, scalability, and resilience.
This section covers the core patterns that define how requests flow, how data is composed, and how systems remain loosely coupled while still working together effectively.
API Gateway Pattern
In a distributed system, exposing every service directly to clients creates unnecessary complexity. Clients would need to manage multiple endpoints, handle authentication, and combine responses on their own. The API Gateway pattern introduces a single entry point that sits between clients and services, simplifying this interaction.
The gateway centralizes responsibilities such as request routing, authentication, rate limiting, and response transformation. Instead of multiple client calls, a single request is routed internally to the appropriate services, reducing complexity on the client side and improving consistency.
As systems evolve, different client types, such as mobile and web, often require different data formats. This is where the Backend for Frontend (BFF) pattern becomes relevant. A BFF is a specialized backend tailored to a specific client, ensuring that each client receives only the data it needs.
In many architectures, both patterns are used together. The API Gateway handles cross-cutting concerns, while BFF layers optimize responses for individual clients.
There are also cases where introducing an API Gateway is unnecessary. In smaller systems with limited services, it can add avoidable latency and operational overhead.
If not scaled properly, it may also become a bottleneck. Systems that primarily rely on asynchronous workflows may not benefit significantly from a centralized gateway.
Common API Gateway tools vary based on flexibility, scale, and deployment needs. Amazon API Gateway is a fully managed and scalable option best suited for AWS-native systems, while Kong offers strong extensibility through plugins for custom architectures.
NGINX is known for its high performance and works well for lightweight routing, whereas Apigee provides advanced analytics and governance features for enterprise API ecosystems.
Aggregator Pattern
The Aggregator pattern is used when a client requires data from multiple services but should not handle multiple calls or response composition. Instead, a dedicated service collects responses from different services and returns a unified result.
This pattern is particularly useful in user-facing applications where reducing round trips is critical. For example, an e-commerce product page may need product details, pricing, inventory status, and reviews.
Rather than making multiple requests, the aggregator service gathers this information internally and responds with a single payload. Different aggregation strategies can be applied depending on the relationship between services.
Parallel aggregation is used when services are independent and can be called simultaneously.
results = await all([
getProduct(),
getPrice(),
getInventory(),
getReviews()
])Chained aggregation is used when one service depends on the output of another.
product = await getProduct()
inventory = await getInventory(product.id)Branch aggregation applies conditional logic to determine which services to call.
if (user.isPremium) {
offers = await getPremiumOffers()
} else {
offers = await getStandardOffers()
}The table below shows how these strategies differ in terms of performance and behavior:
The Aggregator pattern is often confused with the API Gateway, but their roles are different. The gateway acts as a system entry point, while the aggregator focuses specifically on combining data from multiple services. In many architectures, the gateway routes requests to an aggregator when response composition is required.
Asynchronous Messaging
These patterns define how services communicate without waiting for immediate responses.
Asynchronous messaging removes the need for services to wait on each other. This idea builds directly on how event-driven, non-blocking execution works at the runtime level. Instead of direct calls, services communicate by publishing messages or events that other services consume independently. It improves performance and reduces the risk of cascading failures.
The table below highlights the key differences between synchronous and asynchronous communication:
A simple example can clarify this difference. In a synchronous flow, an Order Service would call a Payment Service and wait for confirmation before proceeding.
In an asynchronous flow, the Order Service publishes an “Order Created” event, and the Payment Service processes it independently without blocking the original request.
Core asynchronous messaging patterns
1. Publish-Subscribe (Pub-Sub)
A producer publishes a message to a topic. All subscribers to that topic receive the message independently. This is the backbone of event-driven architectures. One "Order Placed" event can simultaneously trigger inventory reservation, payment processing, and notification sending.
2. Message Queue (Point-to-Point)
Messages are placed in a queue and consumed by exactly one consumer. If you have 10 consumers, each message is processed by only one of them; perfect for load-balanced task processing like email sending or report generation.
Common tools used for asynchronous communication each serve different needs. Apache Kafka is best for high-throughput, event-driven systems, while RabbitMQ suits reliable task processing and background jobs. Amazon SQS offers a fully managed, scalable option for simple cloud-based messaging.
Service Discovery Pattern
In dynamic environments, service instances are constantly changing due to scaling and restarts. Hardcoding service locations leads to failures as soon as these changes occur. Service discovery allows services to locate each other dynamically through a registry. These patterns help define how services dynamically locate each other in a changing environment.
The table below explains the two primary approaches to service discovery:
A simple example illustrates its importance. When a Payment Service needs to call an Order Service, which is a classic upstream to downstream dependency, it does not rely on a fixed address. Instead, it queries the service registry to locate an available instance.
Instead, it queries the registry to find an available instance. If one instance fails, another is automatically selected, ensuring uninterrupted communication.
Common tools for service discovery help services dynamically locate each other in distributed systems. Consul provides service discovery along with configuration management, while Netflix Eureka is widely used in JVM-based ecosystems.
Kubernetes offers built-in service discovery and load balancing for containerized environments.
Even with well-defined service boundaries, poor communication design can introduce latency, increase failure risk, and create tight coupling. These patterns ensure that services interact efficiently, scale smoothly, and remain resilient as the system grows.
Data Management Patterns
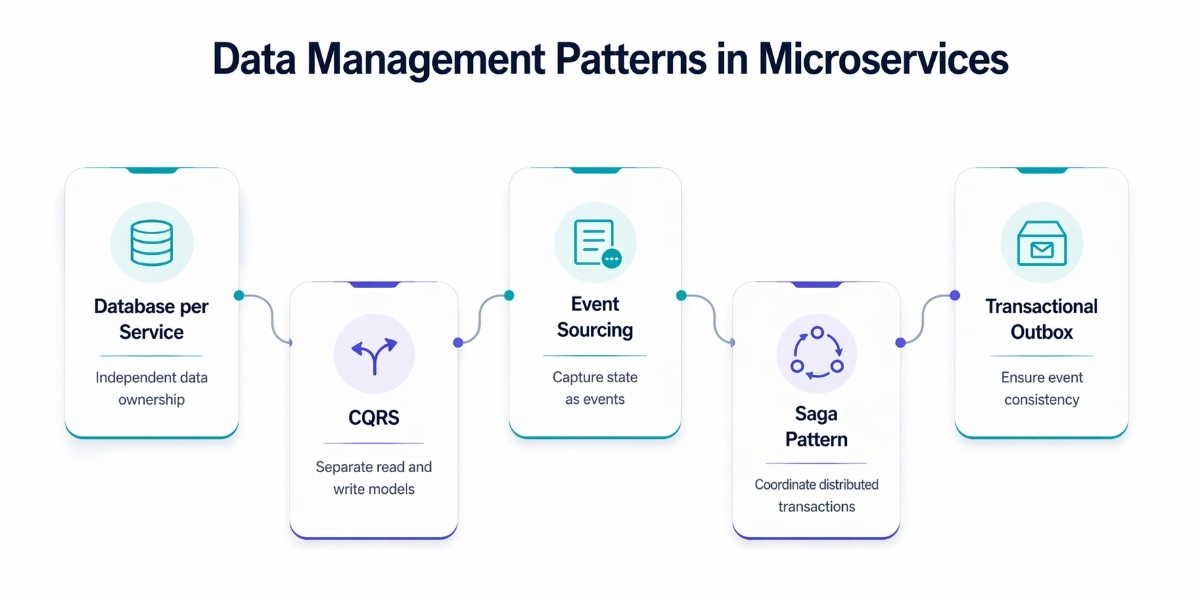
Data management is one of the hardest parts of microservices architecture. Unlike monolithic systems, where a single database ensures consistency, microservices distribute data across multiple services. Each service owns its data, which improves autonomy and scalability, but introduces challenges around consistency, duplication, and coordination.
These patterns define how data is stored, accessed, and synchronized across services without breaking system reliability.
Database per Service
In microservices, each service should have full ownership of its data. This means no shared database across services. Instead, every service manages its own schema and storage, ensuring loose coupling and independent evolution.
For example, in an e-commerce system, the Order Service manages order data, the Payment Service manages transactions, and the Inventory Service manages stock. Each service operates independently without directly accessing another service’s database.
This approach allows teams to choose the most suitable database for their specific needs—a concept known as polyglot persistence.
The table below shows how different database types align with service needs:
While this pattern improves independence, it introduces new challenges. Cross-service queries become difficult because data is no longer centralized.
For example, generating a combined view of orders and payments requires coordination across services. Data duplication is also common, as services may store copies of data to optimize performance.
To handle these challenges, this pattern is often combined with other approaches such as CQRS and Event Sourcing. Instead of querying multiple services directly, systems maintain read-optimized views or propagate changes through events.
CQRS (Command Query Responsibility Segregation)
CQRS separates the responsibility of handling commands (writes) from queries (reads). Instead of using a single model for both operations, the system maintains distinct models optimized for each.
In traditional systems, the same database handles both reads and writes. This can become inefficient when read traffic is significantly higher than write traffic. CQRS solves this by allowing separate data models, one optimized for writing data and another optimized for reading it.
This pattern is especially useful in systems with high read to write ratios, such as dashboards, reporting systems, or user-facing applications with heavy query loads.
Real-world example: E-commerce order history
When a customer places an order (Command side), you need strict validation: check inventory, verify payment, and enforce business rules. That process writes to a normalized PostgreSQL database.
But when a customer views their order history page (Query side), they need a fast, pre-joined view: order items, product images, shipping status, all in one call.
CQRS lets you maintain a denormalized read model (in MongoDB or a Redis cache) that's perfect for this query, updated asynchronously whenever an order event is published.
// COMMAND — PlaceOrderCommand (write operation)
public record PlaceOrderCommand(
Guid CustomerId,
List<OrderItem> Items
) : IRequest<Guid>;
public class PlaceOrderCommandHandler : IRequestHandler<PlaceOrderCommand, Guid>
{
public async Task<Guid> Handle(PlaceOrderCommand cmd, ...)
{
var order = new Order(cmd.CustomerId, cmd.Items);
await _orderRepository.SaveAsync(order);
await _eventBus.PublishAsync(new OrderCreatedEvent(order.Id));
return order.Id;
}
}
// QUERY — GetOrderHistoryQuery (read operation)
public record GetOrderHistoryQuery(Guid CustomerId) : IRequest<List<OrderSummaryDto>>;
public class GetOrderHistoryHandler : IRequestHandler<GetOrderHistoryQuery, ...>
{
public async Task<List<OrderSummaryDto>> Handle(GetOrderHistoryQuery query, ...)
{
// Reads from denormalized read model — fast, pre-joined
return await _readDb.Orders
.Where(o => o.CustomerId == query.CustomerId)
.Select(o => new OrderSummaryDto(o.Id, o.Total, o.Status, o.Items))
.ToListAsync();
}
}However, CQRS introduces additional complexity. Maintaining separate models requires synchronization between read and write data. For simple CRUD applications, this added complexity often outweighs the benefits.
Event Sourcing
Event Sourcing changes how data is stored. Instead of saving the current state of an entity, the system records every change as an event. The current state is then derived by replaying these events.
Traditional databases store the current state: an Order record holds the current status of that order. Event Sourcing stores every change as an immutable event: OrderPlaced, PaymentConfirmed, ItemShipped, OrderDelivered. The current state is derived by replaying these events from the beginning.
This creates a complete, immutable audit trail of everything that ever happened in your system, something that has enormous value for debugging, compliance, and business analytics.
Key benefits of Event Sourcing
- Complete audit trail: You can answer "what was the state of order 123 at 3 pm on March 15th?", impossible with traditional databases without complex audit tables.
- Event replay: Rebuild any read model by replaying events. Add a new projection without migrating data, just replay from the beginning.
- Temporal queries: Query state at any point in the past.
- Natural integration with CQRS: Events are the mechanism that keeps the read model up to date.
- Debugging: Reproduce any production bug by replaying the exact sequence of events.
CQRS + Event Sourcing together
These two patterns are almost always used together in production systems. Event Sourcing provides the event log (write side). CQRS uses those events to build and update optimized read models (query side). Kafka or a similar event streaming platform is the typical glue.
Saga Pattern
In microservices, a single business operation often spans multiple services. Traditional transaction mechanisms like two-phase commit (2PC) are not suitable because they require locking resources across services, which leads to latency, reduced availability, and failure risks.
The Saga pattern solves this by breaking a transaction into a sequence of smaller, local transactions. Each service completes its part and publishes an event. If any step fails, compensating transactions are triggered to undo previously completed actions.
There are two main approaches to implementing sagas: choreography and orchestration. The difference lies in how the flow of the transaction is managed.
The table below compares these two approaches:
To understand compensating transactions, consider an order process. The Order Service creates an order, the Payment Service processes payment, and the Inventory Service reserves stock.
If the payment step fails, the system triggers compensating actions such as canceling the order and releasing reserved inventory. This ensures the system remains consistent without relying on distributed locks.
Important: Saga design rules
- Every step must be idempotent: If a step is retried due to a network failure, running it twice must produce the same result as running it once.
- Compensating transactions must always succeed: Design compensations to be retry-safe and never fail permanently.
- Use the Transactional Outbox pattern (next section) to reliably publish events as part of each local transaction.
Modern tools such as Temporal, Camunda, and Eventuate are commonly used to implement orchestration-based sagas.
Compared to 2PC, the Saga pattern avoids blocking and allows services to operate independently. Instead of enforcing strict consistency, it ensures eventual consistency, which is more practical in distributed systems.
Transactional Outbox Pattern
One of the common challenges in microservices is the dual-write problem. A service may need to update its database and publish an event at the same time. If one operation succeeds and the other fails, the system becomes inconsistent.
The dual-write problem is when a service needs to both (a) update its database AND (b) publish an event to a message broker; there is no distributed transaction covering both.
If the database write succeeds but the message broker publish fails (or vice versa), your system is in an inconsistent state, the event is lost, and other services never react to it.
Let's see an example, The Dual-Write Problem: Service writes to DB ✓ Service publishes to Kafka ✗ (network failure) Result: Database updated, but downstream services never notified → data inconsistency
Transactional Outbox Solution:
1. In a SINGLE database transaction: → Write business data (e.g., insert Order row) → Write event to Outbox table (e.g., insert "OrderCreated" event row) (Both succeed or both fail, atomically)
2. A separate "Outbox Relay" process reads the Outbox table and publishes pending events to the message broker 3. After confirmed publish, mark the Outbox row as "published."
-- Outbox table (created once per service)
CREATE TABLE outbox_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
event_type VARCHAR(255) NOT NULL,
payload JSONB NOT NULL,
created_at TIMESTAMPTZ DEFAULT NOW(),
published BOOLEAN DEFAULT FALSE
);
-- Service code: single atomic transaction
BEGIN;
INSERT INTO orders (id, customer_id, status) VALUES (...);
INSERT INTO outbox_events (event_type, payload)
VALUES ('OrderCreated', '{"orderId":"...","customerId":"..."}');
COMMIT;
-- If anything fails, BOTH inserts roll back — no inconsistency
-- Outbox relay (runs separately, e.g., via Debezium CDC or polling)
SELECT * FROM outbox_events WHERE published = FALSE ORDER BY created_at;
-- For each row: publish to Kafka, then mark published = TRUEIn practice, this pattern is often implemented using Apache Kafka along with Debezium. Debezium monitors database changes and publishes events, ensuring consistency between the database and the messaging system.
This approach guarantees that events are eventually delivered without requiring complex coordination logic, making it a key pattern in event-driven architectures.
Resilience Patterns
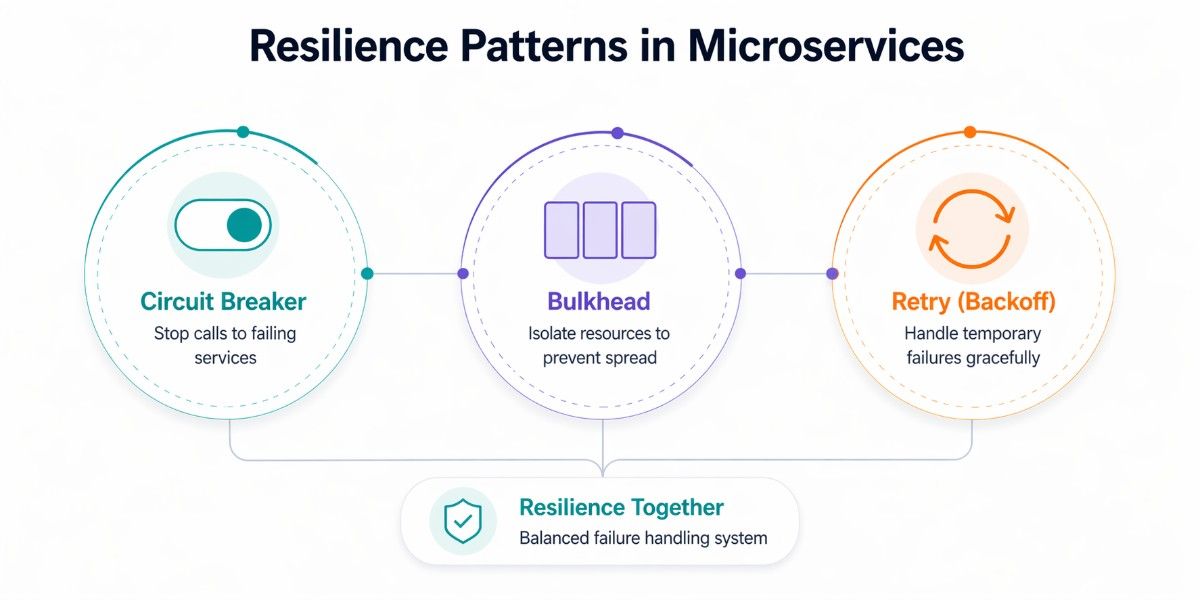
Resilience patterns ensure that a microservices system continues to function even when parts of it fail. In distributed environments, failures are not rare events; they are expected. Network timeouts, service outages, and sudden traffic spikes can all disrupt normal operations. Without proper safeguards, a single failing service can cascade across the system.
These patterns focus on isolating failures, controlling load, and maintaining system stability so that user experience and business operations are not severely impacted.
Circuit Breaker Pattern
In a microservices system, services often depend on each other. If one service becomes slow or unavailable, repeated calls to it can overload the system and amplify the failure. The Circuit Breaker pattern prevents this by temporarily blocking calls to a failing service.
Instead of continuously retrying a failing request, the circuit breaker monitors failures and changes its state based on system health.
The diagram below represents how the circuit transitions between states:
Closed → Open → Half-Open
Closed: Requests flow normally
Open: Requests are blocked (fail fast)
Half-Open: Limited requests allowed to test recovery When the system is healthy, the circuit remains closed, and requests pass through normally. If failures exceed a threshold, the circuit moves to the Open state, where requests are immediately rejected to avoid further strain.
After a cooldown period, the circuit enters the Half-Open state, allowing a small number of test requests. If these succeed, the circuit closes again; if not, it reopens. This pattern is not just about technical stability; it directly impacts business outcomes.
For example, in an e-commerce system, if a payment service is failing, a circuit breaker can prevent repeated retries that overload the system. Instead, the system can fail fast and show a fallback message, protecting the overall user experience and preventing revenue loss due to system-wide outages.
Common tools used to implement this pattern include Resilience4j for Java-based systems, Polly for .NET applications, and Hystrix, which is now considered legacy but historically influential.
Bulkhead Pattern
The Bulkhead pattern is named after the watertight compartments in a ship's hull, if one compartment floods, the others remain sealed, and the ship stays afloat. The Bulkhead pattern applies this concept to software: partition resources (thread pools, connection pools, semaphores) so that a misbehaving dependency can only consume its allocated resources, never starving other parts of the system.
To understand better, let's see a practical example
WITHOUT Bulkhead: Service A shares one thread pool for all downstream calls: [Thread pool: 100 threads]
├─ Payment API calls (slow): consumes all 100 threads
├─ Inventory API calls: 0 threads available → timeout
└─ User API calls: 0 threads available → timeout → One slow dependency takes down ALL outgoing calls
WITH Bulkhead: [Payment thread pool: 30 threads] ← Payment API slow? Only 30 threads affected
[Inventory thread pool: 30 threads] ← Still functional
[User thread pool: 20 threads] ← Still functional
[General pool: 20 threads] ← Still functional
There are two types of bulkhead implementation
1. Thread pool isolation: Each downstream dependency gets its own thread pool. Expensive if you have many dependencies, but it provides the strongest isolation.
2. Semaphore isolation: Limit the number of concurrent calls to a dependency using a semaphore. Less resource-intensive than thread pool isolation, suitable for fast in-process calls.
Bulklhead is useful when one slow or failing dependency is causing cascading timeouts across unrelated operations, and also when you have high-priority and low-priority workloads sharing the same service, and you need to protect the high-priority path. In combination with the Circuit Breaker for comprehensive resilience coverage.
Circuit Breaker + Bulkhead + Retry = The Resilience Trinity
These three patterns are almost always deployed together. Retry handles transient failures (try again, maybe it was a blip). Circuit Breaker handles persistent failures (stop trying, give the service time to recover). Bulkhead handles resource contention (limits the blast radius regardless). Use all three.
Retry with Exponential Backoff
Retries are a common way to handle temporary failures, but naive retry strategies can make problems worse. If a service is already under stress, immediately retrying failed requests increases load and can lead to a complete outage.
Exponential backoff solves this by increasing the delay between retries. Instead of retrying instantly, the system waits for progressively longer intervals before each attempt. This gives the failing service time to recover.
Jitter is often added to this strategy to randomize retry timing. Without jitter, multiple clients may retry at the same intervals, creating spikes of traffic. With jitter, retries are spread out, reducing the chance of overwhelming the system again.
For example, instead of retrying at fixed intervals like 1 second, 1 second, 1 second, exponential backoff might retry at 1 second, 2 seconds, 4 seconds, and so on, with slight randomness added.
This pattern is often combined with the Circuit Breaker. While retries handle temporary failures, the circuit breaker prevents endless retries when a service is consistently failing. Together, they create a balanced approach to failure handling.
Observability & Cross-Cutting Patterns
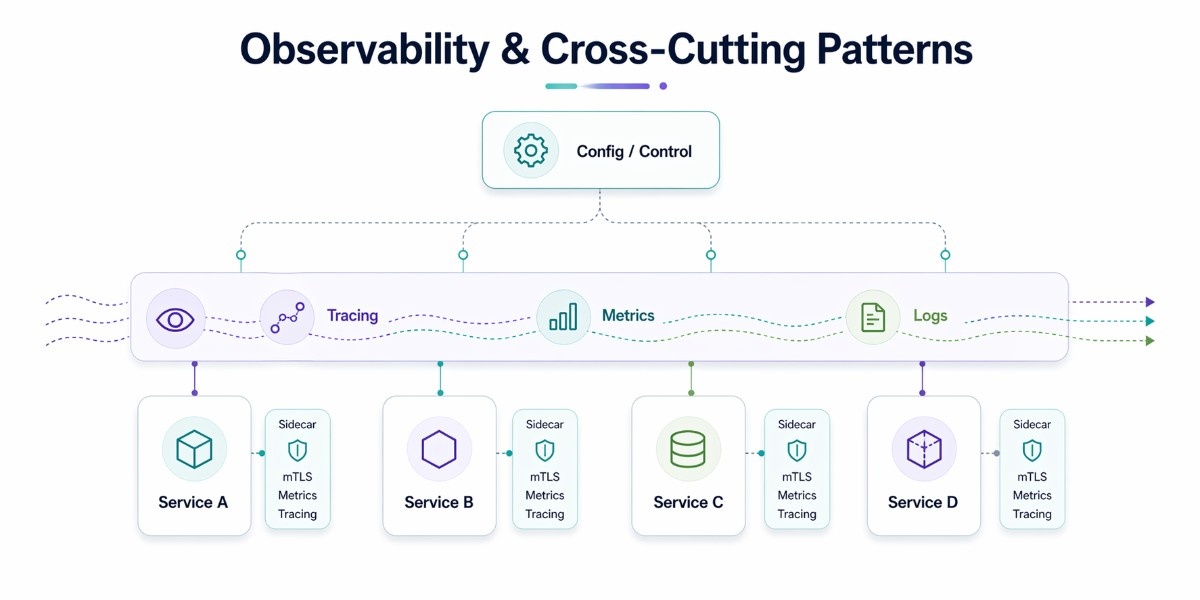
You cannot manage what you cannot observe. In a microservices system with 20, 50, or 200 services, a single user request may traverse a dozen services. When something goes wrong, and it will, you need to see exactly what happened, where, and why. Observability patterns are what make that possible.
Sidecar Pattern & Service Mesh
The Sidecar Pattern
Instead of implementing logging, metrics collection, mTLS, or service discovery logic inside every single microservice, the Sidecar pattern deploys a second container alongside each service container in the same pod (in Kubernetes).
This sidecar container handles the cross-cutting concern transparently, intercepting inbound and outbound traffic, collecting telemetry, and handling encryption, without any changes to the main service's code.
Kubernetes Pod
┌─────────────────────────────────────────┐
│ Pod │
│ ┌──────────────────┐ ┌──────────────┐ │
│ │ Main Service │ │ Sidecar │ │
│ │ (your code) │ │ (Envoy/Istio)│ │
│ │ │ │ │ │
│ │ Business logic │ │ - mTLS │ │
│ │ only │ │ - Tracing │ │
│ │ │ │ - Retries │ │
│ │ │ │ - Metrics │ │
│ └──────────────────┘ └──────────────┘ │
└─────────────────────────────────────────┘
All traffic flows through the sidecar transparentlyService Mesh
When every service has a sidecar, and those sidecars are managed by a central control plane, you have a Service Mesh. In 2026, service meshes like Istio, Linkerd, and Cilium are standard in enterprise microservices environments. They provide:
Mutual TLS (mTLS) is Automatic, certificate-based encryption and authentication for all service-to-service communication, zero-trust networking at the infrastructure level.
Traffic management is intelligent routing, canary deployments, A/B testing, and fault injection, all configured via YAML without code changes.
Observability is automatic distributed tracing, metrics collection, and traffic visualization across all services. Circuit breaking & retries are configurable at the mesh level, no library code required in services.
Distributed Tracing & Observability
Observability in microservices rests on three pillars, logs, metrics, and traces. In 2026, OpenTelemetry (OTel) has become the universal standard for instrumenting services across all three dimensions, language-agnostically.
- Logs: Structured log output from each service. Use OTel-compatible logging (JSON format, correlation IDs) and aggregate in a central platform (Loki, Elastic, Datadog).
- Metrics: Quantitative measurements (request rate, error rate, latency percentiles). Collect with Prometheus, visualize with Grafana.
- Traces: The path of a single request through multiple services, with timing for each hop. Jaeger, Zipkin, and Tempo are popular backends. Each request gets a unique Trace ID that propagates through all service calls.
Externalized Configuration
Instead of hardcoding values such as credentials, API keys, or feature flags into the application, these are managed externally and injected at runtime.
Sensitive data is handled securely using tools like HashiCorp Vault or AWS Secrets Manager, while application configuration is managed through systems such as Kubernetes ConfigMap or cloud parameter stores.
Feature flag platforms like LaunchDarkly or Unleash further extend this by allowing functionality to be enabled or disabled without redeploying services, making systems more adaptable and easier to operate at scale.
How to Choose the Right Microservices Design Pattern for Your System
Choosing the right microservices pattern is about solving the right problem with the right approach. A clear decision framework helps avoid unnecessary complexity and keeps the architecture aligned with real system needs.
Identify the Core System Requirement
The starting point for selecting any pattern is understanding what your system actually needs to achieve. Each pattern is designed to solve a specific problem, and applying it without that context leads to overengineering.
When a system needs to combine data from multiple services into a single response, the Aggregator pattern becomes the natural fit. If the challenge is maintaining consistency across distributed services, the Saga pattern provides a structured way to manage that flow.
Similarly, when performance issues arise due to high read traffic, CQRS helps by separating read and write models for better efficiency.
Focusing on the core requirement ensures that patterns are introduced with intent. Instead of adding layers proactively, you apply them where they directly improve performance, reliability, or user experience.
Evaluate Architectural Constraints
Beyond the immediate requirement, system-level constraints play a critical role in shaping pattern selection. Factors such as scalability, client diversity, and system evolution determine how patterns should be applied and combined.
When migrating from a monolithic system, for instance, the Strangler Fig pattern enables a gradual transition without disrupting existing functionality. In systems serving multiple clients with different data needs, combining BFF with an API Gateway ensures optimized responses.
When service dependencies introduce instability or unpredictable failures, resilience patterns like Circuit Breaker and Bulkhead help isolate failures and maintain system stability. Evaluating these constraints early ensures that the architecture remains adaptable as the system grows and evolves.
Avoid High-Impact Anti-Patterns
Choosing the right pattern also means avoiding decisions that undermine the architecture. A common issue is the distributed monolith, where services are split but remain tightly coupled through excessive synchronous communication.
This increases complexity without delivering the benefits of microservices. Another critical mistake is using a shared database across services. While it may simplify initial development, it tightly couples services, limits independent scaling, and makes schema changes risky.
Adopting patterns like Database per Service and event-driven communication helps maintain clear boundaries and long-term flexibility. Avoiding these pitfalls is essential to preserving the scalability and independence that microservices are designed to achieve.
Combine Patterns Based on Context
In real-world systems, patterns are rarely used in isolation. Effective architectures combine multiple patterns, each addressing a specific concern within the system.
A system handling high traffic and distributed workflows might use CQRS to optimize read performance, Saga to manage consistency, and asynchronous messaging to decouple services. The key is to ensure that each pattern serves a defined purpose and integrates cleanly with others, rather than adding unnecessary layers.
This approach keeps the architecture practical, maintainable, and aligned with both technical and business goals.
The goal is not to use more patterns, but to use the right ones at the right time. A problem-driven approach ensures that your system remains scalable, resilient, and easy to evolve as requirements change.
.svg&w=256&q=75)
Common Mistakes in Microservices Design and How to Avoid Them

Microservices offer flexibility and growth potential, but without the right approach, they can quickly introduce more complexity than value. Many teams adopt microservices expecting immediate benefits, only to face performance issues, operational overhead, and tightly coupled systems. Most of these problems come from a few common design mistakes.
Overusing Microservices
One of the most frequent mistakes is breaking a system into too many services too early. Not every application needs a microservices architecture. When services are created without clear boundaries or real scaling needs, the system becomes harder to manage than a well-structured monolith.
This often leads to increased deployment complexity, more infrastructure overhead, and fragmented logic across services. Instead of improving agility, it slows down development and makes coordination between teams more difficult. Microservices should be introduced when there is a clear need for independent scaling, team ownership, or system modularity.
Excessive Network Calls Between Services
Microservices communicate over the network, which is inherently slower and less reliable than in-process communication. A poorly designed system may require multiple service calls to complete a single user request, increasing latency and the risk of failure.
This issue is commonly seen when services are too granular or tightly dependent on each other. The result is a chain of synchronous calls that slows down the system and creates cascading failures. Patterns like Aggregator or asynchronous messaging can reduce unnecessary communication and improve overall performance.
Ignoring Data Consistency
In distributed systems, maintaining data consistency is one of the biggest challenges. Treating microservices like a monolith, expecting immediate consistency across services, often leads to fragile designs.
Without proper patterns such as Saga or event-driven communication, systems can end up with conflicting data or failed transactions. Designing for eventual consistency and clearly defining data ownership ensures that services remain reliable without relying on tightly coupled database operations.
Lack of Observability
As systems grow, visibility becomes critical. Without proper logging, monitoring, and tracing, it becomes difficult to understand how services behave or where failures occur.
A lack of observability turns debugging into guesswork, especially when requests flow across multiple services. Implementing structured logging, metrics, and distributed tracing ensures that issues can be identified and resolved quickly, maintaining system reliability.
These mistakes often appear manageable in the early stages but become significant obstacles as the system grows. Addressing them early ensures that microservices deliver their intended benefits, flexibility, resilience, and maintainability, without introducing unnecessary complexity.
Language Specific Tools and Libraries for Microservices Pattern Implementation
While microservices design patterns are language-agnostic, their implementation depends heavily on the ecosystem you are working in. Each platform provides its own set of libraries and tools that make it easier to apply these patterns in practice. Understanding these options helps bridge the gap between architectural concepts and real-world implementation.
.NET Ecosystem
In the .NET ecosystem, building microservices with C# gives you several mature tools that support microservices patterns out of the box. For resilience, Polly is widely used to implement retries, circuit breakers, and fallback strategies.
For API Gateway scenarios, Ocelot and YARP provide flexible routing and request handling capabilities. Messaging and event-driven communication are commonly handled using MassTransit, which integrates well with brokers like RabbitMQ and Azure Service Bus.
These tools make it easier to implement patterns such as Circuit Breaker, API Gateway, and asynchronous messaging within .NET-based systems.
Java / Spring Ecosystem
The Java and Spring ecosystem offers a comprehensive set of tools for building microservices. Resilience4j is commonly used for implementing fault tolerance patterns like circuit breakers and retries.
Spring Cloud Gateway provides routing, filtering, and security features for managing APIs. For event-driven architectures, Apache Kafka and Kafka Streams are widely adopted for handling high-throughput messaging and real-time data processing.
This ecosystem is particularly strong for building scalable, event-driven systems with built-in support for many microservices patterns.
Node.js Ecosystem
When combining Node.js with a frontend like React in a microservices setup, lightweight and flexible tools are often preferred. Express Gateway is commonly used to implement API Gateway patterns with minimal overhead.
For background processing and messaging, libraries like Bull provide efficient job queues backed by Redis. These tools are well-suited for fast-moving applications where simplicity and performance are key priorities.
Choosing the right tools for your ecosystem ensures that design patterns can be implemented efficiently without reinventing solutions. While the patterns remain the same across platforms, the microservices framework you build on determines how easily and effectively they can be applied in real-world systems.
Conclusion
Microservices design patterns help structure complex systems into manageable parts. Decomposition patterns define service boundaries; communication patterns govern interactions; data management patterns ensure consistency; resilience patterns handle failures; and observability & cross-cutting patterns provide visibility and control. The effectiveness of your architecture depends on choosing the right combination for your system’s needs, rather than applying everything at once.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us