



Machine Learning Mobile App Development Guide: Process, Use Cases & Cost



From Model to Production Application
Practical guidance for taking models from notebook to live app
What Is Machine Learning App Development?
Machine learning app development is the process of building software applications that learn from data and improve their behavior over time, without being explicitly reprogrammed for every new scenario.
Unlike traditional apps that follow fixed rules, ML-powered apps adapt, predict, and personalize based on patterns they discover in real-world data.
In plain terms: a traditional app does exactly what you code it to do. An ML app figures out what to do by learning from examples, then keeps getting better the more it's used.
Why Businesses Are Investing in ML Apps in 2026
Machine learning is no longer limited to experimental AI projects or large tech companies. In 2026, businesses across ecommerce, fintech, healthcare, logistics, and SaaS are integrating machine learning directly into mobile and web applications to improve user experiences, automate operations, and create data-driven products that continuously improve over time.
The shift is largely driven by changing customer expectations. Users now expect apps to:
- personalize content in real time
- predict preferences and intent
- automate repetitive tasks
- deliver faster and smarter experiences
- adapt dynamically to behavior patterns
Traditional rule-based applications struggle to deliver this level of intelligence at scale, which is why machine learning in apps has become a major product and business investment priority.
Businesses Are Scaling AI Faster Than Ever
Enterprise adoption of AI and machine learning has accelerated significantly over the last few years. As per the global AI Survey, 78% of organizations now use generative AI in at least one business function, yet only a small percentage of companies have fully scaled AI across workflows and products
This creates a major opportunity window for businesses building production-ready machine learning mobile apps and AI-powered digital platforms.
At the same time, the machine learning market itself is growing rapidly. According to Statista Market Insights, the global machine learning market is projected to grow from approximately $105 billion in 2025 to more than $568 billion by 2031, reflecting strong enterprise investment in AI infrastructure, intelligent automation, and predictive software systems.
The 3 Biggest Reasons Businesses Are Adding ML to Apps
1. Revenue growth through personalization
ML enables apps to personalize every interaction based on user behavior, preferences, and history. Amazon's recommendation engine, a machine learning model, drives an estimated 35% of its total revenue.
Spotify's Discover Weekly keeps users subscribed by predicting what they want to hear before they know themselves. For your app, this means customized dashboards, real-time content recommendations, and dynamic pricing that adapts to user segments. Personalization drives engagement, and engagement drives revenue.
2. Cost reduction through automation
ML automates tasks that would otherwise require human review at scale, customer support triage, document processing, fraud flagging, and inventory reordering. McKinsey estimates generative AI alone could deliver $2.6 - 4.4 trillion in annual value, primarily through operational savings in customer operations, software engineering, and R&D. In practical terms: a fintech app that uses ML to flag suspicious transactions reduces manual review costs by 40–60% while catching more fraud faster.
3. Competitive moat through proprietary data advantage
Here is the compounding effect most businesses overlook: every user interaction trains your ML model. The more your app is used, the smarter it gets. This creates a flywheel that competitors without ML cannot replicate, even if they copy your features. Your model trained on your users' data is something only you have.
Modern smartphones now include built-in AI processing capabilities that allow machine learning models to run directly on the device instead of relying entirely on cloud servers. This makes it possible for apps to process tasks such as image recognition, voice input, recommendations, and predictive features locally on the phone.
As a result, apps can respond faster, continue working with limited internet connectivity, reduce server dependency, and handle sensitive user data more privately. These improvements are making machine learning apps more practical and easier to deploy across industries.
Step by Step Process on How to Build a ML Apps
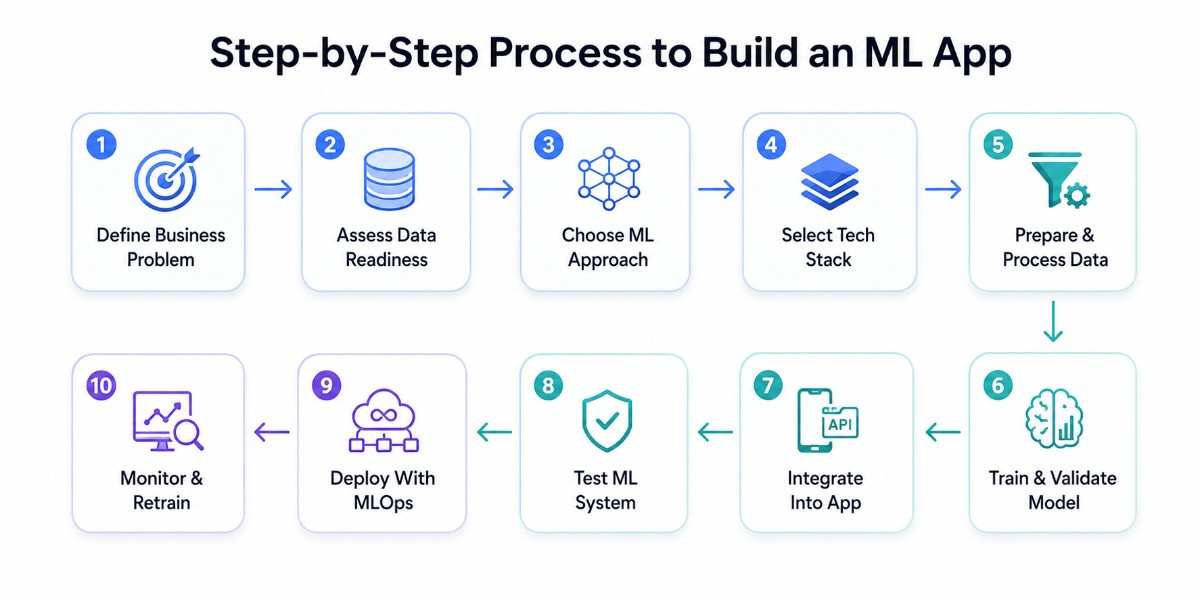
Building an ML app is not a linear sprint; it is an iterative cycle. The process involves data science, software engineering, product thinking, and ongoing operations. Here is how professional ML development teams approach it from conception to production.
Define the Business Problem First
The development process should begin with a clearly defined business problem rather than a broad goal of “adding AI” to an application. Businesses first need to identify the exact outcome they want to improve, such as reducing fraud, increasing retention, automating support workflows, improving recommendations, or predicting customer behavior.
This stage is important because machine learning is not always the right solution for every problem. In many cases, simple rule-based systems may be more practical and cost-effective. Defining measurable success metrics early helps teams avoid unnecessary complexity and keeps the project aligned with business goals, user needs, and expected returns.
Assess Data Readiness and Compliance
Data is the foundation of every machine learning system. Before development begins, teams must assess whether they have enough accurate and usable data to train reliable models.
This process usually involves reviewing data sources, identifying missing or inconsistent records, checking labeling requirements, and understanding how information will be collected and stored. For industries such as fintech, healthcare, and e-commerce, compliance requirements also become a major part of planning.
Businesses should evaluate factors such as user consent, data privacy regulations, encryption standards, and retention policies under frameworks like GDPR and India’s DPDP Act. Even advanced models struggle to perform well if the underlying data is incomplete or poorly structured.
Choose the Right ML Approach
Once the business objective and data readiness are clear, the next step is selecting the appropriate machine learning method for the use case.
Different ML approaches solve different types of problems. Supervised learning is commonly used for predictions and classifications; unsupervised learning helps identify hidden patterns and anomalies; reinforcement learning supports adaptive systems; and generative AI powers conversational experiences and content generation.
The right choice depends on factors such as the type of data available, the complexity of predictions, infrastructure limitations, explainability requirements, and whether the application needs real-time inference. Choosing the correct ML approach early helps reduce unnecessary development effort and improves long-term maintainability.
Select the Tech Stack and Infrastructure
The technology stack plays a major role in determining how efficiently the machine learning application performs after deployment.
Modern ML applications often combine mobile frameworks such as Flutter, React Native, Swift, or Kotlin with backend technologies like Python, FastAPI, and Node.js. Machine learning frameworks such as TensorFlow and PyTorch are widely used for model development, while TensorFlow Lite and Core ML enable on-device inference for mobile applications.
At this stage, teams also decide whether the application will rely on cloud-based inference, on-device processing, or a hybrid deployment model. These infrastructure decisions directly affect latency, operational costs, offline functionality, and user privacy.
Prepare and Process the Data
Raw business data is rarely ready for machine learning models without preprocessing. Before training begins, datasets must be cleaned, transformed, and organized in a format the model can understand properly.
This stage may involve removing duplicate records, handling missing values, balancing datasets, normalizing information, and extracting features that improve prediction quality. Feature engineering is especially important because model performance depends heavily on how accurately the input data reflects real-world behavior patterns.
For example, a fintech app may use transaction frequency and spending anomalies as fraud detection signals, while an e-commerce app may analyze browsing history and purchase patterns for recommendation systems.
Train and Validate the Model
Once the dataset is prepared, the model training process begins. During training, the algorithm learns patterns from historical data and adjusts internal parameters to improve prediction accuracy.
However, training alone is not enough. The model must also be evaluated carefully to ensure it performs reliably in real-world conditions rather than only on training data. Teams typically validate models using metrics such as accuracy, precision, recall, latency, and false positive rates.
Testing edge cases is equally important because machine learning systems often encounter unpredictable user behavior after deployment. A model that performs well in controlled environments may still fail under production conditions if it has not been validated properly.
Integrate the Model Into the App
After validation, the trained model is integrated into the mobile or web application using APIs or on-device inference engines.
At this stage, machine learning becomes part of the actual user experience. The integration layer must support fast predictions, secure communication, and stable request handling without affecting application performance.
For mobile applications, teams often optimize models for lower memory usage, reduced battery consumption, and faster inference speeds. This is especially important for applications that require offline functionality or real-time predictions directly on the device.
A well-planned integration process helps intelligent features feel like a natural part of the product experience instead of separate add-ons.
Test the App and ML System
Testing machine learning applications involves much more than standard software QA. Businesses must evaluate both the technical stability of the application and the behavioral reliability of the ML system.
This includes testing prediction quality, inference speed, API reliability, traffic handling, device compatibility, and low-confidence outputs. Real-world testing is important because machine learning systems often behave differently once exposed to live user interactions and changing behavioral patterns.
Teams should also assess how the system responds to unusual inputs, incomplete data, and unexpected edge cases to reduce inaccurate predictions and improve user trust.
Deploy With an MLOps Pipeline
After testing is complete, the application and machine learning infrastructure are deployed into production environments.
Modern ML deployments rely heavily on MLOps practices to manage model versioning, automated deployment pipelines, monitoring systems, rollback strategies, and infrastructure management. These workflows help engineering teams maintain consistency as models evolve and new training data becomes available over time.
Without structured deployment and monitoring workflows, maintaining machine learning systems becomes increasingly difficult as applications grow.
Monitor, Retrain, and Improve Continuously
Machine learning systems require ongoing monitoring even after deployment because user behavior, business conditions, and data patterns constantly change.
Over time, these changes can lead to model drift, where prediction quality gradually declines. Businesses therefore need continuous monitoring systems that track model accuracy, inference latency, anomaly rates, infrastructure health, and business KPIs.
When performance begins to drop, models may need retraining using updated datasets and new behavioral information. Continuous monitoring and retraining help ensure the application remains accurate, reliable, and useful as user expectations and business requirements evolve.
Real World ML App Use Cases by Industry
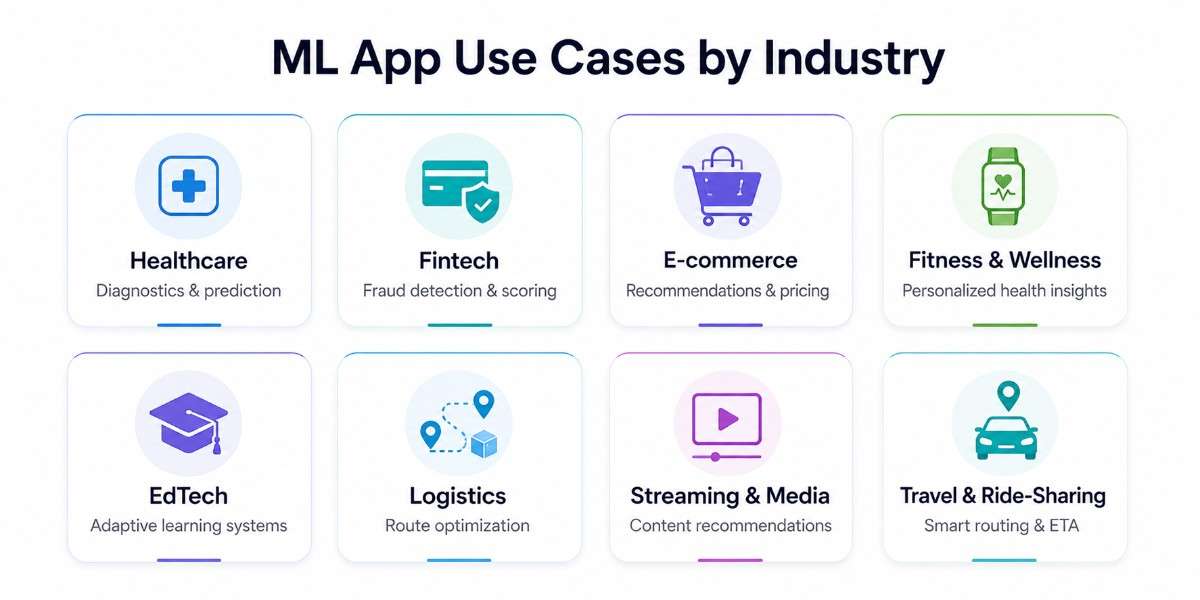
Machine learning is now a core part of modern mobile and web applications across industries. Businesses are using ML-powered apps to improve personalization, automate decisions, process real-time data, and make digital products more responsive to user behavior.
From healthcare diagnostics to logistics optimization, machine learning applications are expanding rapidly because they help businesses improve efficiency, user engagement, and operational decision-making at scale.
Healthcare
Machine learning is helping healthcare applications analyze medical data more efficiently and support faster clinical decision-making.
ML models are widely used for diagnostic imaging, patient risk scoring, disease prediction, and drug discovery by identifying patterns within large medical datasets.
For example, deep learning systems can analyze X-rays, CT scans, and MRIs to detect abnormalities more quickly and consistently. Predictive models are also used to identify high-risk patients based on medical history and behavioral data.
A strong real-world example is Google Health, which uses AI and deep learning technologies for medical imaging analysis and healthcare research applications.
Fintech
Machine learning has become a major part of fintech applications because financial systems generate large amounts of transactional and behavioral data in real time.
ML models are commonly used for fraud detection, credit scoring, transaction monitoring, and algorithmic trading.
Fraud detection systems analyze spending behavior, device activity, transaction history, and location signals to identify suspicious activity instantly. Financial institutions also use predictive models to improve lending decisions and risk analysis.
AI-powered fraud detection systems are expected to generate more than $10 billion in cost savings globally by 2027 through improved fraud prevention and reduced false positives.
E-commerce
E-commerce platforms rely heavily on machine learning to personalize shopping experiences and improve operational efficiency.
ML systems are widely used for recommendation engines, intelligent search, dynamic pricing, inventory forecasting, and customer segmentation, and the role of gen AI within e-commerce is now expanding those capabilities further.
Recommendation engines analyze browsing behavior, purchase history, and engagement patterns to suggest products users are more likely to buy. Retailers also use predictive analytics to forecast demand and improve inventory planning.
A well-known example is Amazon Shopping, where machine learning powers recommendations, search rankings, and pricing systems.
Fitness and Wellness
Machine learning is increasingly used in fitness and wellness applications to create more personalized health experiences. These systems analyze user activity, workout history, sleep data, and wearable device metrics to deliver tailored recommendations and behavioral insights.
ML-powered fitness apps can detect unusual health patterns, recommend adaptive workout plans, and monitor long-term activity trends based on user behavior.
For example, Fitbit uses machine learning to analyze sleep quality, activity levels, and health metrics collected through wearable devices.
EdTech Applications
Educational technology platforms use machine learning to personalize learning experiences based on student engagement and performance patterns. ML systems help identify learning gaps, predict academic performance, and adjust educational content dynamically for different users.
Adaptive learning platforms can modify lesson difficulty and recommendations depending on how students interact with exercises and quizzes.
A widely recognized example is Duolingo, which uses machine learning to personalize lessons and optimize learning paths based on user progress and engagement.
Logistics and Supply Chain
Machine learning helps logistics and transportation companies process real-time operational data more efficiently. ML models are commonly used for route optimization, predictive maintenance, delivery forecasting, and demand prediction.
Navigation systems analyze traffic patterns, historical travel behavior, and live road conditions to improve ETA predictions and reduce delays. Predictive maintenance systems also help identify potential vehicle issues before breakdowns occur.
For example, Google Maps uses machine learning and real-time traffic analysis to optimize route recommendations and predict travel times.
Streaming and Media Platforms
Streaming platforms use machine learning extensively to personalize content recommendations and improve user engagement. These systems analyze watch history, listening behavior, search activity, and interaction patterns to recommend relevant content in real time.
Recommendation engines help users discover content more efficiently while increasing retention and session duration.
A leading example is Spotify, which uses machine learning for music recommendations, playlist generation, and personalized listening experiences, part of a much wider shift in how AI is reshaping media and entertainment at every level.
Similarly, Netflix uses ML-powered recommendation systems to personalize movie and series suggestions based on viewing history and engagement patterns.
According to Netflix research, its recommendation engine helps save an estimated billion dollars annually by improving user retention and reducing subscriber churn.
Travel and Ride-Sharing
Machine learning plays a major role in transportation and mobility applications by improving route planning, optimizing pricing, and forecasting demand.
Ride-sharing platforms use ML models to predict traffic conditions, estimate arrival times, match drivers efficiently, and adjust pricing based on demand patterns.
A strong example is Uber, which uses machine learning for ETA prediction, route optimization, fraud prevention, and dynamic pricing systems.
Cybersecurity Applications
Cybersecurity platforms increasingly rely on machine learning to identify suspicious activity and respond to threats faster than traditional rule-based systems.
ML systems continuously analyze network activity, login patterns, device behavior, and access requests to detect anomalies in real time. This helps reduce response times and improve threat detection accuracy.
Many enterprise security platforms now use machine learning to improve fraud prevention, reduce false positives, and strengthen large-scale security monitoring systems.
Why These Use Cases Matter
These examples show that machine learning is no longer limited to experimental AI projects. Businesses across industries are using ML-powered applications to improve decision-making, personalize user experiences, automate repetitive workflows, and process real-time data more effectively.
As mobile devices and AI infrastructure continue to improve, machine learning apps are becoming more practical and widely adopted across both consumer and enterprise applications.
Types of Machine Learning Used in Mobile Apps
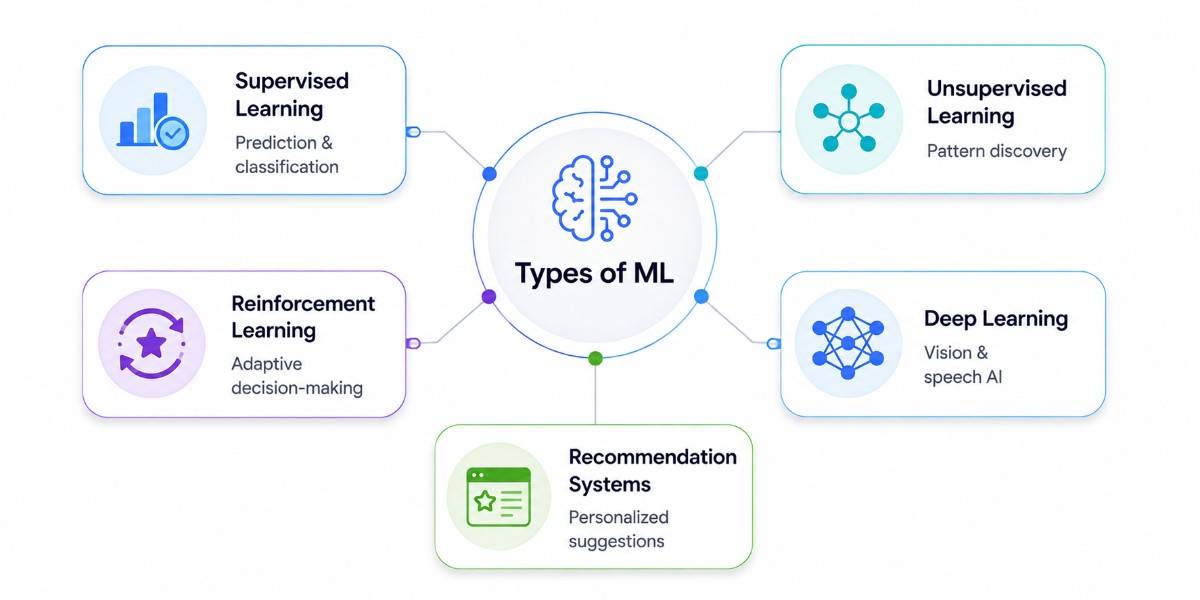
Different machine learning techniques are used to solve different kinds of problems inside mobile applications. The right approach depends on the type of data available, the complexity of the task, and the kind of experience the application is designed to deliver.
Modern machine learning apps often combine multiple ML methods together instead of relying on a single model. For example, an e-commerce app may use recommendation systems for personalization, deep learning for image search, and generative AI for conversational support.
Supervised Learning
Supervised learning is one of the most widely used machine learning methods in mobile applications. In this approach, models are trained using labeled datasets where the correct outcomes are already known. The system learns patterns from historical examples and uses them to make predictions on new data.
This method is commonly used for fraud detection, credit scoring, spam filtering, customer behavior prediction, and recommendation systems. For example, a payment application may train its model using historical transactions labeled as either legitimate or fraudulent to identify suspicious activity in real time.
Supervised learning works best for prediction-focused tasks where historical data and expected outcomes are already available.
Unsupervised Learning
Unsupervised learning works with unlabeled data instead of predefined outputs. Rather than predicting a specific result, the model identifies hidden patterns, similarities, and unusual behaviors within the dataset automatically.
Mobile apps commonly use unsupervised learning for customer segmentation, behavioral analysis, clustering, and anomaly detection. For example, an e-commerce app may group users with similar browsing and purchasing behavior to improve personalization and product recommendations.
This approach is especially useful when businesses have large amounts of behavioral data but limited labeled datasets.
Reinforcement Learning
Reinforcement learning improves decision-making through continuous interaction and feedback. The system learns by testing actions and evaluating outcomes using rewards or penalties, gradually improving its behavior over time.
This approach is commonly used in recommendation systems, gaming apps, navigation systems, and adaptive user experiences. For example, a streaming platform may continuously refine content recommendations based on how users interact with suggested videos or playlists.
Reinforcement learning is useful for applications that need to adapt dynamically based on user behavior and changing conditions.
Deep Learning
Deep learning is a branch of machine learning that uses neural networks to process complex data such as images, speech, video, and natural language.
Many advanced mobile app features rely on deep learning, including facial recognition, voice assistants, speech-to-text systems, object detection, and image enhancement. Smartphone camera applications, for example, use deep learning for scene recognition and image optimization.
Deep learning is widely used for computer vision, speech processing, and natural language understanding tasks where traditional ML models struggle with large and complex datasets.
Recommendation Systems
Recommendation systems analyze user preferences, browsing behavior, and engagement patterns to deliver personalized suggestions in real time.
Streaming platforms use recommendation engines to suggest music and videos, ecommerce apps recommend products, and social media platforms personalize feeds based on interaction history. These systems help improve engagement, retention, and content discovery.
Modern recommendation systems often combine supervised learning, deep learning, and behavioral analytics to continuously improve personalization quality across mobile applications.
Tech Stack Required for ML App Development
The technology stack behind a machine learning app plays a major role in how efficiently the application performs, how easily models can be deployed, and how well the system handles real-world usage.
In 2026, most ML-powered applications rely on a combination of mobile frameworks, backend infrastructure, machine learning libraries, cloud platforms, and deployment tools.
Programming Languages Used in ML App
Python remains the most widely used language for machine learning because of its strong ecosystem of AI frameworks, data processing libraries, and model training tools, though the choice of language depends on your use case, and each option has meaningful trade-offs.
Most ML models are built and trained using Python-based libraries such as TensorFlow, PyTorch, Scikit-learn, and XGBoost.
For mobile app development, Swift is commonly used for iOS applications, while Kotlin is widely used for Android development.
Cross-platform frameworks such as Flutter and React Native are also frequently used to build ML-powered mobile apps from a shared codebase.
Backend systems often use Python, Node.js, or Go for handling APIs, inference requests, authentication, and data pipelines.
Machine Learning Frameworks
Machine learning frameworks are used to train, optimize, and deploy models. TensorFlow and PyTorch remain the most widely adopted frameworks in 2026, with a broader set of libraries used for generative AI and data science, because they support everything from deep learning to production deployment workflows.
TensorFlow is commonly used for large-scale ML systems and mobile deployment through TensorFlow Lite, while PyTorch is widely preferred for research-heavy and deep learning applications.
Scikit-learn is still widely used for structured data problems such as classification, clustering, and predictive analytics.
For mobile inference, frameworks such as TensorFlow Lite, Core ML, and ONNX Runtime Mobile help optimize models for smartphones and edge devices.
Frontend and Mobile Development Tools
The frontend layer is responsible for how users interact with machine learning features inside the application. Flutter and React Native are commonly used for cross-platform app development because they reduce development time while supporting Android and iOS solutions from a single codebase.
Native mobile development remains important for applications that require advanced hardware-level optimization, real-time processing, or deep integration with device capabilities. Swift is commonly used for iOS AI applications, while Kotlin is preferred for Android-based ML apps.
Applications using on-device AI often integrate directly with device hardware such as cameras, microphones, sensors, and AI processing units.
Cloud Platforms and Infrastructure
Cloud infrastructure is widely used for model training, storage, deployment, and inference management in machine learning applications, and how that infrastructure is structured has a direct impact on performance, cost, and how easily the system scales.
Platforms such as AWS, Google Cloud, and Microsoft Azure provide services for GPU-based model training, API hosting, analytics, and large-scale data processing.
Many businesses also use managed ML platforms such as AWS SageMaker, Google Vertex AI, and Azure Machine Learning to simplify deployment, monitoring, retraining, and infrastructure management.
These services help engineering teams handle complex ML workflows without managing the entire infrastructure manually.
Databases and Data Processing Tools
Machine learning apps rely heavily on data pipelines and storage systems. SQL databases such as PostgreSQL and MySQL are commonly used for structured data, while NoSQL databases such as MongoDB are useful for handling large volumes of unstructured or semi-structured information.
Modern ML applications also use data processing tools such as Apache Spark, Kafka, and Airflow for handling streaming data, event processing, and automated workflows.
Vector databases are increasingly important in 2026 for AI search and generative AI applications because they help store and retrieve embeddings efficiently, and choosing the right database for your ML system is a decision that directly affects retrieval speed, scalability, and cost.
Deployment and MLOps Tools
Deploying machine learning systems requires more than simply training a model. Businesses also need workflows for monitoring, versioning, retraining, and maintaining models in production environments.
Docker and Kubernetes are commonly used for containerization and infrastructure management, while tools such as MLflow, Kubeflow, and Weights & Biases help manage experiments, model tracking, and deployment workflows.
MLOps practices have become increasingly important because machine learning systems require continuous updates as user behavior and data patterns evolve over time.
On-Device AI and Edge ML Tools
On-device AI has become increasingly important in 2026 as businesses focus more on offline functionality, lower latency, and improved data privacy. Instead of sending every request to cloud servers, machine learning models can now run directly on smartphones and edge devices.
Frameworks such as TensorFlow Lite, Core ML, MediaPipe, and ONNX Runtime Mobile help optimize models for mobile hardware and local inference.
These technologies are commonly used in applications that rely on facial recognition, voice assistants, image processing, offline translation, and real-time object detection.
Modern smartphones now include dedicated AI hardware that improves on-device processing performance and reduces dependency on cloud-based inference for many real-time ML tasks.
Cost of Machine Learning App Development
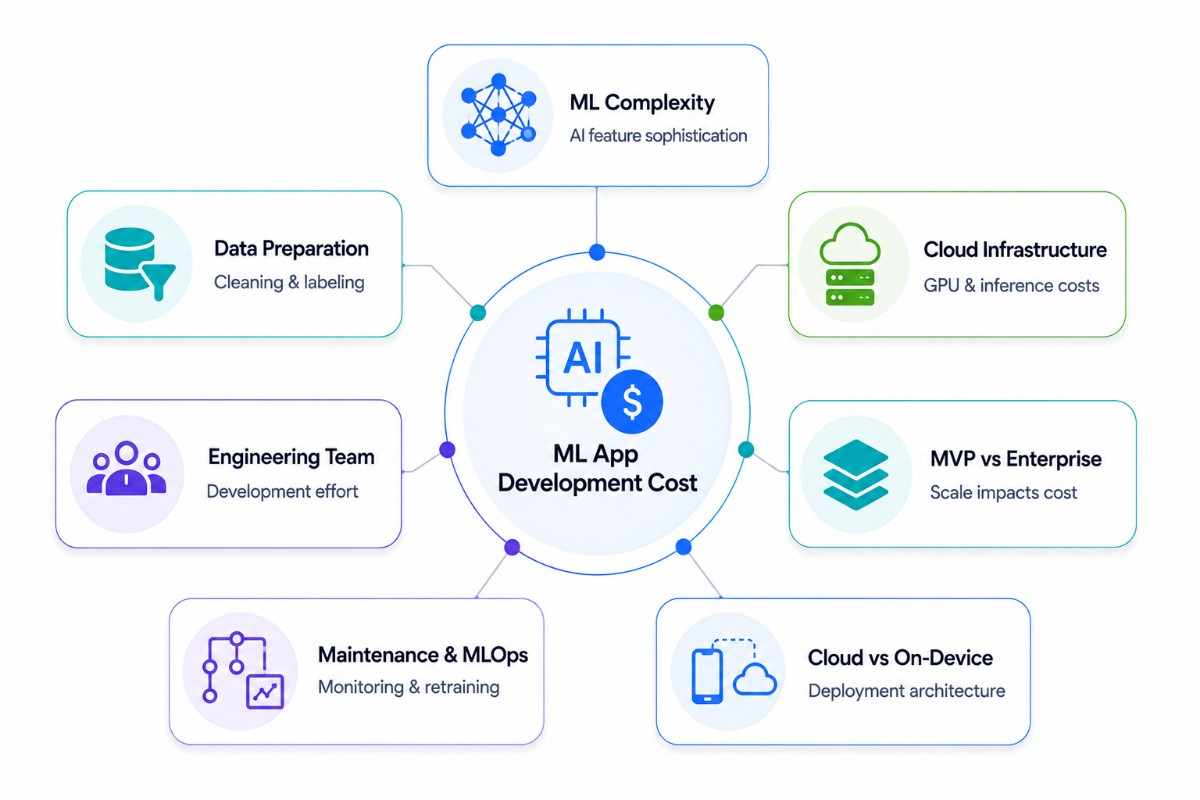
The cost of machine learning app development can vary significantly depending on the type of ML functionality, infrastructure requirements, data readiness, and long-term operational needs. Unlike traditional applications, ML-powered systems involve additional layers such as model training, inference infrastructure, monitoring pipelines, and continuous retraining.
A simple recommendation engine or predictive analytics feature will cost far less than a real-time AI assistant, computer vision system, or generative AI application processing thousands of requests continuously. Because of this, businesses should evaluate both the initial development cost and the ongoing infrastructure expenses before starting an ML project.
ML Feature Complexity
One of the biggest factors affecting development cost is the complexity of the machine learning functionality itself.
Applications using real-time recommendations, fraud detection, image recognition, conversational AI, or deep learning models require more engineering effort, testing, and infrastructure compared to basic analytics systems.
Generative AI applications are usually more expensive because they involve large language models, prompt orchestration, retrieval systems, and GPU-intensive inference pipelines.
Data Preparation and Labeling
Machine learning systems depend heavily on high-quality datasets. In many projects, a significant amount of time is spent collecting data, cleaning inconsistencies, labeling records, and organizing datasets into usable formats before model training even begins.
If businesses do not already have structured and usable datasets available, data preparation can become one of the most time-consuming and expensive stages of development.
Cloud Infrastructure and Inference
Infrastructure decisions directly affect both development and operational costs. Many ML applications rely on cloud-based infrastructure for model training, inference APIs, storage, analytics, and real-time processing.
Applications processing large amounts of user activity or predictions continuously often require GPU-powered servers and scalable inference pipelines, which increase infrastructure expenses over time.
Cloud costs become especially important for generative AI and deep learning applications with high inference usage.
Development Team and Engineering Effort
Machine learning app development usually requires collaboration between multiple specialists, including ML engineers, backend developers, mobile developers, data engineers, MLOps teams, and UI/UX designers.
Applications involving computer vision, large language models, or advanced personalization systems generally require more specialized expertise and longer development timelines, which increases overall project cost.
MVP vs Enterprise Development Cost
The cost of machine learning app development depends largely on the complexity of the application, the ML features involved, and the infrastructure required.
A basic ML MVP with features such as recommendations or predictive analytics may cost between $20,000 and $60,000, while mid-level applications with custom models and real-time inference often range from $60,000 to $150,000.
Enterprise-grade ML platforms usually require advanced infrastructure, monitoring systems, security compliance, and large-scale inference handling, increasing costs to $150,000–$500,000 or more.
Generative AI applications are typically more expensive because they involve large language models, GPU-intensive infrastructure, and continuous inference workloads, often ranging from $80,000 to $300,000+, depending on scale and complexity.
Ongoing Maintenance and Operational Costs
Machine learning applications continue generating costs after deployment because models require ongoing monitoring, retraining, and infrastructure support. Over time, changing user behavior and data patterns can reduce model accuracy, making regular updates necessary.
Common operational expenses include GPU hosting, cloud inference infrastructure, API scaling, cloud storage, monitoring systems, retraining pipelines, and observability tools.
Many businesses also invest in MLOps workflows to manage model deployment, versioning, and performance tracking more efficiently as the application grows.
Cloud vs On-Device Deployment Costs
Deployment architecture also affects long-term expenses. Cloud-based systems offer greater computational flexibility but can become expensive as inference volume increases.
On-device AI can reduce cloud dependency by running lightweight models directly on smartphones, lowering inference costs and improving offline functionality. However, optimizing models for mobile devices may increase engineering effort during development.
Many businesses now use hybrid architectures where lightweight inference happens on-device while more compute-intensive processing runs in the cloud.
Why Cost Planning Matters Early
Machine learning projects often become expensive when infrastructure, retraining, and monitoring requirements are underestimated early in development. Building the model itself is only one part of the overall investment.
Businesses that plan infrastructure usage, operational costs, retraining cycles, and deployment requirements early are more likely to build ML applications that remain practical, maintainable, and cost-efficient as usage grows over time.
Challenges in Building ML Applications
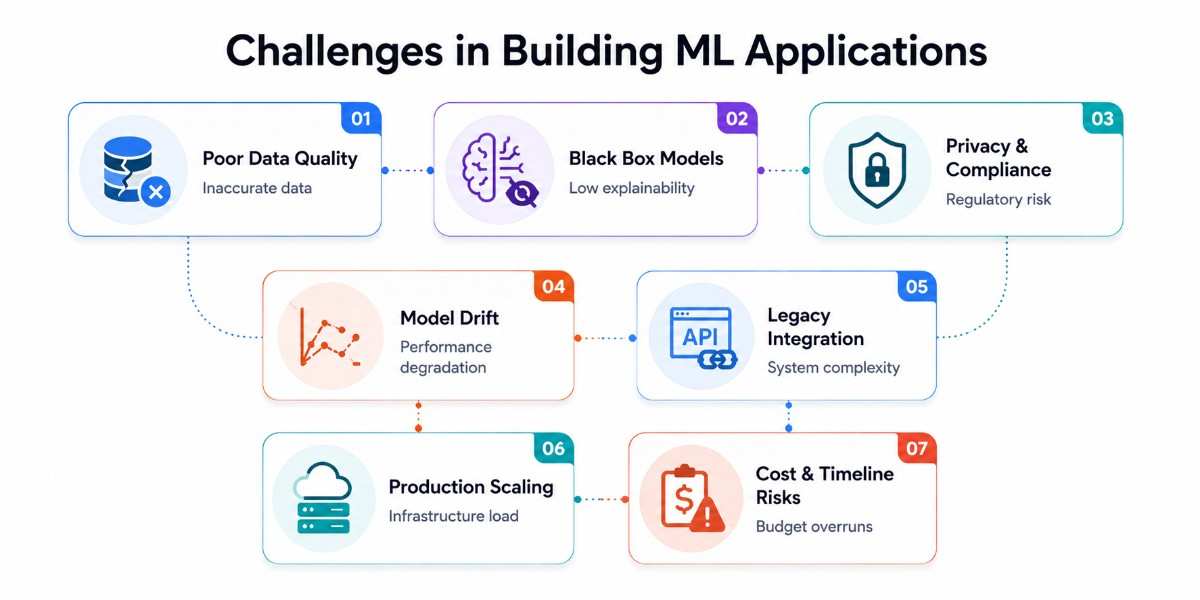
Gartner estimates 85% of ML projects never reach production. Understanding the most common failure modes before you start is one of the highest-leverage investments you can make. Here are the seven challenges that derail ML projects most often, and the concrete solutions.
1. Poor data quality and availability
This is mostly the main cause of ML project failure. Incomplete data, mislabeled examples, historical bias, and siloed databases all produce models that look good in testing but perform badly in production.
Conduct a data audit as Step 0, before any modeling. Establish data quality standards and automated validation pipelines. For sparse data, start with pre-trained models and fine-tune on your data rather than training from scratch. For missing labels, consider semi-supervised learning or active learning to reduce annotation cost.
2. Model interpretability, the "black box" problem
Modern deep learning models make predictions without explaining why. For regulated industries (healthcare, finance, lending), a model that cannot explain its decisions is often legally unusable. The EU AI Act (effective 2026) requires explainability for high-risk AI systems.
Adopt Explainable AI (XAI) tools: SHAP (SHapley Additive exPlanations) and LIME provide feature importance explanations for any model. For high-stakes applications, prefer interpretable models (decision trees, logistic regression) over black-box neural networks when prediction accuracy is comparable. Document model decisions for audit trails.
3. Privacy compliance and regulatory requirements
ML apps often process sensitive personal data at scale. GDPR (EU), CCPA (California), HIPAA (US healthcare), and India's DPDP Act 2023 all impose strict requirements on how personal data is collected, processed, stored, and deleted. Non-compliance fines under GDPR reach €20 million or 4% of global annual revenue.
Design privacy into your ML architecture from day one: use on-device inference for sensitive data, apply federated learning to avoid centralizing personal data, implement differential privacy for aggregate reporting, and establish data retention and deletion policies that apply to training data as well as user records.
4. Model drift and silent performance degradation
A model trained on 2024 data may perform poorly on 2026 user behavior. Seasonal patterns, shifting demographics, product changes, and external events (economic shifts, viral trends) all change the data distribution your model faces in production, without any code change triggering an error alert.
Implement monitoring for both data drift (input distribution changes) and concept drift (output distribution changes) using tools like Evidently AI or custom dashboards. Set automated alerts when key metrics fall below thresholds.
Establish a retraining cadence, quarterly as a minimum, real-time for high-stakes applications. Treat model monitoring with the same seriousness as server uptime monitoring.
5. Integration with existing systems
Most ML projects don't start greenfield; they need to integrate with legacy databases, existing APIs, and software architectures not designed with ML in mind. Data formats, latency requirements, and update frequencies often don't align with ML system needs.
Design a clean API boundary between your ML model and your application. Use the strangler fig pattern for legacy integrations, introduce ML alongside existing logic, then gradually transfer responsibilities. Invest in a feature store (Feast, Tecton) to make features available consistently across training and serving environments.
6. Scaling from prototype to production
A Jupyter notebook model and a production ML system are fundamentally different things. Models that perform well in controlled testing often fail at scale due to latency issues, resource constraints, versioning problems, and the absence of proper error handling.
Never deploy directly from a notebook. Use MLOps practices: containerize models (Docker), version control for both code and data (DVC), automated testing pipelines, staged rollouts (canary deployments), and rollback capabilities.
Invest in MLflow or similar tooling to track experiments and model versions from day one, not as an afterthought.
7. Underestimating cost and timeline
Most ML project overruns stem from underestimating data preparation time (typically 50–70% of total project effort) and over-scoping the initial model. Teams aim for a state-of-the-art model when an 80%-accurate simple model would have delivered 90% of the business value at 30% of the cost.
Start with the simplest model that could work. Establish a clear accuracy threshold that satisfies the business requirement, not a technical goal of "highest possible accuracy."
Use phased budgeting: allocate 30% for data preparation, 30% for model development, 20% for integration, and 20% for testing and deployment. Reserve 15–20% contingency for retraining.
ML App Development Trends in 2026 You Need to Know
The machine learning landscape in 2026 is defined by one overarching shift: ML is moving from experimental to foundational. These are the trends reshaping how ML apps are built, deployed, and monetized this year.
Agentic AI: ML Models That Take Action
Traditional ML models respond to a query and stop. Agentic AI systems plan, decide, and execute multi-step workflows autonomously. An agent doesn't just answer "what products should I reorder?"; it opens the procurement system, places the order, and confirms delivery.
The agentic AI market is projected to grow from $13.81 billion in 2025 to $140.80 billion by 2032 at a 39.3% CAGR. For app developers, this means building coordination layers between ML models and business systems.
On-Device / Edge ML as the Default
"The global edge computing market was estimated at $23.65 billion in 2024 and is expected to reach $327.79 billion by 2033 at a 33% CAGR (Grand View Research). Apple's Neural Engine and Qualcomm's NPUs now run sophisticated models locally in milliseconds.
The implications: privacy-first products become competitive advantages, not compliance burdens. Apps that process sensitive data on-device, health metrics, financial behavior, and location are differentiated from cloud-first competitors. Both iOS and Android now make on-device ML the path of least resistance for common ML tasks.
Federated Learning for Privacy-First Training
With GDPR, CCPA, and India's DPDP Act tightening data rules, federated learning has moved from academic research to production deployment. Models train across decentralized devices, each contributing model updates without sharing raw data.
Google uses it in Gboard, Apple in Siri improvements. For businesses in healthcare, finance, and HR tech, federated learning is now the architecture that makes large-scale ML legally viable in regulated environments.
Multimodal ML: Text, Image & Audio Together
2026's most capable ML models process multiple input types simultaneously, text, images, video, and audio in a single model. GPT-4o and Gemini set the template; now mid-size apps are embedding multimodal capabilities.
A customer service app can analyze a screenshot, the user's message, and their tone of voice simultaneously to route to the right agent. A field inspection app can analyze photos and voice notes together. Multimodal ML opens entire categories of apps that were impossible with single-modality models.
Foundation Models as App Infrastructure
By 2026, large language models will be increasingly treated as infrastructure, the way cloud computing replaced on-premise servers. Companies no longer need to train NLP models from scratch.
Instead, they fine-tune foundation models (LLaMA 3, Mistral, GPT-4) with domain-specific data using parameter-efficient fine-tuning (LoRA, QLoRA). This reduces time-to-market for AI features from months to weeks, and cost from six figures to four. The enterprise transition from building ML to orchestrating ML is well underway.
Explainable AI Driven by Regulation
The EU AI Act's main provisions, including requirements for high-risk AI systems such as credit scoring, medical diagnostics, and hiring algorithms, apply from August 2, 2026.
These mandate transparency, explainability, auditability, and human oversight. This regulatory pressure is turning Explainable AI (XAI) from a nice-to-have into a compliance requirement.
SHAP, LIME, and attention visualization tools are now standard components in production ML stacks for regulated industries. For apps targeting European or enterprise markets, XAI readiness is a sales advantage.
Real-Time ML with Streaming Data
Batch prediction (running a model on yesterday's data) is giving way to real-time streaming inference. Apache Kafka, Flink, and Ray enable ML predictions on live data streams, fraud detection that responds in 50ms, personalization that adapts mid-session, and predictive maintenance that alerts before a machine overheats.
For low-latency use cases in finance, gaming, advertising, and logistics, real-time ML has become a requirement rather than a premium feature. The tooling has matured enough to make it approachable for mid-size engineering teams.
Hyper-Personalization on the Device Edge
2026's mobile personalization goes far beyond "users see different banners." Apps now adapt layouts, navigation flows, notification timing, and content difficulty in real time based on context: location, time, activity (running vs sitting), and biometric signals from wearables.
Both Core ML and Android ML Kit support real-time context inference without server calls, personalization that is simultaneously faster, cheaper, and more private than cloud-based approaches. A wellness app that reads your heart rate and dims the interface when your stress spikes is now technically trivial to build.
Conclusion
Machine learning app development is becoming a core part of modern mobile and web applications across industries. Businesses are using ML to build more personalized, data-driven, and intelligent user experiences through features such as recommendation systems, fraud detection, predictive analytics, and generative AI.
However, successful ML applications require more than just integrating a model; they depend on quality data, the right infrastructure, efficient deployment, and continuous monitoring after launch. Businesses that focus on practical implementation and long-term system performance are more likely to build ML-powered applications that deliver measurable business value and better user experiences over time.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us