



How to Design a Multi-tenant Architecture for SaaS applications


Why Multi-Tenant Architecture Is the Foundation of SaaS
SaaS products are designed to simultaneously serve a variety of clients while keeping in mind that each client journey is unique and that any user data gathered must be kept private.
You would need to use a blueprint that fulfills this function in order to implement this in any application.
Development teams use a multi-serving architecture in these situations. This idea is not new to the market; any scalable SaaS software product has made use of the application's base or complex nature.
The goal is to run a shared system with strict data isolation while allowing all tenants to use the same application.
Your architecture becomes either your greatest strength or your greatest weakness as your product expands.
What is a Multi-Tenant Architecture
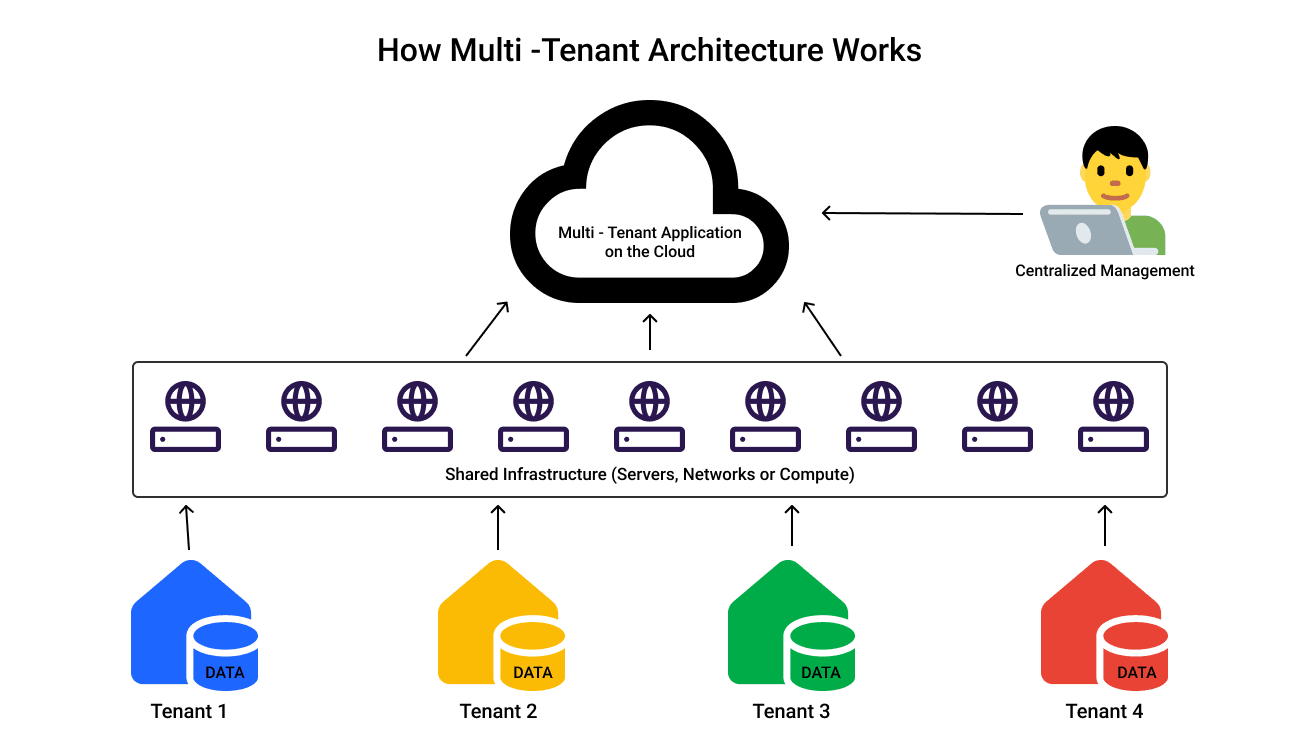
This design pattern enables a single application to serve several users (tenants) concurrently. Each tenant will use the same infrastructure as everyone else, but their data is logically segregated.
An apartment complex can be used as effective analogy here. Each apartment is private, but the building's plumbing, electricity, and structure are shared.
In a similar vein, SaaS shares infrastructure while protecting and isolating tenant data.
SaaS platforms can scale effectively with this model without having to duplicate infrastructure for each new client.
Core Principles of Multi-Tenant Architecture
The multi user architecture functions on a few foundational guidelines that enable a system to serve multiple tenants efficiently. We've mentioned a few notable core KPI's below:
Secure Data Separation with Tenant Isolation
Tenant isolation is a privacy compliance strategy used to map and store each tenant data separately. Implementing tenant isolation ensures that one tenant can never access another tenant’s data.
This strategy is enforced across multiple layers, including database queries, authentication mechanisms, and API-level access control.
Efficient Resource Utilization in Shared Infrastructure
Multi-tenant architecture relies on shared infrastructure to optimize the use of compute, memory, and storage resources.
Instead of allocating dedicated resources per tenant, resources are dynamically distributed based on demand.
This approach reduces infrastructure costs and improves overall system efficiency, making SaaS products economically viable especially during early growth stages.
Designing for Scalability in Multi-Tenant Systems
Scalability ensures that the system can support thousands of tenants without performance degradation.
As tenant count and data volume increase, the architecture must handle load efficiently without requiring major redesigns.
This is typically achieved through stateless services, horizontal scaling, load balancing, and efficient database strategies. A well-designed system scales predictably as demand grows.
Configuration-Driven Customization Without Code Complexity
Each tenant may require different features, workflows, or configurations. Instead of introducing tenant-specific logic into the codebase, modern systems handle customization through configuration.
This includes feature flags, tenant-specific settings, and metadata-driven behavior. Keeping customization outside the core logic prevents code bloat and ensures long-term maintainability.
What are the Three Architecture Models of Multi-Tenant?
The three architecture models of multi-tenant systems define how tenant data is stored and isolated within a shared application. These models impact scalability, security, and operational complexity.
They include shared schema, separate schemas, and separate databases. The right choice depends on tenant size, compliance needs, and cost constraints.
Shared Database, Shared Schema
This is the simplest and most common starting point. All tenants share the same database tables, and each row is tagged with a tenant identifier.
The application enforces isolation by filtering data using this tenant ID in every query. This approach is easy to implement and cost-efficient.
However, it relies heavily on correct query logic. A single mistake in filtering can expose data across tenants, making careful engineering and testing essential.
Shared Database, Separate Schemas
In this model, all tenants share the same database instance, but each tenant has its own schema. This provides stronger isolation compared to shared schema models.
Since each tenant’s data lives in a separate namespace, accidental cross-tenant access becomes less likely. However, managing schema migrations becomes more complex as the number of tenants grows.
This model strikes a balance between isolation and operational complexity.
Separate Database Per Tenant
Each tenant has its own dedicated database. This offers the highest level of isolation and is often required for enterprise customers with strict compliance requirements.
While this model improves security and flexibility, it increases infrastructure costs and operational overhead significantly. Managing backups, migrations, and scaling becomes more complex.
How to Choose the Right Multi-Tenant Architecture Model?
Selecting the right architecture model requires balancing scalability, cost, and data isolation based on your product stage and customer requirements.
A well-chosen model allows your system to grow efficiently without introducing unnecessary complexity or limiting future scalability.
Factors That Influence the Choice
Choosing the right architecture depends on multiple factors such as tenant size, compliance requirements, and cost constraints.
If your application serves thousands of small tenants, a shared schema model is often the most efficient. For mid-sized SaaS platforms with stricter isolation needs, separate schemas provide a better balance.
Enterprise applications with regulatory requirements like GDPR or HIPAA often require dedicated databases for each tenant.
When to Use Each Model
Shared schema works best for early-stage startups that need to move fast and minimize infrastructure costs. It allows rapid onboarding and simple deployment processes.
Separate schemas are suitable when you need stronger isolation without fully committing to the cost of separate databases.
Separate databases should be reserved for high-value tenants or when strict compliance and data residency requirements make shared infrastructure unsuitable.
Comparing all the Three Models
A practical strategy is to start with shared schema and gradually move high-value tenants to isolated resources as needed.
Tenant Identification and Routing in Multi-Tenant Systems
Before processing any request, the system must correctly identify which tenant the request belongs to. This step is critical because every operation, from data access to authorization, depends on tenant context.
Accurate tenant identification ensures that requests are routed correctly and prevents unintended data exposure across tenants.
Subdomain-Based Tenant Routing
In this approach, each tenant is assigned a unique subdomain. The system extracts tenant information directly from the request URL and routes it accordingly.
This method improves user experience and simplifies tenant resolution at the routing layer, making it a common choice for SaaS applications.
URL Path-Based Tenant Identification
Here, tenant context is included within the URL path. This approach is easier to implement and does not require DNS configuration.
However, it is less intuitive for users and requires consistent handling across all application routes to maintain clarity and correctness.
Token-Based Tenant Identification
Tenant information is embedded within authentication tokens, such as JWTs. Each request carries tenant context, which is validated by backend services.
This approach works well in distributed systems and microservices architectures, where services rely on token-based communication rather than URL structures.
Header-Based Tenant Identification
Tenant context is passed through custom request headers, typically in internal service communication.
While this method offers flexibility, it must be implemented carefully with proper validation to prevent spoofing and ensure secure request handling.
How Multi-Tenant Systems Ensure Secure Data Isolation?
Data isolation is the most critical aspect of any multi-tenant system. It ensures that each tenant’s data remains completely separate, even though all tenants share the same infrastructure.
Without strong isolation, a single bug or misconfiguration can expose sensitive data across tenants. A well-designed system enforces isolation at multiple layers, including the database, application logic, and access control mechanisms.
Relying on a single layer of protection is risky, so modern SaaS systems combine multiple strategies to ensure robust data separation.
Tenant ID Filtering
Tenant ID filtering is the most commonly used isolation technique in shared schema architectures. Every record in the database includes a tenant_id field, and all queries must filter data using this identifier.
This approach is simple and efficient, making it ideal for early-stage systems. However, it requires strict discipline in query design, as even a single missing filter can lead to data leakage.
To make this reliable, teams often enforce tenant filtering at the ORM or middleware level. This reduces the chances of human error and ensures consistent data access patterns.
Schema Isolation
Schema isolation separates tenant data at the database level by assigning each tenant a dedicated schema. This creates a logical boundary that prevents accidental cross-tenant access.
Compared to shared schema models, this approach significantly reduces risk because queries are scoped to a specific schema. Even if a query is incorrectly written, it cannot access data from another tenant.
However, managing multiple schemas introduces operational complexity. Schema migrations must be applied across all tenants, which requires careful orchestration and tooling.
Encryption and Access Control
Encryption ensures that sensitive data remains protected both in transit and at rest. Even if unauthorized access occurs, encrypted data cannot be easily interpreted.
Access control mechanisms further strengthen isolation by ensuring that users can only access resources within their tenant. This includes authentication, authorization, and role-based access control systems.
Together, encryption and access control form a strong security layer. They protect data not just from external threats, but also from internal misconfigurations or accidental exposure.
Tenant Identification and Routing
Before a request can be processed, the system must first determine which tenant is making that request. This step is critical because every piece of data access, authorization, and business logic depends on tenant context. Without correct identification, even a well-designed system can expose data across tenants.
Tenant identification is not just about mapping users to accounts. It is about ensuring that every request entering your system is correctly scoped and routed to the right tenant environment. A reliable routing strategy forms the foundation of secure and scalable multi-tenant systems.
Subdomain-Based Routing
Subdomain-based routing is one of the most commonly used approaches in SaaS applications. In this method, each tenant is assigned a unique subdomain, which directly maps to that tenant.
This approach improves both user experience and system clarity. Users immediately recognize their workspace, and the system can easily extract tenant information from the request URL.
From an architectural perspective, subdomains also simplify routing logic. Middleware or gateway layers can resolve tenant context early in the request lifecycle, making downstream services cleaner and more efficient.
URL Path-Based Routing
In URL path-based routing, the tenant is identified using a segment in the URL, such as /acme/dashboard. This approach is simpler to implement since it does not require DNS configuration or subdomain management.
However, it is less intuitive for end users and can feel less polished compared to subdomain-based approaches. It also requires consistent handling of route structures across the application.
Despite these limitations, it is often used in early-stage products or internal tools where simplicity is more important than branding or user experience.
Token-Based Identification
Token-based identification relies on embedding tenant information within authentication tokens such as JWTs. When a user logs in, the token includes metadata like tenant_id, which is validated on every request.
This approach is highly secure and works well in distributed systems and microservices architectures. Since tenant context travels with the request, services do not need to depend on URL structure.
It also reduces the chances of tampering, as tokens are signed and verified. This makes it a preferred approach for APIs and backend-heavy systems.
Header-Based Identification
Header-based identification uses custom request headers to pass tenant information, such as X-Tenant-ID. This is commonly used in internal service-to-service communication.
It allows flexibility in routing without relying on URLs or tokens, especially in controlled environments where services trust each other.
However, this approach must be handled carefully. Headers can be spoofed if not properly validated, so it is typically combined with authentication and network-level security.
Handling Tenant Configuration and Customization
Every tenant has unique needs, whether it is feature access, UI customization, or workflow differences. A scalable multi-tenant system must support these variations without introducing complexity into the codebase.
The key is to treat customization as configuration rather than logic. This allows the system to remain flexible while maintaining a clean and maintainable architecture.
Feature Flags
Feature flags allow enabling or disabling features for specific tenants without modifying the codebase. This makes it easy to roll out new functionality gradually or offer tier-based features.
They are especially useful for A/B testing and controlled rollouts. Teams can enable features for a small group of tenants before making them widely available. This approach reduces risk during deployments and provides better control over feature exposure across tenants.
Configuration-Driven Design
In a configuration-driven system, tenant-specific behavior is stored in configuration files or databases instead of being hardcoded.
This allows dynamic changes without redeploying the application. For example, pricing plans, limits, or UI preferences can be adjusted per tenant.
Over time, this approach keeps the system flexible and prevents the codebase from becoming cluttered with conditional logic.
Avoiding Tenant-Specific Code
Introducing tenant-specific conditions in the codebase leads to long-term maintenance problems. It creates complexity that grows with every new customization request.
Instead, all tenant differences should be handled through configuration or metadata. This ensures that the core application logic remains consistent across all tenants. A clean separation between logic and configuration is essential for building scalable SaaS systems.
Scalability in Multi-Tenant Architecture
Scalability in a multi-tenant system is not just about handling more users. It is about ensuring that the system continues to perform efficiently as tenants grow in number and size.
A scalable architecture distributes load intelligently, prevents bottlenecks, and ensures that no single tenant impacts the performance of others.
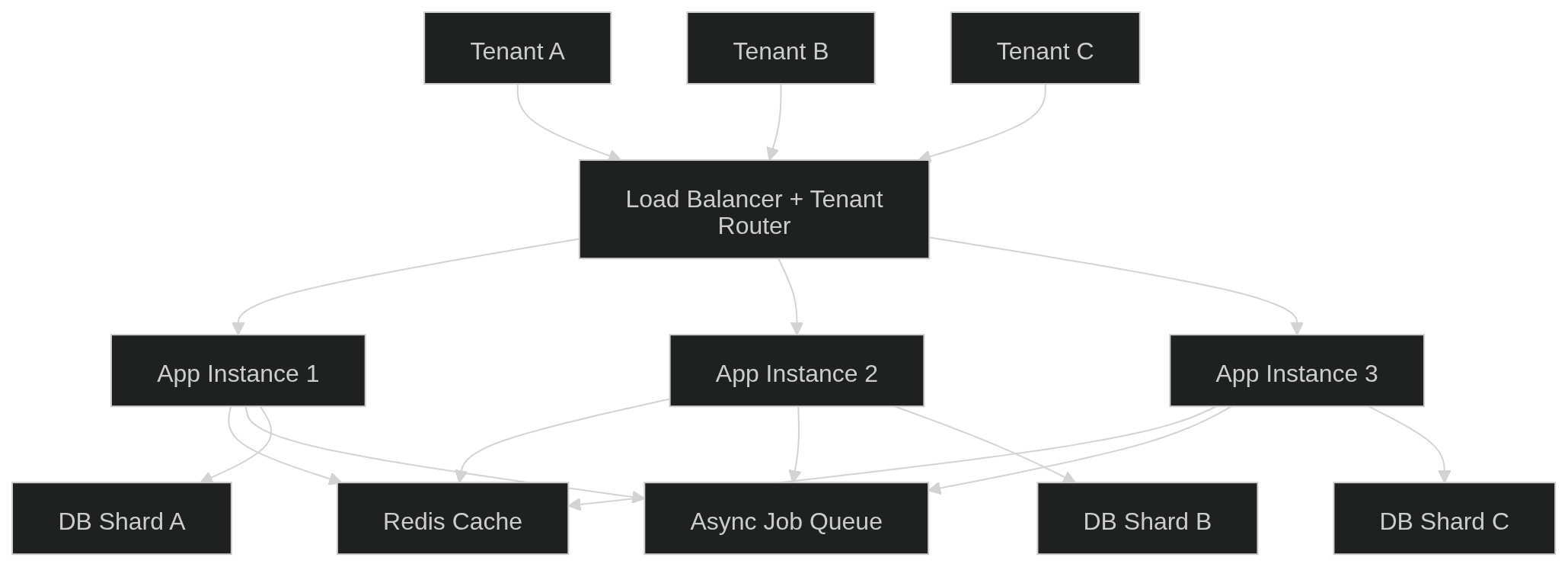
Horizontal Scaling
Horizontal scaling involves adding more application servers to handle increased traffic. These servers are typically stateless and sit behind a load balancer.
This approach allows the system to handle growth without changing the core architecture. As demand increases, more instances can be added dynamically.
It also improves fault tolerance, as traffic can be redistributed if one instance fails. These systems are often deployed as independently scalable services across multiple nodes.
Caching Strategies
Caching reduces the load on databases by storing frequently accessed data in memory. Systems like Redis are commonly used for caching tenant configurations and session data.
By reducing repeated database queries, caching significantly improves response times and system performance.
Effective caching strategies also help handle traffic spikes without overwhelming backend services.
Background Job Processing
Not all operations need to be processed in real time. Heavy tasks such as report generation, email sending, or bulk imports can be handled asynchronously.
Background job queues allow these tasks to run separately from the main application flow. This ensures that the API remains fast and responsive.
It also improves system reliability by isolating long-running processes from user-facing operations.
Database Sharding
As data grows, a single database can become a bottleneck. Sharding distributes data across multiple databases, often based on tenant identifiers.
This reduces load on individual databases and allows the system to scale horizontally at the data layer. This requires careful planning at the data modeling level to maintain consistency and query efficiency.
Sharding strategies can evolve over time.
Early systems may shard by tenant ID, while mature systems may use tenant size or region for better optimization.
Security in Multi-Tenant Architecture
Security in multi-tenant systems goes beyond protecting against external attacks. It also involves ensuring that tenants are isolated from each other at all times.
A strong security model combines authentication, authorization, monitoring, and rate limiting to create multiple layers of protection.
Tenant-Scoped Authentication
Every user session must be tied to a specific tenant context. Authentication systems should validate both the user identity and the tenant they belong to.
This ensures that even if credentials are compromised, access remains restricted within the tenant boundary. Tenant context should be consistently enforced across all services and APIs.
Role-Based Access Control
RBAC defines what actions a user can perform within a tenant. Permissions are scoped at the tenant level, ensuring that roles are isolated across tenants.
For example, an admin in one tenant should not have any privileges in another tenant.
A well-designed RBAC system improves both security and usability by clearly defining access boundaries.
Rate Limiting and Abuse Prevention
In a shared system, it is important to prevent any tenant from overwhelming the infrastructure.
Rate limiting enforces usage limits per tenant, ensuring fair resource distribution.
This protects the system from abuse, accidental overload, and denial-of-service scenarios while maintaining stability for all tenants.
Audit Logging
Audit logs record important actions like logins, data changes, and API usage. These logs include tenant context for better traceability.
They are essential for debugging, compliance, and detecting suspicious activity.
How to Monitor and Manage Multi-Tenant Systems?
Monitoring provides visibility into system health by tracking logs, metrics, and performance data. Without proper monitoring, detecting issues becomes difficult.
It enables faster debugging and helps teams make better operational decisions. A well-instrumented system captures tenant-level data across all services, this ensures issues can be traced accurately.
It improves reliability and makes the system easier to maintain as it scales.
Tenant-Level Observability
Observability involves collecting logs, metrics, and traces with tenant context. This ensures every request can be linked to a specific tenant.
It helps in quickly identifying and isolating issues.
It also provides insights into tenant behavior and usage patterns. This helps teams optimize performance and resource allocation.
Better observability leads to faster debugging and improved system efficiency.
Usage Tracking and Billing
Tracking tenant usage includes monitoring API calls, storage, and active users. This data is essential for understanding system usage.
It helps in making informed scaling decisions.
Accurate usage tracking ensures fair and transparent billing for each tenant. It also supports forecasting future infrastructure needs.
This helps maintain both cost efficiency and scalability.
Performance Monitoring
Performance monitoring focuses on identifying slow queries, latency issues, and bottlenecks. Continuous tracking helps detect problems early.
Load testing is used to evaluate system behavior under sustained traffic.This prevents performance degradation before it impacts users.
By analyzing performance data regularly, teams can optimize system efficiency. This ensures smooth operation even under heavy load.
It maintains a consistent and reliable experience for all tenants.
Tips to Build your Multi Tenant Architecture from Scratch
Building a robust multi-tenant system requires following proven design and implemeting principles. These practices help avoid common pitfalls and ensure long-term scalability.
Adopting these best practices early reduces technical debt and simplifies system evolution as the product grows.
Design for Multi-Tenancy from Day One
Retrofitting multi-tenancy into an existing system is extremely difficult and often leads to major rework. It introduces inconsistencies across different layers.
Designing with tenant awareness from the start ensures a clean and scalable architecture.
Building all components with tenant context early reduces technical debt. It keeps data access, APIs, and services aligned.
This makes the system easier to maintain and scale as the product grows.
Layer Your Isolation
Relying on a single layer of isolation, such as database filtering, is risky. A mistake in one layer can expose tenant data.
Using multiple layers reduces the chances of accidental data leakage.
Combining database, application logic, and API-level isolation provides stronger protection. Each layer acts as a safety net.
This defense-in-depth approach ensures better security in shared systems.
Automate Tenant Lifecycle
Tenant onboarding, configuration, and offboarding should be automated instead of handled manually. Manual steps often introduce errors.
Automation ensures consistency and reduces operational overhead.
Automated workflows make it easier to scale as the number of tenants increases. Each tenant follows the same standardized process.
This improves reliability and simplifies system management.
Instrument Everything
Every log, metric, and trace should include tenant context for proper observability. Without this, debugging becomes difficult.
Tenant-aware instrumentation helps quickly identify affected users.
It also provides better insights into system performance and usage patterns. Teams can monitor behavior at a granular level.
This improves both debugging speed and decision-making.
Plan for Future Scale
Systems should be designed with future growth in mind rather than current requirements. Early planning prevents major rewrites later.
It ensures the architecture can handle increasing tenants and data. Scaling strategies like sharding or isolation should be considered early.
This avoids bottlenecks as the system grows. Planning ahead makes scaling smoother and less disruptive.
Keep Customization in Configuration
Tenant-specific behavior should be handled through configuration instead of hardcoded logic. This keeps the system flexible.
It allows changes without modifying core application code.
A configuration-driven approach prevents code complexity from growing over time. It keeps the codebase clean and maintainable.
This makes it easier to support multiple tenants with different needs.
Summing Up
Multi-tenant architecture is the backbone of modern SaaS systems. It enables scalability, reduces costs, and simplifies operations while serving multiple customers from a single platform.
Choosing the right model and implementing strong isolation, scalability, and observability practices ensures that your system grows smoothly without becoming a bottleneck.
The goal is simple: build infrastructure that scales quietly in the background while your team focuses on delivering value to users.
 WhatsApp
WhatsApp Call Us
Call Us Mail Us
Mail Us